Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Membrane potential wikipedia , lookup
Axon guidance wikipedia , lookup
Endocannabinoid system wikipedia , lookup
Theta model wikipedia , lookup
Apical dendrite wikipedia , lookup
Action potential wikipedia , lookup
Artificial general intelligence wikipedia , lookup
Neuromuscular junction wikipedia , lookup
Resting potential wikipedia , lookup
Neural engineering wikipedia , lookup
Clinical neurochemistry wikipedia , lookup
Holonomic brain theory wikipedia , lookup
Multielectrode array wikipedia , lookup
Artificial neural network wikipedia , lookup
Activity-dependent plasticity wikipedia , lookup
End-plate potential wikipedia , lookup
Neural modeling fields wikipedia , lookup
Caridoid escape reaction wikipedia , lookup
Mirror neuron wikipedia , lookup
Electrophysiology wikipedia , lookup
Catastrophic interference wikipedia , lookup
Neuroanatomy wikipedia , lookup
Synaptogenesis wikipedia , lookup
Circumventricular organs wikipedia , lookup
Single-unit recording wikipedia , lookup
Neurotransmitter wikipedia , lookup
Neural oscillation wikipedia , lookup
Neural coding wikipedia , lookup
Feature detection (nervous system) wikipedia , lookup
Development of the nervous system wikipedia , lookup
Premovement neuronal activity wikipedia , lookup
Nonsynaptic plasticity wikipedia , lookup
Molecular neuroscience wikipedia , lookup
Stimulus (physiology) wikipedia , lookup
Optogenetics wikipedia , lookup
Central pattern generator wikipedia , lookup
Metastability in the brain wikipedia , lookup
Convolutional neural network wikipedia , lookup
Neuropsychopharmacology wikipedia , lookup
Chemical synapse wikipedia , lookup
Recurrent neural network wikipedia , lookup
Pre-Bötzinger complex wikipedia , lookup
Channelrhodopsin wikipedia , lookup
Biological neuron model wikipedia , lookup
Types of artificial neural networks wikipedia , lookup
Extended Liquid Computing in
Networks of Spiking Neurons
Supervisor
Dr. Gordon Pipa
Intern
Robin Cao
Max Planck Institute for Brain Research
Department of Neurophysiology
Deutschordenstraße 46
D-60528 Frankfurt/Main
Extended Liquid Computing in Networks of
Spiking Neurons
Year 2009-2010
Contents
1 Frameworks for Neural Computation
1.1 Models of Spiking Neurons . . . . . .
1.2 Neural Networks . . . . . . . . . . .
1.3 Machine Learning . . . . . . . . . . .
1.4 Reservoir Computing . . . . . . . . .
.
.
.
.
3
3
4
5
6
2 Liquid State Machine
2.1 Definitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.2 Features . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.3 Readout Training Procedure . . . . . . . . . . . . . . . . . . . . . . . . .
8
8
9
10
3 Extended Liquid Computing
3.1 Construction of the Liquid State Machine
3.2 Mackey-Glass System . . . . . . . . . . . .
3.3 Reservoir/Mackey-Glass coupling . . . . .
3.4 Details on the Implementation . . . . . . .
.
.
.
.
11
11
12
12
14
4 Simulations and Measures
4.1 Computations at the edge of chaos . . . . . . . . . . . . . . . . . . . . .
4.2 Quantifying the Separation Property . . . . . . . . . . . . . . . . . . . .
16
16
17
A Physiological Complements
20
B Illustrations for Izhikevich model
23
C Spike trains: From order to ”chaos”
24
D Separation Property Plots
25
E Complements on the balanced synaptic activity
26
1
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Abstract
The idea of using biologically-based neural networks to perform computation
has been widely used over the last decades. The main idea being that the information a neuron can integrate and process can be revealed by its spiking activity.
Using a mathematical model descrbing the dynamics of a single neuron (microscopic scale), one can then construct a network in which the spiking activity of
every single neuron will get modulations from the spiking activity of the embedded
network (mesoscopic scale).
In this project, we plan to modulate the spiking activity of the network using a
coupling with an external dynamical system that would represent the activity of
a large assembly of neurons (macroscopic scale), in order to improve its computational features.
In the first place, we will explain the main concepts that are required in the context of neural computation, from the modeling of single-neurons to the construction
of specific structures of interacting neurons that can ’learn’. Then we will present
the concept of Liquid Computing, or Reservoir Computing, a novel approach for
computations on neural networks.
In the two last parts of the document, we will expose the way we establish the coupling between our network and an external dynamical system, and the tool we used
to analyze the dynamics of the system and evaluate its computational abilities.
2
1
Frameworks for Neural Computation
1.1
Models of Spiking Neurons
The Hodgkin-Huxley Model (1952)
We expose here the very first mathematical model for the dynamics of action potentials
fired by a single neuron. It has been introduced by Hodgkin and Huxley (H&H) in
1952 and awarded by the Nobel Prize in Physiology or Medecine in 1963. The idea
behind the model is based on ionic conductances through the membrane and can therefore
be described by a simple equivalent electrical circuit (see appendix A for physiological
complements).
With the conservation of the electric charge, we have:
C dV
= −F + Is + I
dt
C is the cell capacitance, F the membrane current, Is the sum of external synaptic currents
entering the cell. I describes any external applied current. The membrane current F
arises mainly though the conduction of sodium and potassium ions though voltage-gated
channels, it is considered to be a function of V and of three time and voltage dependent
conductance variables we note m, n and h:
F = gL (V − VL ) + gK (V − VK )n4 + gN a (V − VN a )hm3
Where labelled potential are Nernst reversal potential associated with the leakage, potassium and sodium channel. Conductances ’g’ are constants and the variables n, h and
m are time-dependent functions controlling the dynamics of the ions channels. In the
end, the H&H model consists of 4 non-linear coupled equations that can reproduce the
20 different kind of spiking activity that have been observed on real neurons.
The Izhikevich Model (2003)
The H&H model being of an extreme accuracy from a biological point of view, but extremely demanding from a numerical point of view, numerous simplified models have been
thereafter introduced in order to allow computations to be performed on large populations
of interacting neurons. The Izhikevich model is the most recent one and offers a good
compromise between biological observations and computational power, as it essentially
consists of a two-dimensional reduction of the H&H model: v the membrane potential,
u a recovery variable that contains the dynamics of ions-channels, I external inputs
to the neuron membrane.
(
v 0 = 0.04v 2 + 5v + 140 − u + I (∗)
after-spike reset
u0 = a(bv − u)
3
(
v→c
if v ≥ 30mV
u→u+d
The parameters in (∗) are obtained by fitting with the dynamics of a real cortical
neuron is such manner that the membrane potential v has amplitude of scale mV and
time has ms scale. Parameters a and b respectively control the recovery time of variable
u and its coupling to the membrane potential; typical values are a = 0.02 and b = 0.2.
Smaller values for a induce a longer refractory period, i.e. the minimal time before any
other spike can be triggered; increasing the coupling between u and v induces in a greater
sensitivity of ions channels to fluctuations of the membrane potential, which can lower
the firing threshold.
Parameters c and d control the after-spike resets This model has been successfully able to
reproduce any of the 20 different spiking dynamics of single neurons for different values
of a, b, c and d.
Moreover, this model is as computationally tractable as a simple integrate-and-fire neuron
model, which fully justifies using it in large networks of interacting neurons.
1.2
Neural Networks
Based on the hypothesis that the spiking activity of a single neuron is the key element of information processing within the brain, artificial neural networks have been
introduced in order to simulate and understand larger neural structures. They essentially consist of a population of non-linear nodes modeling biological neurons, exchanging
spikes to each others via weighted connections, reflecting the way real-neurons project
to others and interact through synapses. Thus, the information processed by each single
neuron is modulated by the activity of the embedded network, which, because of its highdimensionality and the intrinsic non-linearity of its elements can exhibit various types of
collective behaviours.
Moreover, these structures can learn how to perform a specific task a constituting a significant part of the topics in artificial intelligence.
Feed-forward Neural Networks:
• Feed-forward neural networks (FNNs) are the earliest artificial networks of spiking
neurons that have been introduced. They are composed of several layers of neurons (input layer, output layer and hidden-layer(s)) and process the information
forward in only one direction from one layer to another at every time step as shown
in Figure 1.
• From a mathematical point of view, FNNs are static input-output maps: activation
goes from layer to layer and the system does not have a dynamic internal state.
• From a biological point of view, there are at the moment no evidences of the existence of feed-forward structures within neuronal assemblies.
Recurrent Neural Networks:
• Recurrent neural networks (RNNs) show at least one cyclic path of synaptic connections. Therefore, at one given time t, the activation of a given neuron within
this loop not only depends on the activation of neurons projecting into it at time
t − 1, but also on the activity of the network at time t − 2. Because of the recurrent
4
structure, neurons can expect their activation at time t to be influenced by the
network activity up to about t − T if it takes T steps to cover the cyclic path (see
Figure 1).
• Contrary to FNNs, RNNs are dynamical systems. Their structure provides them
with a dynamical internal state with internal memory, as the activation of neurons
is sent back in the network and depends on more than only previous fed, making
RNNs more suitable to deal with time-depending inputs.
• RNNs represent also a more plausible approach for biologically-based computational
models as all real neural networks so far presented recurrent connections. In the
following we will no longer consider FNNs.
Figure 1: Schematic structure of FNNs and RNNs
1.3
Machine Learning
The fact that RNNs are capable of learning relies on the fact that they could theoretically approximate any dynamical system with arbitrary precision, the universal approximation property. The high-dimensionality conferred to these objects by a large number
of processing elements give them the ability to store bits of information in their stable
states (attractors in the language of dynamical systems).
As shown in Figure 2, the global scheme for machine learning is simple: the neural network, which is a functionnal (or filter) of the input function u(·), generates an output
y(t) = (Fnet u)(t) that is compared to a target output generated by another filter with
y0 (t) = (Ftarget u)(t) at every timestep. The training procedure then consists in adapting
all the synaptic weights of the network so that its output fits the target output with a
given precision. This way, after a sufficiently long training, the filter Fnet should be
able to reproduce output of the filter Ftarget , ideally for other inputs different from the
training input.
The training procedure consists of finding the set of synaptic weights Wij connecting
neurons to each others (of size N × N , where N the number of units in the network) that
minimizes the summed squared error:
E=
X
|y0 (t) − y(t)|2
t=1,...,T
5
Target Filter
Ftarget
Output z(t)
Fnet
Output y(t)
Training
Input u(·)
Neural Network
Figure 2: Simple overview of a machine learning method
Many algorithms have been developed over the years, but we will not give more details
about them (see [4]). Indeed, computations on attractors networks like RNNs show a
certain number of limitations. First, a great number of attractor, i.e. a system of very
high-dimensionality is needed to store information. Second, providing that the system
actually converges to a stable attractor state, the convergence time does not allow to
carry out computations in real-time on inputs that are varying on smaller time-scales
than the convergence time. Finally, simultaneous computations are not possible since all
the synaptic weights are updated at every timestep for one specific task.
1.4
Reservoir Computing
A novel approach on computation that has been developed lately (see [2], [6], [8]) and
that can cope with real-time computations on RNNs without the constraint of reaching
stable states is called reservoir computing or liquid computing. One can use the latter
expression to describe intuitively the motivations behind this new framework. Let us
imagine that we can use a liquid (e.g a glass of water) to perform computation; from
the perspective of attractor dynamical systems, this does not make much sense, since the
only stable state to which the liquid can converge after a perturbation (e.g a drop in the
liquid) is a ”dead” state where it is perfectly still. The idea of reservoir computing is that
the transient states of the liquid at given time still holds relevant information about
a perturbation that occurred at previous time. Providing that the liquid has the ability
to produce significantly different transient states under two different inputs, it is then
theoretically possible to extract information directly from measures on the state of the
liquid since it is supposed to hold informations about the past (e.g. successive pictures
of the perturbed glass of water).
In the context of computational on RNNs, this framework seems particularly wellsuited, which can be explained just by describing Figure 3:
• One can use the spiking activity of reservoir neurons as the internal liquid state
• The possibly great number of time-scales for interactions between neurons, provided
by the existence of cyclic paths of variable sizes, can provide the internal memory
required
6
”Reservoir” of Neurons
Readouts
Figure 3: Structure of a RNN in the framework of reservoir
computing ; only dotted synaptic connectivities are trained.
• Only the incoming synaptic connectivities to the readouts are trained, meaning that
of the reservoir does not need to converge to a stable state (even though it could)
and it has been shown that readout neurons are able to map the high-dimensional
out-of-equilibrium dynamics of the system into stable outputs.
7
2
Liquid State Machine
Two different approaches using the idea of a dynamic recurrent reservoir of processing
units left in a transient state, while only the output layer (readout) is subject to a supervised learning have been introduced independently in the last decade. One, introduced
by Jaeger et al. considers a population of analog neurons, i.e. neurons with the same
activation function, most often a sigmoid mapping incoming activation to a neuron into
the activation of this neuron. This is referred as Echo State Networks (ESN). The
other approach (Maass et al.) considers reservoirs of spiking neurons, i.e. neuron models
whose activity is described by a set of dynamic differential equations rather than a static
input-output function. These models are referred as Liquid State Machine (LSM)
models and we will only consider this approach in the following.
2.1
Definitions
As it has been previously mentioned, a LSM consists of a reservoir of interacting
spiking neurons showing recurrent topology (RNN), that maps inputs into a dynamical
state (liquid state) which is then read out by a spiking neuron receiving inputs from the
reservoir and mapping its activation into an output via the readout function. The output
is then compared to a target output in the training procedure and incoming synaptic
weights of the readout neuron adapted to fit the target at best.
Liquid LM [·]
Input u(·)
{
u1
...
...
uk
Liquid State
...
(LM u)(t)
xM (t)
Readout(s)
y(t) = f M (xM (t))
...
Figure 4: Functional scheme of a LSM
Formally, the liquid of neurons is a mapping from time-dependent inputs u(·) =
{ui (·)}i∈(1,...,k) lying in a subset U k of (RR )k onto a n-dimensional dynamical liquid state
x(t) in (RR )n :
LM : U k −→ (RR )n
u 7−→ x(t)
The second operation one needs to define is the readout function, mapping the liquid
state into an output at every time t:
f M : (RR )n −→ RR
x(t) 7−→ y(t)
8
All-in-all, the liquid state machine is an operator, mapping time-varying functions onto
one or many functions of time. Readout maps are generally chosen memory-less because
the liquid state x(t) should contain all the information about past inputs u(s), with s ≤ t,
that is required to construct the output y(t). Therefore, the readout function f M at time
t does not have to map previous liquid state x(s).
2.2
Features
When a LSM exhibits some specific properties we describe in this section, mathematical results that can be found in reference [8] can ensure the system a theoretically
universal computational power, meaning that it could learn to mimic any filter with
arbitrary precision.
Point-Wise Separation Property
The really innovative idea in the LSM approach is to consider the learning process of the
system from the point of view of a readout function. Thus, if a liquid of neurons is to
be useful for performing computations, the readout function has to be able to classify
inputs, i.e. respond differently to different inputs. Clearly, a readout can only produce
different outputs from different liquid states, meaning that in oder to perform computations, the liquid has to be able to feed the readout with separated enough liquid states.
In other words, the LSM has to show a good separation property and map different
input streams into significantly different trajectories in the space of the internal states of
the liquid.
Formally, a class CF of filters satisfies the point-wise separation property (with respect
to some set of input functions U k ) if for any couple of time-varying input (u(·), v(·)) ∈
U k ×U k with u(s) 6= v(s) for s ≤ t, then there exists F ∈ CF such that (F u)(t) 6= (F v)(t).
Approximation Property
On the other hand, the approximation property denotes the ability of the readout function
to transform the liquid states into the target output. It depends mostly on the capability
of the readout to reproduce a task, i.e. to get as close as possible from the target output
(teacher), so that as in Figure 2, the ensemble ”reservoir-readout” represented by the
filter Fnet will mimic the filter Ftarget
It simply reads as follows: a class Cf of functions satisfies the approximation property
with respect to a continuous function h if there exists f ∈ Cf for which |h(x) − f (x)| ≤ with an arbitrary small > 0.
Universal Computational power
If these properties are fulfilled for both the liquid and the readout mapping of a LSM,
a mathematical theorem (see [7],[8]) guarantees that LSMs can approximate any filter
with fading memory and time-invariance with arbitrary precision. The time-invariance
restricts the computational abilities of LSMs to filters that are input-driven, i.e. with no
sustained activity in the absence of stimuli, for which a temporal shift of value t0 on the
input will shift the output by t0 .
The fading-memory on a filter F states that there exist a finite time-interval [−T, 0] and
two real (small) numbers , 0 > 0, so that if input u(·) can be approximated by input v(·)
with precision , i.e. |u(t) − v(t) < | for t in the aforementioned interval, then the out9
put of u(·), (F u)(0), can be approximated by (F v)(0) with accuracy 0 . In other words,
approximating the output value at time t = 0 (F u)(0) does not necessarily requires to
know the input u(·) for more than a finite step back in the past.
The fading-memory is an important feature of a liquid, as it is what theoretically
allows a readout to deduce, from the liquid state x(t), informations about the input at
previous times u(t − 1), . . . , u(t − T ).
2.3
Readout Training Procedure
The output layer of the reservoir, mapping the liquid state into an output consists
of a set of neurons connected to the reservoir. As mentioned previously, only synaptic
weights from the reservoir to the output layer will be subject to the training procedure,
which essentially adapts the weights to approximate the target output at best, using a
simple linear regression. In theory, the readout function f M could be anything. In practice, one usually uses a layer of neurons identical to neurons of the reservoir that will
adapt its connectivities with the reservoir using a simple linear regression (linear perceptrons). Indeed, the probability for a linear readout to separate two classes of inputs
increases with the dimensionality of the state space of the liquid as stated in reference [1].
Liquid states x(t0 ), x(t1 ), . . . , x(tT ) at different times are concatenated into a N × T
matrix X̂, with N the number of neurons in the reservoir, T number of iterations in the
training period, and the output is given by y(t) = Wr · X̂, with Wr the set of weights
connecting the readout to the reservoir. Given a teacher output z(t), one needs to find
the optimal set of weights Wopt satisfying:
Wopt = minWr ||Wr · X̂ − z||2
†
This can be achieved by calculating the Moore-Penrose pseudo-inverse X̂ of matrix X̂, a
generalization of matrix inversion to non-squared matrices, equivalent to the linear least†
square solution of this problem, so that Wopt ≈ X̂ · z. One then does the substitution
Wr −→ Wopt , the final step being to test if the system can generalize its learning to novel
inputs by measuring the error between the target output ztest produced by this novel
test-input to the trained liquid output Wopt · X̂.
10
3
Extended Liquid Computing
3.1
Construction of the Liquid State Machine
As explained previously, a LSM consists of a recurrent network of spiking neurons. In
our case, the spiking activity of the neurons is given by Izhikevich set of equations.
Topology of the Network
The network is constructed as follows. We consider an assembly of N = NE + NI
neurons, where the subscripts respectively stand for ”excitatory” and ”inhibitory”, with
NI = 0.25 · NE as suggested by the anatomy of a mammalian cortex. The number of
postsynaptic connections Nc for every neuron is chosen as a fraction of the total number
of neurons N , and links between neurons (we will refer later as the connectivity matrix
W = {wij }i,j∈[1,...,N ] ) are constructed randomly:
• Excitatory neurons can project to any other neuron of the reservoir, but inhibitory
neurons only projects to excitatory neurons, since no experimental evidences of
recurrent circuits in inhibitory neural assemblies have been found yet; they are also
called ’interneurons’ because they mostly link excitatory neurons together.
• Even though there are no coordinates associated to neurons, a certain notion of
”spatial” distance is encoded by using temporal delays between connected neurons,
meaning that a neuron j will receive the action potential fired by neuron i after a
certain delay τij that represents axonal propagation.
• Background noise Iext is also added to maintain spiking activity within the liquid
of neurons and consists of a set of random spike trains with given firing rate.
Dynamic of the Network
The spiking dynamics of the LSM is reflected by the dynamics of binary liquid states
x(t) ∈ [0; 1]N , where the i-th component of the liquid state xi (t) is equal to 1 if neuron
i fires a spike at time t, 0 otherwise. One can thus write, for i ∈ [1, . . . , N ], using the
Heaviside step-function Θ:
xi (t + 1) = Θ[vi (t) − 30]
Here vi is the variable describing the membrane potential of neuron i, which for sure
delivers an action potential when going over the 30mV threshold. The dynamics of any
neuron i is given by Izhikevich’s model with input current given by a simple linear summation of incoming synaptic activity and an external background noise Ii,ext . Parameters
a and b are set up so that excitatory neurons show regular spiking activity and inhibitory
neurons show fast-spiking activity, which is typical in mammalians cortex (see appendix
B).
vi0 = 0.04vi2 + 5vi + 140 − ui + Ii
u0i = a(bvi − ui )
. P
Ii =
j wij · xj (t − τij ) + Ii,ext (t)
11
In the following we present the first developments in an attempt to extend the classical
framework of reservoir computing. The idea is to establish a bilateral coupling between
the reservoir and an external signal representing the activity of a mass of neurons on
a much larger scale, based on the hypothesis that this external input can extend the
computational capabilities of the system, in particular extend its fading-memory by the
exchange of dynamical features.
3.2
Mackey-Glass System
We chose to couple our LSM with a dynamical system called the Mackey-Glass (MG)
equation. This choice is motivated by the fact that Appeltant et al. ([1]) showed that
it is possible to reproduce the performance of a reservoir of neurons using a single node
governed by a Mackey-Glass equation, which writes:
X(t − τ )
dX(t)
=b
− a X(t)
dt
1 + X n (t − τ )
It is a delayed differential equation with delay parameter τ , meaning that the evolution
of the variable X is dependent of its past value at time t − τ . The parameters a and b
control whether the signal will tend to damp down (a > b) or to show sustained activity
(a < b), and the parameter n controls the degree of non linearity of the system.
More informations on the dynamics of the equation can be found in [9].
3.3
Reservoir/Mackey-Glass coupling
LSM as a perturbation of the Mackey-Glass signal
We establish the coupling from the liquid states to the Mackey-Glass signal by considering
that the MG signal represents somehow the macroscopic activity of a mass of neurons,
and that this mass activity receives perturbations from the LSM. The perturbation is
defined as follows:
. X
k(t) = {αi x̃i (t) + βi x̃i (t)2 }
i
The variable x̃i is the continuous equivalent of the binary spiking activity xi , for instance
the convolution of the spike train by a decreasing exponential kernel.
x̃i(t)
xi(t)
4
Neuron Index
Neuron Index
4
3
2
1
3
2
1
Time
Time
From a ”statistical learning theory” point of view based on how networks of neurons
encode and propagate bits of information, only the knowledge of whether neurons spike
or not (1 or 0) matters. In this case the coupling is more of an electro-physiological
12
nature, meaning that the membrane potential of neurons could contribute at any time
in perturbing the MG equation. Therefore, to every neuron i is associated a continuous
spiking activity x̃i (t) with characteristic decay time τD and x̃i (t)2 with decay time τD /2
contributing to variable k with weights αi and βi chosen from a zero-centered normal
distribution.
The quantity k now needs to be injected in the MG system. One could see k(t) as
an external drive we should just add to the r.h.s of the MG equation, but based on the
physiological assumption that neurons of the reservoir project massively into the neural
mass, we chose to perform the perturbation directly on the variable X, which was a
posteriori encouraged by a similar perturbation process used in reference [1].
X −→ X + k
The idea behind such a perturbation scheme being to shift the Mackey-Glass system from
its orbit consistently with the activity of the system.
MG as input to the reservoir
To complete the coupling one has then to feed the reservoir back with the signal produced by the Mackey-Glass system, i.e. establish a mapping from a one-dimensional
system into a N -dimensional vector (liquid state of N neurons). This can be achieved
using distributed delays [ξ1 , . . . , ξN ] as shown in fig (...). At time t neurons [1, . . . , N ]
would receive input with respect to the value of the MG signal at previous times t −
ξ1 , . . . , t − ξi , . . . , t − ξN .
The idea behind such a mapping is not only a trick
to reconstruct the high-dimensionality of the liquid state. First of all, it is really important that
neurons do not all get the same input at the same
time, which would have for consequence to synchronize them to the MG signal and therefore break
the critical dynamics of the reservoir. Also, we recall that the MG equation is a delayed differential
equation, whose evolution is dependent of its past
values. Therefore we distribute the delays so that
neurons look into the past of the MG signal within
the window [t − τ, t] where τ is the delay of the MG
equation, so that the liquid state can reconstruct its
history.
t − ξi
t − ξj
t
..
.
Liquid state x(t)
with associated inputs
xi(t)
..
.
xj (t)
..
.
To assign feedback delays, we use a gamma distribution Γ(k, θ). k is the shape parameter we keep fixed, and θ the scale parameter we set so that the distribution of delays
covers the window [t − τ, t]. In order to have most of the delays in this window we give
the following condition: the tail of the gamma distribution were only a few values stand
should be around the value of the delay of the MG equation τ . Using the mean value
µ(k, θ) and standard deviation σ(k, θ) of our gamma distribution we arbitrary set the
position of the tail as shifted from µ(k, θ) by n0 · σ(k, θ), were n0 is equal to one if the
13
distribution is symmetric, or bigger in the case of an asymmetric distribution were the
tail shifts to the right. We then evaluate θ with the relation:
τ ≈ µ(k, θ) +√
n0 · σ(k, θ)
≈ kθ + n0 θ k
τ
√
=⇒ θ ≈
k + n0 k
The MG signal is then injected into the neurons via the input current term in Izhikevich’s set of equations:
Ii =
X
wij · xj (t − τij ) + Ii,ext (t) + Ii,M G (t)
j
The term Ii,M G (t) can be defined in different ways according to the dynamics of the MG
signal, but the principal idea is to construct an input current that will present a balance
between excitation and inhibition, i.e. positive and negative drive. Using exclusively
positive drive to the neurons tend to saturate the network, forcing it to synchronize,
whereas exclusively inhibitory drive would shut down the spiking activity.
We used the following expression:
Ii,M G (t) ∝ ±X(t − ξi )
The proportionality factor is set up so that the input Ii,M G stays of the order of the
synaptic strengths so that it does not saturates the LSM, and the sign of the input is
randomly picked up for every neuron to create the balance between excitation/inhibition
we feed the network with.
3.4
Details on the Implementation
Relation between time-scales in both systems
In the liquid of neurons, the elementary time-step is fixed by the characteristic time-step
of the spiking activity of the neurons. As Izhikevich’s set of equation is tuned so to
produce signals in the scale of one millisecond we chose the time between two updates of
the network to be 1ms.
On the other hand, there is no restrictions on the time-scale in the dynamics of the
MG equation. We then need to connect the time-steps of both systems (time between
updates for the LSM, time-step of the numerical solver for the MG equation). Note that
the MG system gets input from the LSM at every update of the network, meaning that
the MG signal has to be solved at least every millisecond. Plus, the original idea behind
the coupling being to use the MG system as a time-scale bath containing a wider range
of characteristic time constants he can exchange with the LSM, we need to consider the
possibility that this signal could contain dynamical features under the millisecond scale,
and we set the step between two numerical approximation of the solution (standard
Runge-Kutta scheme) to be a fraction of a millisecond. This way, we can somehow
control the regularity of the MG signal and prevent it from being saturated with inputs
from the LSM.
14
Rescaled Mackey-Glass Equation
X(t)
the opposite figure. As we said previously
the time-scale of the Mackey-Glass system
is artificial and this could be a relevant control parameter whenever the MG signal has
to be in a specific range of oscillations.
First we rescale the variable t −→ t0 = · t.
dX̃(t0 )
X̃(t0 − τ̃ )
− ã X̃(t0 )
=
b̃
dt0
1 + X̃ n (t0 − τ̃ )
dX̃ dt
=
·
dt dt0
t
X̃(t0)
=⇒
...
...
t0
We implemented this procedure in order
to be able to rescale the time dependence of
the Mackey-Glass equation whilst keeping it
in the same dynamical regime as shown in
dX̃
dt
= (b̃)
X̃((t − τ̃ /))
− (ã) X̃(t)
1 + X̃ n ((t − τ̃ /))
We also have the relation X̃(t) = X(t) because both signals are the same in their respective frames. This can only be achieved
using the following rescaled parameters.
a = · ã
b = · b̃
τ = τ̃ /
Which regime for the MG System?
As described in [9], the MG equation can access a wide-range of dynamical regimes.
However, when in oscillatory regime (damping coefficient a smaller than the non-linear
coefficient), the network’s dynamics seems to be seriously altered by the coupling. We
then tuned the MG system similarly to what Appeltant et al. did in [1]: they use the
system in a damped regime (a > b) where the dynamics is sustained by the incoming
perturbations from the LSM. In next section we describe simulations that have been run
using this setup of the MG system.
15
4
Simulations and Measures
4.1
Computations at the edge of chaos
The idea of carrying out computations at the edge of chaos has first been introduced by
Langton (cellular automata) and Packard (genetic algorithms) in the late eighties, based
on the hypothesis that complex systems can show an extended computational power when
performing in a critical regime, i.e. in between ordered and chaotic dynamics.
Thus, a LSM whose reservoir shows critical dynamics could be used to perform efficient
computations in real-time, which motivated a certain number of studies as not much is
yet known about the computational power of neural networks that are constructed consistently with neurobiology.
In the context of the LSM, the criticality is somehow related to its fading memory
property we expect to improve using the coupling LSM/Mackey-Glass. More specifically,
when a network operates in a chaotic regime, it has no fading memory: it mixes the information inconsistently from one step to another, making it hard for a readout to deduce
information about past inputs from the liquid.
How to measure criticality?
A certain number of methods exist to characterize the transition between order and chaos
is complex systems: Lyapunov exponents, sensitivity to initial condition, or mean-field
predictions as in reference [2]. In our work, we attempted to introduce a new kind of
measure of the criticality based on the synaptic activity of the network.
As defined in [2], one can define the activity of the network as
N
. 1 X
xi (t)
a(t) =
N i=1
This sum can be split into the reduced activities of excitatory and inhibitory neurons
using the relation NI = αNE , α = 0.25 in our network.
a(t) =
1
1 X
α 1 X
xi (t) +
xi (t)
1 + α NE i∈E
1 + α NI i∈I
NE,I
1 X
with aE,I (t) =
xi (t)
NE,I i=1
1
α
=
aE (t) +
aI (t)
1+α
1+α
Splitting the sum this way then led to the idea to include synaptic weights to express
the synaptic activity with the instantaneous reduced activities of the network. In the
most general form, such a quantity can be defined by summing over the synapses of the
network. We sum on neurons of index i and over the synapses j neuron i projects into
the network and we normalize by the total number of synapses Ns
. 1 XX
s(t) =
ωij xi (t − τij )
Ns i j
Intuitively, this means that if neuron i is active at time t − τij then the synapse between
neuron k and neuron j will contribute for ωij to the quantity s at time t.
16
When assuming constant synaptic weights ωE , ωI for excitation and inhibition, constant
number of synapses per neuron Nc (Nc = Ns /N ), and in a first place without taking
account of delays, we write:
s(t) =
1
α
ωE aE (t) −
ωI aI (t)
1+α
1+α
We use positive coefficients ωI for inhibition contributing to the sum with a ’-’ to exhibit
clearly the balance between excitation and inhibition. A similar calculation that deals
with axonal delays is given in appendix E
We expected the sign of s(t) to be of possible interest to characterize the dynamics of
the network, by considering that a network whose synaptic activity is mainly excitatory
(s > 0) would tend to synchronize and show ordered behavior whereas chaos would be
more a feature of network dominated by inhibition.
We then studied the dynamics of a network with fixed excitatory synaptic weights
(ωE = 10) and gradually incrementing the inhibitory weights ωI . As shown in the spiketrains plots in appendix C, there is a rather clear change in the dynamics of the network
we tried to explain in terms of the quantity s(t). Even though no definitive conclusions
can be drawn, it appears that in ordered regimes (e.g. first plots of the complement), the
synaptic activity is predominantly positive, and spike trains tend to lose their ordered
features with increasing inhibition, consistently with the average decrease of the synaptic
activity (illustrations in appendix C).
4.2
Quantifying the Separation Property
Distance between states
In the first place, we tried to characterize the separation property of our system by comparing the evolution of the hamming distance (percentage of shared elements) between
two liquid state xup (t) and xu (t) for two input spike trains up and u identical almost
everywhere except that up contains a pulse of spikes (quick succession of spikes) applied
for a certain time to a certain number of neurons, e.g. in the following picture.
u(·)
up(·)
4
Neuron Index
Neuron Index
4
3
2
1
3
2
1
Time
Time
17
The results we obtained are qualitatively similar
to the ones obtained by Mass et al. [8] in the opposite plot, where you can see the evolution of the
distance between liquid states in time, depending
on the distance d(u, v) between two different inputs
u, v . For sufficiently different inputs, one can see
the distance increase to a maximum and then come
back to a noise level. We originally interpreted the
time the system takes to go back to this noise level
as a sign of the memory of the system, and thus expected the coupling LSM/MG to extend this decay
time but unfortunately did not manage to observe
this.
Indeed, the separation between states for different inputs or different initial conditions,
even if it can be a sign of the separation property, is not a direct measure of computational power, as a chaotic network can separate different liquid states into really different
trajectories really well.
Noise amplitude (normalized hamming distance)
Based on the latter assertion, we studied the amplitude of the noise level with respect
to the strength of inhibition in the network. This time, instead of using two different
inputs we just introduce a difference in the initial conditions, similarly to the way one
can compute the Lyapunov exponent of a dynamical system. Here is a plot showing the
evolution of the noise level, blue is for the simple LSM, red for the coupled LSM/MG.
For larger values of the proportionality factor in the expression of Ii,M G , the red curve
lifts up over the blue curve as shown in appendix D.
Inhibition strength ωI , ωE = 10
18
Qualitatively, the strong increase of the noise level on can observe could be a sign of a
transition to chaotic states, if one follows the argument of [2] that the increase/decrease
of distances arising from a slight difference in the initial conditions of the system is a
sign of chaos/order. The last part of the curve (up from ωI ≈ 45), correspond to extreme
inhibition where the dynamics of the network gradually shut down, and no perturbation
can propagate.
Kernel Quality
The Kernel Quality of is a notion from statistical learning theory that characterizes the
degree of complexity of the operations a given system performs on its input. Mass and
Legenstein provided in [5] a method to evaluate the Kernel Quality in the framework of
liquid computing. Let us consider m different inputs u1 , . . . , um which are all functions
of time (spike trains). At a given time t0 , each input ui is associated with a liquid state
xui (t0 ), and we gather them into a matrix M of size m × N , N the total number of
neurons. The rank of matrix M gives its number of linearly independent columns, which
corresponds to the number of input that are mapped into linearly independent liquid
states. Therefore, if matrix M has rank r ≤ m, it means that a linear readout should be
able to separate r classes of inputs.
For this measure we used a proportionality factor for external input Ii,M G so that the
previous noise level curves are similar because we want to measure if the coupled system LSM/MG presents improved computational capabilities when they present similar
dynamical features, which we assume to be the case when they present they present the
same kind of behavior under perturbations, even though the spiking activity may be
completely different. Also, we changed the excitatory weights to ωE = 5 because it helps
the network to stabilize. A few plots are given in appendix D, which showing that as
soon as the network is not in a chaotic state, (the measure of Kernel Quality becomes
thus irrelevant, as a chaotic network would separate any kind of input but inconstantly)
the coupled system MG/LSM has greater Kernel Quality than the simple LSM.
Conclusion
This project represent the first step in an attempt of implementing a new kind of
hierarchical liquid state machine interacting with a mass activity. We first had to learn
about the concepts of machine learning and to get familiar with how to set up a recurrent
network of spiking neurons. The simple idea of coupling an equation to the network
raised many questions, but the way we established the coupling seem to agree with the
approach of paper [1]. We also started to set up a training procedure for the network
based on spoken digit recognition but did not manage to obtain good performances on
both systems so far. Tackling the issue of a transition from order to chaos via criticality
led us to introduce a quantity that could be relevant in this description, and which appears
to be generalizable according to the features of the network (delays, distributed synaptic
weights ...). Numerous unanswered question do still remain on how to tune the network
properly in a first place, how to optimize the coupling in a second place, and also what
are the relevant quantities to observe, and the improvement of the Kernel Quality needs
to be confronted to measures of performance for a specific task.
19
A
Physiological Complements
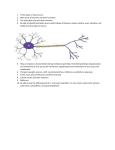
The Biological Neuron
The place of neurons as the most primary and fundamental functional cells of the
nervous system was established in the early 20th century by the anatomist Santiago
Ramón y Cajal. They are excitable cells that have the ability to process, generate and
propagate electrochemical signals in the brain and other parts of the nervous system.
µm in diameter, whereas the range of variation for the nucleus diameter is from 3 to
18 µm.
Soma
? The dendrites, small projections arising
from the cell body, which usually branch
extensively, forming the dendritic tree, and
therefore enhancing considerably the synaptic surface area between the projections of
the other neurons on the neuron itself.
Dendrites
? The axon is a long, cylindrical nerve fibre arising from the soma, and along which
electric fluctuations may propagate. Both
dendrites and axons have a typical thickness of 1 µm.
Nucleus
Axon Hillock
? The axon usually branches more or less
extensively at its distal end. The clubAxon
Axon Terminal
shaped enlargements at the end of terminal branches are called axon terminals
? The soma, also referred as cell body is or boutons, and communicate with target
the central part of the neuron, containing neurons via synapses projecting to the denthe nucleus. Its size varies from 4 to 100 drites.
Description of a Spiking Neuron
Owing to their specific structure, neurons can handle a few basic functions to process and relay electric or electrochemical signals in the brain. The most important of
them is the ability to generate action potentials, i.e extremely short peaks of electric
activity, which travel all along the axons, to the dendritic tree of one or many neurons.
After synaptic transmission at the axons terminals, the incoming stimuli trigger ionic
flux - mainly potassium K+ , sodium Na+ and chlore Cl− - and processes at the soma
(postsynaptic potentials), which may lead the neuron to fire an action potential.
? The presence of a great number of various ions, inside and outside the cell body
induces a membrane potential, which can be altered by the dynamics of several leading ions: potassium K+ , sodium Na+ and chlore Cl− , whose central role is justified by
the presence of their specific voltage-gated channels , selectively regulating the flow of
20
these three species across the membrane. When the neuron is at rest, the potassium
conductance dominates, since the membrane is about 50 times more permeable to K+
than it is for sodium or calcium. Thus, the resting potential is mainly driven by both
the chemical gradient (relative concentrations of ionic populations), tending to drive the
potassium out of the cell, and the electric gradient (membrane potential), tending to
drive the potassium in the cell.
Action Potential
An action potential is a dramatic depolarization of the membrane in response to sufficient
external stimuli. It can be described through the dynamics of the K+ , Na+ and Cl− ions
and their respective voltage-gated channels embedded in the membrane. We describe
here the different steps of action potentials generation by a single neuron.
Schematic Action Potential
Ionic flux during phase 2, 3, 4
a postsynaptic potential is transmitted to
the cell, the membrane depolarizes, opening some voltage-gated Na+ channels and
allowing the sodium to flow into the cell (1).
If the depolarization exceeds some threshold - around 10mV over the resting potential - more sodium channels are opened the
outward potassium current can not balance
the inward sodium current, increasing the
depolarization. Even more Na+ gated channels open and so on (2).
Peak and falling phase: Before the end of
the rising phase, Na+ channels are inactivated, driving the potential to a maximum
and a falling phase (3). The membrane
then repolarizes brutally as K+ voltagegated channels open causing an outward
rush of potassium (4), driving the potential
down to below its resting state because of a
delayed opening of extra K+ voltage-gated
channels (5).
Refractory period: All voltage-gated channels are then closed, but the non-gated ions
channels allows a slower return to the restStimulation & rising phase: At rest, any ing state (6), i.e. the balance between both
Na+ influx through the membrane via non- electric and chemical gradients.
gated channels is balanced by the efflux of
K+ through its non-gated channels. When
? As PSPs have a mean amplitude of 1mV, depolarizations caused by every projecting
a single PSP can not shift the membrane neurons may overlap in time, inducing a
potential above its threshold. Successive summation of their respective amplitudes.
21
Well synchronized trains of PSPs can thus
lift up the membrane potential over the
threshold and increase trigger an action potential.
? The existence of inhibitory synapses
(different neurotransmitters) affecting the
membrane with a negative depolarizations
(or hyperpolarisation) is to be accounted in
the summation process. On the same way
that an EPSP increases the probability for
the neuron to produce an action potential
by making it more responsive to other inputs, an IPSP decreases this probability.
Once the threshold is reached, the amplitude
of the action potential does not depend on
the initial stimulus (all-or-none principle).
Greater stimuli however increase the probability for an action potential to be released.
22
B
Illustrations for Izhikevich model
Membrane Potential (mV)
We use a recurrent network of Izhikevich neurons with different regime of dynamic if
a neuron is excitatory or inhibitory. Based on the anatomy of the cortex, we use regular
spiking neurons for excitation and fast-spiking neurons for inhibition. The following
plots show the response of the neurons under constant input current of 10mV starting at
t = 50ms.
40
Regular-Spiking Excitatory Neuron
20
0
-20
-40
-60
-80
0
50
100
150
200
250
Time (ms)
300
350
400
The principal difference in the set of parameters between these resides in the reset
of the recovery variable. The reset is high for excitatory neurons and low for inhibitory
neurons. As a consequence, the after-spike recovery time (refractory period where the
neuron does not fire) is fairly longer for a excitatory neuron, preventing the emission of
spike trains with high firing-rate.
Membrane Potential (mV)
40
Fast-Spiking Inhibitory Neuron
20
0
-20
-40
-60
-80
0
50
100
150
200
250
Time (ms)
23
300
350
400
C
Spike trains: From order to ”chaos”
? Excitatory weights are fixed to ωE = 10, and inhibitory weights take successively the
values ωI = 1, 4, 6, 12, 23, 28.
? Plots of s(t) over time for increasing inhibitory weights, ωI = 4, 12, 23
24
D
Separation Property Plots
Noise amplitude (normalized hamming distance)
? Noise level vs. inhibition for larger amplification of the input from the Mackey-Glass
to the LSM (note that here ωE = 5).
Inhibition strength ωI , ωE = 5
Kernel Quality
? Kernel quality plots. The y-axis is the number of potentially separable classes of
input, and the x-axis is time. The first 500ms are a warm-up period to leave time to
the network to stabilize its dynamics, blue refers to the simple LSM, red to the coupled
system MG/LSM. ωI takes successively the values 10, 25, 35, 40
Time
25
E
Complements on the balanced synaptic activity
In section 4.1 we tried to characterize the regime of the system using an alternative
quantity based on the synaptic activity of the network, defined by the following expression.
. 1 XX
s(t) =
ωij xi (t − τij )
Ns i j
We expose here an insight in generalizing this quantity. Following calculations are valid
only if we distribute delays to every neuron uniformly (which is how we construct the
network), with no repetitions, i.e. a given neuron can not have more than one synapse
with given delay, which becomes irrelevant as soon as the number of available delays is
smaller that the number of synapses per neuron, but so far the only mean we found to
proceed.
First we define N0 , N1 , . . . , ND the number of synapses in the network with associated
delays 1, 2, . . . , D with D the maximum delay. We can rewrite the relation as (letters E
and I refers to excitatory neurons and inhibitory neurons):
"
X
X
X
N1
ND
1 N0
ωE
xi (t) +
ωE
xi (t − 1) + · · · +
ωE
xi (t − D)
s(t) =
Ns NE
NE
NE
i∈E
i∈E
i∈E
#
1 X
−
xi (t)
ωI
N i∈I
There is no delays for inhibitory neurons, so the sum reduces the same way than in section
(...). The quantities NNEk rescale the sum over the activity of neurons. If all neurons have
a synapse with delay k, then the ratio is equal to 1 and every neuron active contributes
with constant excitatory weights ωE . If Nk < NE then the sum is downscaled to take out
the contribution of the neurons who do not have a synapse with delay k.
Using the fact that Ns = N · Nc , with Nc the number of synapses per neuron, we can
Nk
interpret the quantity Pk =
as the probability per excitatory neuron to have a
Nc · NE
synapse with delay k.
P
As k Nk = NE · Nc , summing all the Pk ’s is equal to one. If we also use the fact that
NE = 4NI we can write s(t) with respect to excitatory and inhibitory activities.
1
4 X
s(t) = ωE
Pk · aE (t − k) − ωI aI (t)
5
5
k
We recall that the previous expansion with no delays gave:
4
1
s(t) = ωE aE (t) − ωI aI (t)
5
5
26
References
[1] L. Appeltant et al.
Information processing using a single node a s complex system.
Preprint
[2] N. Bertschinger, T. Natschläger
Real-Time Computations at the Edge of chaos in Recurrent Neural Networks.
Neural Computation Vol.16, MIT Press, 2004.
[3] E. Izhikevich
Simple Model of Spiking Neuron.
Neural Networks Vol.14, 2003.
[4] H. Jaeger
A tutorial on training recurrent neural networks.
2002.
[5] R. Legenstein, W. Maas
What makes a dynamical system computationally efficient?
New Directions in Statistical Signal Processing: From Systems to Brain, 2005.
[6] W. Maas
Liquid Computing.
Lecture Notes in Computer Science, Springer-Verlag, 2007.
[7] W. Maas, H. Markram
On the computational power of circuits of spiking neurons.
Journal of Computer and System Sciences Vol.69, 2004.
[8] W. Maas
Real-Time Computing Without Stable States: A New Framework for Neural Computation Based on Perturbations
Neural Computation Vol.14, 2002.
[9] B. Mensour, A. Longtin
Power spectra and dynamical invariants for delay-differential and difference equations.
Physica D Vol.113, 1997.
27