Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Multielectrode array wikipedia , lookup
Single-unit recording wikipedia , lookup
Haemodynamic response wikipedia , lookup
Neuropsychology wikipedia , lookup
Artificial general intelligence wikipedia , lookup
Brain Rules wikipedia , lookup
Activity-dependent plasticity wikipedia , lookup
Binding problem wikipedia , lookup
Environmental enrichment wikipedia , lookup
Neuroesthetics wikipedia , lookup
Cognitive neuroscience of music wikipedia , lookup
Premovement neuronal activity wikipedia , lookup
Clinical neurochemistry wikipedia , lookup
Cortical cooling wikipedia , lookup
Neural oscillation wikipedia , lookup
Embodied cognitive science wikipedia , lookup
Human brain wikipedia , lookup
Catastrophic interference wikipedia , lookup
Aging brain wikipedia , lookup
Eyeblink conditioning wikipedia , lookup
Neuroplasticity wikipedia , lookup
Artificial neural network wikipedia , lookup
Cognitive neuroscience wikipedia , lookup
Neural engineering wikipedia , lookup
Optogenetics wikipedia , lookup
Central pattern generator wikipedia , lookup
Holonomic brain theory wikipedia , lookup
Synaptic gating wikipedia , lookup
Channelrhodopsin wikipedia , lookup
Neuroeconomics wikipedia , lookup
Convolutional neural network wikipedia , lookup
Neuroanatomy wikipedia , lookup
Neural coding wikipedia , lookup
Neurophilosophy wikipedia , lookup
Neural correlates of consciousness wikipedia , lookup
Development of the nervous system wikipedia , lookup
Donald O. Hebb wikipedia , lookup
Neuropsychopharmacology wikipedia , lookup
Neural binding wikipedia , lookup
Feature detection (nervous system) wikipedia , lookup
Cerebral cortex wikipedia , lookup
Efficient coding hypothesis wikipedia , lookup
Metastability in the brain wikipedia , lookup
Types of artificial neural networks wikipedia , lookup
Nervous system network models wikipedia , lookup
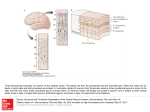
Sparse Neural Systems: The Ersatz Brain gets Thinner James A. Anderson Department of Cognitive and Linguistic Sciences Brown University Providence, Rhode Island [email protected] Speculation Alert! Rampant speculation follows. Biological Models The human brain is composed of on the order of 1010 neurons, connected together with at least 1014 neural connections. (Probably underestimates.) Biological neurons and their connections are extremely complex electrochemical structures. The more realistic the neuron approximation the smaller the network that can be modeled. There is good evidence that for cerebral cortex a bigger brain is a better brain. Projects that model neurons are of scientific interest. They are not large enough to model or simulate interesting cognition. Neural Networks. The most successful brain inspired models are neural networks. They are built from simple approximations of biological neurons: nonlinear integration of many weighted inputs. Throw out all the other biological detail. Neural Network Systems Units with these approximations can build systems that can be made large, can be analyzed, can be simulated, can display complex cognitive behavior. Neural networks have been used to model important aspects of human cognition. A Fully Connected Network Most neural nets assume full connectivity between layers. A fully connected neural net uses lots of connections! Sparse Connectivity The brain is sparsely connected. (Unlike most neural nets.) A neuron in cortex may have on the order of 100,000 synapses. There are more than 1010 neurons in the brain. Fractional connectivity is very low: 0.001%. Implications: • Connections are expensive biologically since they take up space, use energy, and are hard to wire up correctly. • Therefore, connections are valuable. • The pattern of connection is under tight control. • Short local connections are cheaper than long ones. Our approximation makes extensive use of local connections for computation. Sparse Coding Few active units represent an event. “In recent years a combination of experimental, computational, and theoretical studies have pointed to the existence of a common underlying principle involved in sensory information processing, namely that information is represented by a relatively small number of simultaneously active neurons out of a large population, commonly referred to as ‘sparse coding.’” Bruno Olshausen and David Field (2004 paper, p. 481). Advantages of Sparse Coding There are numerous advantages to sparse coding. Sparse coding provides •increased storage capacity in associative memories •is easy to work with computationally, We will make use of these properties. Sparse coding also •“makes structure in natural signals explicit” •is energy efficient. Best of all: It seems to exist! Higher levels (further from sensory inputs) show sparser coding than lower levels. Sparse Connectivity + Sparse Coding See if we can make a learning system that starts from the assumption of both •sparse connectivity and •sparse coding. If we use simple neural net units it doesn’t work so well. But if we use our Network of Networks approximation, it works better and makes some interesting predictions. The Simplest Connection The simplest sparse system has a single active unit connecting to a single active unit. If the potential connection does exist, simple outer-product Hebb learning can learn it easily. Not very interesting. Paths A useful notion in sparse systems is the idea of a path. A path connects a sparsely coded input unit with a sparsely coded output unit. Paths have strengths just as connections do. Strengths are based on the entire path, from input to output, which may involve intermediate connections. It is easy for Hebb synaptic learning to learn paths. Common Parts of a Path One of many problems. Suppose there is a common portion of a path for two single active unit associations, a with d (a>b>c>d) and e with f (e>b>c>f). We cannot weaken or strengthen the common part of the path (b>c) because it is used for multiple associations. Make Many, Many Paths! Some speculations: If independent paths are desirable an initial construction bias would be to make available as many potential paths as possible. In a fully connected system, adding more units than contained in the input and output layers would be redundant. They would add no additional processing power. Obviously not so in sparse systems! Fact: There is a huge expansion in number of units going from retina to thalamus to cortex. In V1, a million input fibers drive 200 million V1 neurons. Network of Networks Approximation Single units do not work so well in sparse systems. Let us our Network of Networks approximation and see if we can do better. Network of Networks: the basic computing units are not neurons, but small (104 neurons) attractor networks. Basic Network of Networks Architecture: • 2 Dimensional array of modules • Locally connected to neighbors The Ersatz Brain Approximation: The Network of Networks. Received wisdom has it that neurons are the basic computational units of the brain. The Ersatz Brain Project is based on a different assumption. The Network of Networks model was developed in collaboration with Jeff Sutton (Harvard Medical School, now NSBRI). Cerebral cortex contains intermediate level structure, between neurons and an entire cortical region. Examples of intermediate structure are cortical columns of various sizes (mini-, plain, and hyper) Intermediate level brain structures are hard to study experimentally because they require recording from many cells simultaneously. Cortical Columns: Minicolumns “The basic unit of cortical operation is the minicolumn … It contains of the order of 80-100 neurons except in the primate striate cortex, where the number is more than doubled. The minicolumn measures of the order of 40-50 m in transverse diameter, separated from adjacent minicolumns by vertical, cell-sparse zones … The minicolumn is produced by the iterative division of a small number of progenitor cells in the neuroepithelium.” (Mountcastle, p. 2) VB Mountcastle (2003). Introduction [to a special issue of Cerebral Cortex on columns]. Cerebral Cortex, 13, 2-4. Figure: Nissl stain of cortex in planum temporale. Columns: Functional Groupings of minicolumns seem to form the physiologically observed functional columns. Best known example is orientation columns in V1. They are significantly bigger than minicolumns, typically around 0.3-0.5 mm. Mountcastle’s summation: “Cortical columns are formed by the binding together of many minicolumns by common input and short range horizontal connections. … The number of minicolumns per column varies … between 50 and 80. Long range intracortical projections link columns with similar functional properties.” (p. 3) Cells in a column ~ (80)(100) = 8000 Interactions between Modules Modules [columns?] look a little like neural net units. But interactions between modules are vector not scalar! Gain greater path selectivity this way. Interactions between modules are described by state interaction matrices instead of simple scalar weights. Columns and Their Connections Columnar identity is maintained in both forward and backward projections “The anatomical column acts as a functionally tuned unit and point of information collation from laterally offset regions and feedback pathways.” (p. 12) “… feedback projections from extra-striate cortex target the clusters of neurons that provide feedforward projections to the same extra-striate site. … .” (p. 22). Lund, Angelucci and Bressloff (2003). Cerebral Cortex, 12, 15-24. Sparse Network of Networks Return to the simplest situation for layers: Modules a and b can display two orthogonal patterns, A and C on a and B and D on b. The same pathways can learn to associate A with B and C with D. Path selectivity can overcome the limitations of scalar systems. Paths are both upward and downward. Common Paths Revisted Consider the common path situation again. We want to associate patterns on two paths, a-b-c-d and e-bc-f with link b-c in common. Parts of the path are physically common but they can be functionally separated if they use different patterns. Pattern information propagating forwards and backwards can sharpen and strengthen specific paths without interfering with the strengths of other paths. Associative Learning along a Path Just stringing together simple associators works: For module b: Change in coupling term between a and b: Δ(Sab) = ηbaT Change in coupling term between c and b Δ(Tcb) = ηbcT For module c: Δ(coupling term Udc) = ηcdT Δ(coupling term Tbc) = ηcbT If pattern a is presented at layer 1 then: Pattern on d = (Ucd) (Tbc) (Sab) a = η3 dcT cbT baT a = (constant) d Module Assemblies Because information propagates backward and forward, closed loops are possible and likely. Tried before: Hebb cell assemblies were self exciting neural loops. Corresponded to cognitive entities: for example, concepts. Hebb’s cell assemblies are hard to make work because of the use of scalar interconnected units. But module assemblies can become a powerful feature of the sparse approach. We have more selective connections. See if we can integrate relatively dense local connections with relatively sparse projections to and from other layers to form module assemblies. Biological Evidence: Columnar Organization in IT Tanaka (2003) suggests a columnar organization of different response classes in primate inferotemporal cortex. There seems to be some internal structure in these regions: for example, spatial representation of orientation of the image in the column. IT Response Clusters: Imaging Tanaka (2003) used intrinsic visual imaging of cortex. Train video camera on exposed cortex, cell activity can be picked up. At least a factor of ten higher resolution than fMRI. Size of response is around the size of functional columns seen elsewhere: 300-400 microns. Columns: Inferotemporal Cortex Responses of a region of IT to complex images involve discrete columns. The response to a picture of a fire extinguisher shows how regions of activity are determined. Boundaries are where the activity falls by a half. Note: some spots are roughly equally spaced. Active IT Regions for a Complex Stimulus Note the large number of roughly equally distant spots (2 mm) for a familiar complex image. Intralayer Connections Intralayer connections are sufficiently dense so that active modules a little distance apart can become associatively linked. Recurrent collaterals of cortical pyramidal cells form relatively dense projections around a pyramidal cell. The extent of lateral spread of recurrent collaterals in cortex seems to be over a circle of roughly 3 mm diameter. If we assume that: •A column is roughly a third of a mm, •There are roughly 10 columns in a square mm. •A 3 mm diameter circle has an area of roughly 10 square mm, A column projects locally to about 100 other columns. Loops If the modules are simultaneously active the pairwise associations forming the loop abcda are learned. The path closes on itself. Consider a. After traversing the linked path a>b>c>d>a, the pattern arriving at a around the loop is a constant times the pattern on a. If the constant is positive there is the potential for positive feedback if the total loop gain is greater than one. Loops with Common Modules Loops can be kept separate even with common modules. If the b pattern is different in the two loops, there is no problem. The selectivity of links will keep activities separate. Activity from one loop will not spread into the other (unlike Hebb cell assemblies). If b is identical in the two loops b is ambiguous. There is no a priori reason to activate Loop 1, Loop 2, or both. Selective loop activation is still possible, though it requires additional assumptions to accomplish. Richly Connected Loops More complex connection patterns are possible. Richer interconnection patterns might have all connections learned. Ambiguous module b will receive input from d as well as a and c. A larger context would allow better loop disambiguation by increasing the coupling strength of modules. Working Together Putting in All Together: Sparse interlayer connections and dense intralayer connections work together. Once a coupled module assembly is formed, it can be linked to by other layers. Now becomes a dynamic, adaptive computational architecture that becomes both workable and interesting. Two Parts … Suppose we have two such assemblies that co-occur frequently. Parts of an object say … Make a Whole! As learning continues: Groups of module assemblies bind together through Hebb associative learning. The small assemblies can act as the “subsymbolic” substrate of cognition and the larger assemblies, symbols and concepts. Note the many new interconnections. Conclusion (1) • The binding process looks like compositionality. • The virtues of compositionality are well known. • It is a powerful and flexible way to build cognitive information processing systems. • Complex mental and cognitive objects can be built from previously constructed, statistically welldesigned pieces. Conclusion (2) • We are suggesting here a possible model for the dynamics and learning in a compositional-like system. • It is built based on constraints derived from connectivity, learning, and dynamics and not as a way to do optimal information processing. • Perhaps this property of cognitive systems is more like a splendid bug fix than a well chosen computational strategy. • Sparseness is an idea worth pursuing. • May be a way to organize and teach a cognitive computer.