Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
DNA repair protein XRCC4 wikipedia , lookup
Amino acid synthesis wikipedia , lookup
Transcription factor wikipedia , lookup
Community fingerprinting wikipedia , lookup
SNP genotyping wikipedia , lookup
Metalloprotein wikipedia , lookup
Transformation (genetics) wikipedia , lookup
Gel electrophoresis of nucleic acids wikipedia , lookup
RNA silencing wikipedia , lookup
Molecular cloning wikipedia , lookup
Bisulfite sequencing wikipedia , lookup
Two-hybrid screening wikipedia , lookup
Real-time polymerase chain reaction wikipedia , lookup
Promoter (genetics) wikipedia , lookup
Polyadenylation wikipedia , lookup
Vectors in gene therapy wikipedia , lookup
DNA supercoil wikipedia , lookup
Biochemistry wikipedia , lookup
Artificial gene synthesis wikipedia , lookup
Non-coding DNA wikipedia , lookup
Silencer (genetics) wikipedia , lookup
Messenger RNA wikipedia , lookup
Eukaryotic transcription wikipedia , lookup
RNA polymerase II holoenzyme wikipedia , lookup
Gene expression wikipedia , lookup
Transcriptional regulation wikipedia , lookup
Point mutation wikipedia , lookup
Genetic code wikipedia , lookup
Epitranscriptome wikipedia , lookup
Deoxyribozyme wikipedia , lookup
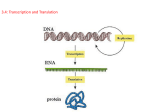
Making Proteins Central Dogma of Genetics Nucleus Information storage DNA TRANSCRIPTION mRNA Information carrier Cytoplasm mRNA Active cell machinery TRANSLATION Protein The Genetic Code The nucleotide sequence of DNA is a code; DNA is an information-storage molecule without enzymatic capabilities (F. Crick). The information in DNA is copied into RNA, which is used to make proteins (mRNA = messenger RNA). Hypothesis: each of the 20 amino acids in proteins is specified by one or more 3 base codons (Gamow). How does the genetic code work? There are 4 RNA bases (U, C, A, G) and they must specify 20 amino acids. How many bases specify G G ACGC UG A U AA CC CG U C AG U UCC AACA U C G G UA AUCCGC C C AG AG C U mRNA a single amino acid? 1 Base? 3 Bases? 2 Bases? 4 Bases?... A doublet code could specify a maximum of 4 x 4 or 16 amino acids. U C A G 1 2 3 4 4 < 20: Not enough Since there are only 4 bases, a singlet code could only specify 4 amino acids. U U UC U A U G 2 3 4 1 C U CC C A C G 6 5 7 8 AU AC AA AG 9 12 10 11 G U G C G A GG 13 14 15 16 16 < 20: Not enough A triplet code could specify a maximum of 4 x 4 x 4, or 64 amino acids. UU U UU C U U A UUG 2 1 3 4 CC U C CC C C A CCG 6 5 7 8 A A U A A C A A A A AG 9 10 11 12 GG U G G C G GA etc... 14 15 13 64 > 20: More than enough Figure 17.4 The dictionary of the genetic code One gene-one polypeptide hypothesis: A gene is a length of a DNA molecule that contains the information to produce one polypeptide chain Figure 17.2 Overview: the roles of transcription and translation in the flow of genetic information (Layer 1) Figure 17.2 Overview: the roles of transcription and translation in the flow of genetic information (Layer 2) Figure 17.2 Overview: the roles of transcription and translation in the flow of genetic information (Layer 3) Figure 17.2 Overview: the roles of transcription and translation in the flow of genetic information (Layer 4) Figure 17.2 Overview: the roles of transcription and translation in the flow of genetic information (Layer 5) Transcription produces an RNA molecule complementary to a DNA template DNA 3’ RNA 3’ 5’ 3’ 3’ 5’ 5’ P RNA Template strand 5’ 3’ P P P P P 3’ P O HO OH O OH C U G A T C O O O O P P P 5’ DNA 5’ P RNA transcription is catalyzed by RNA polymerase RNA polymerase DNA Protein Synthesis Begins with the Process of Gene Transcription Steps of Transcription • RNA polymerase binds to the promoter region of the DNA • RNA polymerase unwinds the DNA. • RNA polymerase reads DNA 3' to 5' and synthesizes complementary RNA 5' to 3'. Figure 17.6 The stages of transcription: initiation, elongation, and termination (Layer 1) Figure 17.6 The stages of transcription: initiation, elongation, and termination (Layer 2) Figure 17.6 The stages of transcription: initiation, elongation, and termination (Layer 3) Figure 17.6 The stages of transcription: initiation, elongation, and termination (Layer 4) Close up of transcription QuickTime™ and a TIFF (LZW) decompressor are needed to see this picture. In eukaryotes: proteins called transcription factors bind to the promoter first, then RNA polymerase binds to start transcription After Transcription Transcription in Prokaryotes • The RNA produced is ready to be translated = mRNA Transcription in Eukaryotes • The RNA produced must be modified before translation: 1° transcript--> mRNA • Eukaryotic mRNAs are processed in the nucleus by addition of a 5' cap and 3' poly A tail • Eukaryotic genes have introns: non-coding regions that must be removed from the primary mRNA to make an intact uninterrupted message. RNA processing in Eukaryotes Molecules called small nuclear ribonucleoproteins (snRNPs) combine to splice introns from mRNA Figure 17.11 Correspondence between exons and protein domains After transcription, the next step is translation Translation Converts the Nucleotide Sequence of mRNA into the Amino Acid Sequence of a Protein Translation occurs on ribosomes either in the cytoplasm or on the endoplasmic reticulum Structure of a ribosome Large subunit Small subunit Proteins E site P site A site rRNAs = ribosomal RNA Active site (contains only rRNA) The adaptor molecule between mRNA and protein is tRNA (transfer RNA) Stems are created by hydrogen bonding between complementary base pairs Loops consist of unpaired bases Figure 17.13b The structure of transfer RNA (tRNA) An aminoacyl-tRNA synthetase joins a specific amino acid to a tRNA Early model of tRNA function Amino acid Ser 3’ A C C 5’ Binding site for amino acid Binding site for mRNA codon Serine anticodon A GU 5’ U CA mRNA Serine codon 3’ Figure 17.15 The anatomy of a functioning ribosome Translation Converts the Nucleotide Sequence of mRNA into the Amino Acid Sequence of a Protein Translation occurs in three steps: • Initiation: the ribosome 30S subunit binds mRNA and moves to the AUG codon, which is the translation start site. • The initiator methionine tRNA binds to the AUG start codon. • The ribosome 50S subunit assembles so that the initiator tRNA and the AUG codon are in the P site. Figure 17.17 The initiation of translation Translation Converts the Nucleotide Sequence of mRNA into the Amino Acid Sequence of a Protein Translation occurs in three steps: • Elongation: amino acids are joined together and the ribosome moves to the next codon. • New tRNAs enters the A site of the ribosome • A peptide bond forms between the polypeptide on the tRNA in the P site and the amino acid in the A site, which transfers the polypeptide to the A site tRNA. • The ribosome moves along the mRNA in the 5' to 3' direction. Figure 17.18 The elongation cycle of translation Translation Converts the Nucleotide Sequence of mRNA into the Amino Acid Sequence of a Protein Translation occurs in three steps: • Termination: when a stop codon on mRNA is encountered in the A site, the completed polypeptide is released, and the ribosome disengages. • Release factors are required. Figure 17.19 The termination of translation Post-translational events affect the structure, activity, and destination of the protein Proteins must fold into their proper 3D structure. Primary structure Tertiary structure Secondary structure Quaternary structure The Central Dogma: Information Flows from DNA to RNA to Proteins (F.Crick) Viruses that have RNA genomes contradict the central dogma, but all cells conform to it. Virus protein coat Virus RNA 1. Start of infection. 2. Reverse transcriptase uses Virus RNA enters host Virus RNA as template to cells. produce virus DNA 3. Virus DNA directs 4. End of infection. the production of new New generation of virus particles. virus particles burst from host cell. Mutation and DNA Repair Mechanisms Mutations are created by chemicals, radiation, errors in meiosis and mistakes in DNA replication. • Mutations can be deleterious, beneficial, or silent. • Mutations in an individual are usually deleterious, may cause disease and death. • Mutations in a population are a source of genetic diversity that allows evolution to occur. Point mutations are a change in single base pair of DNA A A C T G G C A base-pair substitution: Wild type T T G A C C G A A C T G G C A A C T A G C MUTANT 3' 5' A A C T G G C T T G A T C G DNA replication T T G A C C G 5' 3' A A C T G G C T T G A T C G DNA replication A A C T G G C Wild type Parental DNA T T G A C C G T T G A C C G First generation progeny A A C T G G C Wild type T T G A C C G Second generation progeny Figure 17.24 Categories of Base-pair substitutions DNA point mutations can lead to a different amino acid sequence. Phenotype Start of coding sequence CAC DNA sequence GTG GTG CAC GAC CTG TGA ACT GGA CCT CTC GAG CTC GAG Normal Amino acid sequence Valine CAC DNA sequence GTG Histidine GTG CAC Leucine GAC CTG Threonine Glutamic Proline Glutamic acid acid TGA ACT GGA CCT CAC GTG Normal red blood cells CTC GAG Mutant Amino acid sequence Histidine Valine Threonine Leucine Proline Valine Glutamic acid Sickled red blood cells Insertion or deletion of a single base-pair causes frameshift mutations UV radiation can cause 2 thymines that are next to each other to bind to each other instead of the adenines in the other strand UV-induced thymine dimers caused DNA to kink P CH2 DNA strand with adjacent P thymine bases CH P N O N Thymine H H O N Thymine CH3 O Kink P O CH2 O N N O H O N H P Thymine dimer H O UV light N 2 CH2 O CH3 O H P H O CH3 H N O CH3 Mutation and DNA Repair Mechanisms DNA Repair Mechanisms • DNA polymerase proofreads and corrects point mutations during replication. • Other excision repair systems scan newly formed DNA and correct remaining mutations. • Repair enzymes identify the correct template strand by its methyl groups. • Defects in repair system enzymes are implicated in a variety of cancers. DNA polymerase proofreads DNA during replication 3' Mismatched bases. T G T C C A C A G G A 5' T C G C G 5' OH 3' Polymerase III can repair mismatches. 5' 3' 5' T G T C C A C A G G A T C G C METHYLATION-DIRECTED MISMATCHED BASE REPAIR Mismatch 1. Where a mismatch occurs, the correct base is located on the methylated strand: the incorrect base occurs on the unmethylated strand. 2. Enzymes detect mismatch and nick unmethylated strand. 3. DNA polymerase I excises nucleotides on unmethylated strand. 4. DNA polymerase I fills in gap in 5' 3' direction. 5. DNA ligase links new and old nucleotides. Repaired Mismatch Some genetic diseases are associated with mutations in DNA repair mechanisms Xeroderma pigmentosum is a defect in ultraviolet radiation induced DNA repair mechanisms; characterized by severe sensitivity to all sources of UV radiation (especially sunlight). Symptoms include blistering or freckling, premature aging of skin,with increased cancers in these same areas, blindness resulting from eye lesions or surgery for skin lesions close to the eyes