Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
RNA interference wikipedia , lookup
Promoter (genetics) wikipedia , lookup
Cell-penetrating peptide wikipedia , lookup
Community fingerprinting wikipedia , lookup
Holliday junction wikipedia , lookup
Molecular cloning wikipedia , lookup
RNA polymerase II holoenzyme wikipedia , lookup
Gel electrophoresis of nucleic acids wikipedia , lookup
Polyadenylation wikipedia , lookup
List of types of proteins wikipedia , lookup
Messenger RNA wikipedia , lookup
Silencer (genetics) wikipedia , lookup
Eukaryotic transcription wikipedia , lookup
Transcriptional regulation wikipedia , lookup
RNA silencing wikipedia , lookup
Cre-Lox recombination wikipedia , lookup
Expanded genetic code wikipedia , lookup
Point mutation wikipedia , lookup
Molecular evolution wikipedia , lookup
Non-coding DNA wikipedia , lookup
Artificial gene synthesis wikipedia , lookup
Gene expression wikipedia , lookup
Biochemistry wikipedia , lookup
Genetic code wikipedia , lookup
Non-coding RNA wikipedia , lookup
Epitranscriptome wikipedia , lookup
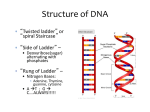
Nucleic Acid Introduction The nucleic acids are the compounds that are responsible for the storage and transmission of the genetic information that controls the growth, function and reproduction of all types of cell. They are classified into two general types: the deoxyribonucleic acid (DNA), whose structures contains the sugar residue ßD-deoxyribose, and the ribonucleic acids (RNA), whose structures contain the sugar residue ß-D-ribose. Both types of nucleic acid consist of long polymer chains based on a repeating unit known as a nucleotide. Each nucleotide consists of a purine or pyrimidine base bonded to the 1' carbon atom of a sugar residue by a b-N-glycosidic link. These sugar-base units, which are knownas nucleosides are linked, through the 3' and 5' carbons of their sugar residues, by phosphate units to form the nucleic acid polymer chain. Fig: The general structure of a nucleotide Fig: Section of a nucleic acid chain Nucleotides can exist as individual molecules with one or more phosphate or polyphosphate groups attached to the sugar residue. The names of these molecules are based on those of the corresponding nucleosides. Ribose nucleosides are named after their bases but with either the suffix -osine or -idine. Fig: The bases commonly found in DNA and RNA. These bases are indicated by the appropriate letter in the structures of Nucleic acids. Thymine is not found in RNA; it is replaced by uracil, which is similar in shape and structure. Nucleosides based on deoxyribose use the name of the corresponding RNA nucleoside prefixed by deoxy-. The purine and pyrimidine rings are numbered in the conventional manner whilst primes are used for the sugar residue numbers. Numbers are not included in the name if the phosphate unit is at position 5'. The positions of phosphates attached at any other position are indicated by the appropriate locants. Fig:Some examples of individual nucleotides. The abbreviations used to represent thestructures of nucleotides based on deoxyribose are prefixed by d – Types of nucleic acids Deoxyribonucleic acid Deoxyribonucleic acid (DNA) is a nucleic acid containing the genetic instructions used in the development and functioning of all known living organisms (with the exception of RNA viruses). The DNA segments carrying this genetic information are called genes. Likewise, other DNA sequences have structural purposes, or are involved in regulating the use of this genetic information. Along with RNA and proteins, DNA is one of the three major macromolecules that are essential for all known forms of life. DNA consists of two long polymers of simple units called nucleotides, with backbones made of sugars and phosphate groups joined by ester bonds. These two strands run in opposite directions to each other and are therefore anti-parallel. Attached to each sugar is one of four types of molecules called nucleobases (informally, bases). It is the sequence of these four nucleobases along the backbone that encodes information. This information is read using the genetic code, which specifies the sequence of the amino acids within proteins. The code is read by copying stretches of DNA into the related nucleic acid RNA in a process called transcription. Within cells DNA is organized into long structures called chromosomes. During cell division these chromosomes are duplicated in the process of DNA replication, providing each cell its own complete set of chromosomes. Eukaryotic organisms (animals, plants, fungi, and protists) store most of their DNA inside the cell nucleus and some of their DNA in organelles, such as mitochondria or chloroplasts. In contrast, prokaryotes (bacteria and archaea) store their DNA only in the cytoplasm. Within the chromosomes, chromatin proteins such as histones compact and organize DNA. These compact structures guide the interactions between DNA and other proteins, helping control which parts of the DNA are transcribed. Ribonucleic acid Ribonucleic acid (RNA) functions in converting genetic information from genes into the amino acid sequences of proteins. The three universal types of RNA include transfer RNA (tRNA), messenger RNA (mRNA), and ribosomal RNA (rRNA). Messenger RNA acts to carry genetic sequence information between DNA and ribosomes, directing protein synthesis. Ribosomal RNA is a major component of the ribosome, and catalyzes peptide bond formation. Transfer RNA serves as the carrier molecule for amino acids to be used in protein synthesis, and is responsible for decoding the mRNA. In addition, many other classes of RNA are now known. DNA, structure and replication DNA molecules are large, with RMMs up to one trillion (1012). Experimental work by Chargaff and other workers led Crick and Watson to propose that the three dimensional structure of DNA consisted of two single molecule polymer chains held together in the form of a double helix by hydrogen bonding between the same pairs of bases, namely the adenine–thymine and cytosine–guanine base pairs. These pairs of bases, which are referred to as complementary base pairs, form the internal structure of the helix. They are hydrogen bonded in such a manner that their flat structures lie parallel to one another across theinside of the helix. The two polymer chains forming the helix are aligned in opposite directions. In other words, at the ends of the structure one chain has a free 3’-OH group whilst the other chain has a free 5’-OH group. X-Ray diffraction studies have since confirmed this as the basic three dimensional shape of the polymer chains of the B-DNA, the natural form of DNA. This form of DNA has about 10 bases per turn of the helix. Its outer surface has two grooves, known as the minor and major grooves respectively, which act as the binding sites for many ligands. Electron microscopy has shown that the double helical chain of DNA is folded, twisted and coiled into quite compact shapes. A number of DNAstructures are cyclic, and these compounds are also coiled and twisted into specific shapes. These shapes are referred to as supercoils, supertwists and superhelices as appropriate. Fig: Supercoiled Eukaryotic DNA DNA molecules are able to reproduce an exact replica of themselves. The process is known as replication and occurs when cell division is imminent. It is believed to start with the unwinding of the double helix starting at either the end or more usually in a central section, the separated strands acting as templates for the formation of a new daughter strand. New individual nucleotides bind to these separated strands by hydrogen bonding to the complementary parent nucleotides. As the nucleotides hydrogen bond to the parent strand they are linked to the adjacent nucleotide, which is already hydrogen bonded to the parent strand, by the action of enzymes known as DNA polymerases. As the daughter strands grow the DNA helix continues to unwind. However, both daughter strands are formed at the same time in the 5' to 3' direction. This means that the growth of the daughter strand that starts at the3' end of the parent strand can continue smoothly as the DNA helix continues to unwind. This strand is known as the leading strand. However, this smooth growth is not possible for the daughter strand that started from the 5' of the parent strand. This strand, known as the lagging strand, is formed in a series of sections, each of which is still grows in the 5' to 3' direction. These sections, which are known as Okazaki fragments after their discoverer, are joined together by the enzyme DNA ligase to form the second daughter strand. Replication, which starts at the end of a DNA helix, continues until the entire structure has been duplicated. The same result is obtained when replication starts at the centre of a DNA helix. In this case unwinding continues in both directions until the complete molecule is duplicated. This latter situation is more common. RNA, structure and transcription Ribonucleic acids are found in both the nucleus and the cytoplasm. In the cytoplasm RNA is located mainly in small spherical organelles known as ribosomes, which consist of about 65% RNA and 35% protein. The structures of RNA molecules consist of a single polymer chain of nucleotides with the same bases as DNA, with the exception of thymine, which is replaced by uracil, which forms a complementary base pair with adenine. These chains often form single stranded hairpin loops separated by short sections of a distorted double helix formed by hydrogen bonded complementary base pairs. Fig: Two dimensional cloverleaf representation of the structure of transfer RNA (tRNA) showing the hairpin loops in the structure All types of RNA are formed from DNA by a process known as transcription, which occurs in the nucleus. It is thought that the DNA unwinds and the RNA molecule is formed in the 5' to 3' direction. It proceeds smoothly with the 3' end of the new strand bonding to the 5' end of the next nucleotide. Thisbonding is catalysed by enzymes known as RNA polymerases. Since only complementary base pairs can hydrogen bond, the order of bases in the new RNA strand is determined by the sequence of bases in the parent DNA strand. Fig: Transcription process In this way DNA controls the genetic information being transcribed into the RNA molecule. This information is in the form of a series of exons and introns complementary to those found in the parent gene. The strands of DNA contain start and stop signals, which control the size of the RNA moleculeproduced. These signals are in the form of specific sequences of bases. The RNA produced by transcription is known as either heterogeneous nuclear RNA (hnRNA), premessenger RNA (pre-mRNA) or primary transcript RNA (ptRNA). Classification and function of RNA Ribonucleic acids are classified according to their general role in protein synthesis. Messenger RNA (mRNA) is believed to be produced from the hnRNA formed by transcription in the nucleus. The introns are removed and the remaining exons are spliced together to form a continuous sequence of bases that are complementary to the gene's exons. The mRNA now leaves the nucleus via nuclear pores and carries its message to the ribosome in the cytoplasm. It binds to the ribosome, where it dictates the order in which the amino acids are linked to form the structure of the protein This information is carried in the form of a trinucleotide code known as a codon. The nature of a codon is indicated by a sequence of letters corresponding to the 5' to 3' order of bases in the trinucleotide. Some amino acids have more than one codon. The mRNA's codon code is known as the genetic code (Table 1.9) and is used by all livingmatter as the code for protein synthesis. mRNA is synthesized as required and, once its message has been delivered, it is eventually decomposed. Transfer RNA (tRNA) transports the required amino acids from the cell’s amino acid pool to the ribosome. Each type of amino acid can only be transported by its own specific tRNA molecule. The tRNA, together with its amino acid residue, binds to the mRNA already bound to the ribosome. It recognizes the point on the mRNA where it has to deliver its amino acid through the use of a consecutive sequence of three bases known as an anticodon, which is found on one of the loops of the tRNA . This anticodon binds to the complementary codon of the mRNA. Consequently, the amino acids can only be delivered to specific points on the mRNA, which controls the order in which amino acid residues are added to the growing protein. This growth occurs from the N-terminal end of the protein. Ribosomal RNA (rRNA) is involved in the protein synthesis. It is found in the ribosomes which occur in the cytoplasm. Ribosomes contain about 35% protein and 65% rRNA. Experimental evidence suggests that rRNA molecules have structures that consist of a single strand of nucleotides whose sequence varies considerably from species to species. The strand is folded and twisted to form a series of single stranded loops separated by sections of double helix, which is believed to be formed by hydrogen bonding between complementary base pairs. The general pattern of loops and helixes is very similar between species even though the sequences of nucleotides are different. However, little is known about the three dimensional structures of rRNA molecules and their interactions with the proteins found in the ribosome.