Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Activity-dependent plasticity wikipedia , lookup
Neuroinformatics wikipedia , lookup
Neuroplasticity wikipedia , lookup
Neurotransmitter wikipedia , lookup
Binding problem wikipedia , lookup
Cognitive neuroscience wikipedia , lookup
Neuropsychology wikipedia , lookup
Neurophilosophy wikipedia , lookup
History of neuroimaging wikipedia , lookup
Molecular neuroscience wikipedia , lookup
Donald O. Hebb wikipedia , lookup
Neural engineering wikipedia , lookup
Embodied cognitive science wikipedia , lookup
Optogenetics wikipedia , lookup
Artificial intelligence wikipedia , lookup
Nonsynaptic plasticity wikipedia , lookup
Neuroanatomy wikipedia , lookup
Neural coding wikipedia , lookup
Mind uploading wikipedia , lookup
Development of the nervous system wikipedia , lookup
Stimulus (physiology) wikipedia , lookup
Central pattern generator wikipedia , lookup
Artificial neural network wikipedia , lookup
Single-unit recording wikipedia , lookup
Artificial general intelligence wikipedia , lookup
Sparse distributed memory wikipedia , lookup
Neuropsychopharmacology wikipedia , lookup
Neural modeling fields wikipedia , lookup
Holonomic brain theory wikipedia , lookup
Synaptic gating wikipedia , lookup
Metastability in the brain wikipedia , lookup
Biological neuron model wikipedia , lookup
Catastrophic interference wikipedia , lookup
Nervous system network models wikipedia , lookup
Convolutional neural network wikipedia , lookup
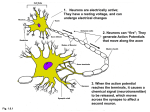
Artificial Intelligence (AI). Neural Networks Ivan Jordanov, University of Portsmouth, UK. Email: [email protected] Website: jordanoi.myweb.port.ac.uk/ Erasmus presentation, University of Uppsala, Sept, 2012 Portsmouth 13/09/2012 2 Historic Portsmouth • Home of HMS Victory, the Mary Rose and HMS Warrior • Historic Old Portsmouth with cobbled streets and ancient buildings • Birthplace of Charles Dickens and home of Sir Arthur Conan Doyle HMS Victory in Portsmouth, 1900. Spinnaker Tower - the city’s new landmark situated on the vibrant waterfront 13/09/2012 4 Key Facts about the University Established in 1869 First degree awarded in 1900 Over 20,000 students, 3,500 from overseas 30 academic departments across five faculties Over 500 degree programmes Extensive range of world leading and internationally excellent research Five Faculties Portsmouth Business School Creative and Cultural Industries Humanities and Social Sciences Science Technology Park Building 13/09/2012 7 School of Computing 13/09/2012 8 Outline 13/09/2012 Introduction The Perceptron ADALINE example Linear separability problem Multi-Layer Perceptrons (MLP) Backpropagation Dr. I. Jordanov 9 Essential texts (not mandatory) • Robert Schalkoff, Intelligent Systems, Jones & Bartlett, 2011, ISBN-10: 0-7637-8017-0. • Ethem Alpaydin, Machine Learning (2nd ed.), MIT, 2010, ISBN: 978-0-262-01243-0. • Stephen Marsland, Machine Learning. An Algorithmic Perspective, CRC Press, 2009, ISBN: 978-1-4200-6718-7. • Melanie Mitchell, An Introduction to GA, MIT; 2001, ISBN: 0-262-13316-4. • Kenneth De Jong, Evolutionary Computation, MIT, 2006, ISBN: 0-262-04194-4. • H. Iba & N. Norman, New Frontier in Evolutionary Algorithms, ICP, 2012, ISBN: 0-13-978-1-84816-681-3. • George Luger, Artificial Intelligence (6th ed.), Pearson/ Addison-Wesley, 2009, ISBN: 0-13-209001-5. 13/09/2012 Dr. I. Jordanov 10 Additional reading • Chris Bishop, Neural Networks for Pattern Recognition, Clarendon Press: Oxford, 2004. • B. D. Ripley, Pattern Recognition and Neural Networks, Cambridge University Press, 2007. • R. Haupt & S. Haupt, Practical Genetic Algorithms, Wiley, 1998. • E. Lamm and R. Unger, Biological Computation, CRC Press, 2011. • M. Jones, Artificial Intelligence, Jones&Bartlett, 2009. • M. Negnevitsky, Artificial Intelligence, Addison Wesley, 2002. • Zbigniev Michalewicz, GA+ Data Structures = Evolution Programs (2nd ed.), Springer Verlag, 1999. • Phil Picton, Neural Networks (2nd ed.), Palgrave, 2000. • David Goldberg, Genetic Algorithms, Addison-Wesley, 1989. There are many others - some cheaper, so have a good browse. 13/09/2012 Dr. I. Jordanov 11 Useful sites www.alibris.com/search/books/ - search for cheap books; www.ics.uci.edu/~mlearn/MLRepository.html - a NN repository; www.cs.toronto.edu/~delve/ - a repository of problems; ftp.sas.com/pub/neural/FAQ.html - general information on NN; www.aic.nrl.navy.mil/~aha/research/machine-learning.html - a repository; dsp.jpl.nasa.gov/members/payman/swarm/ - resources on swarm intelligence; alife.santafe.edu – information on Artificial Life (AL); www.evalife.dk/bbase - Evolutionary Computing (EC) and AL repository; www.informatik.uni-stuttgart.de/ifi/fk/evolalg/ - EC repository. www.nd.com/ - NeuroDimension (info about NN & GA) 13/09/2012 Dr. I. Jordanov 12 Introduction Even before its early days (the first learning programme to play a credible game of checkers in 1950s), the AI and the concept of intelligent machines have been fascinating humankind. Late 1990s, the IBM supercomputer Deep Blue became the first computer program to defeat the world chess champion; Currently, Google can mine 'click-thru' feedback from millions of users to make its search engine more ‘intelligent’; Netflix can recommend movies and Amazon books by learning from the purchases and ratings of its customers; Microsoft's Kinect sensor for its Xbox gaming system allows computer avatars to mimic the users full-body motion by simply visually observing their behaviour (from patterns of reflected infrared light); 13/09/2012 Dr. I. Jordanov 13 Last year, IBM's Watson system (the size of 8 large home refrigerators, a brain of 2400 home computers and a database of about 10 million documents) beat the two best human players on the television quiz show Jeopardy. It used AI to analyse vast collections of documents (of previous games) and to assimilate and combine multiple forms of reasoning, determining strategies for different types of questions (http://www.youtube.com/watch?v=DywO4zksfXw). But, will there ever be a computer that laughs at the comedy show The Bing Bang Theory? However, in many ways the AI is still not nearly as flexible or effective as the human one and most AI systems require explicit supervision for the specific task they perform. As Marvin Minsky (a prominent professor in AI from MIT) said in his recent interview: "There aren't any machines that can do the commonsense reasoning that a four-or five-year-old child can do.” 13/09/2012 Dr. I. Jordanov 14 1. Introduction to ANN 13/09/2012 In their effort to build intelligent machines scientists have been inspired by the human brain model - trying to simulate it on a computer. ANN are simple models of a collection of brain cells. They have some of the same basic properties of the brain cells, and are able to learn, classify, recognize, compute functions and generalize or reason. The human brain (fig.7) is made up of approximately 1011 neurons with of the order of 1015 connections between them. Fig. 2 provides a schematic diagram of a biological neuron and the connections between neurons. Dr. I. Jordanov 15 Our brain is composed of interconnected neurons transmitting electro-chemical signals. From a very large number of extremely simple processing units (each performing a weighted sum of its inputs and if it exceeds a certain threshold, then firing a signal), the brain manages to perform extremely complex tasks. Figure 7. Main brain areas: Frontal Lobes - planning, organizing, problem solving, memory, impulse control, decision making, selective attention, controlling our behaviour and emotions (the left frontal lobe - speech and language); Temporal Lobes - recognizing and processing sound, understanding and producing speech, various aspects of memory; Occipital Lobes - receive and process visual information, contain areas that help in perceiving shapes and colours; Brain Stem - (midbrain, the pons, and the medulla) breathing, heart rate, blood pressure, swallowing; Cerebellum - balance, movement, coordination. (www.BrainHealthandPuzzels.com) 13/09/2012 Dr. I. Jordanov 16 (a) (b) Figure 8. (a) A biological neuron; (b) An artificial neuron (perceptron) next to it (vv.carleton.ca/~neil/neural/neuron-a.html). 13/09/2012 Dr. I. Jordanov 17 Figure 9. Each neuron receives electrochemical inputs from other neurons at the dendrites. If the sum of these signals is powerful enough to activate the neuron, it will transmit an electrochemical signal along the axon to the other neurons whose dendrites are attached to any of the axon terminals (through synaptic gaps) www.g2conline.org/?gclid=CNf7mODlga4CFVAhtAodjyek4A#Thinking?aid=2023&cid=202 . 13/09/2012 Dr. I. Jordanov 18 Each neuron in the brain can take electrochemical signals as input via its dendrites and can process them before sending new signals along the axon and via the dendrites of the other connected neurons. The neuron sends signal if the collective influence of all its inputs reaches a threshold level (axon hillock's threshold)– the neuron is said to fire. The impulse is sent from the cell body (soma), through the axon, which influences the dendrites of the next neuron over narrow gaps called synapses. They translate the pulse in some degree into excitatory or inhibitory impulse of the next neuron (fig.9). 13/09/2012 Dr. I. Jordanov 19 13/09/2012 It is this receiving of signals and summation procedure that is emulated by the artificial neuron. The artificial neuron is clearly a simplification of the way the biological neuron operates. ANN are an approach for modelling a simplification of the biological neurons – the brain is used as an inspiration. Thus far, ANN haven't even come close to modelling the complexity of the brain. Nevertheless, they have shown to be good at problems which are easy for a human but difficult for a traditional computer, such as image recognition and predictions, based on past knowledge. Dr. I. Jordanov 20 13/09/2012 McCulloch and Pitts (1943) - model of a biological neuron (output either 0 or 1). Von Neumann (1956) - negative, inhibitory inputs. Rosenblatt invented the perceptron in the late 1950s, which is considered as one of the earliest NN models. Interest in NN came to virtual halt in the 1970s because of the limitations of a single layer systems and pessimism over multilayer systems (Minsky and Papert, 1969). Recently, resurgence of interest in NN because of increased power of computers and new developments in: NN architectures and learning algorithms; analog VLSI (Very Large Scale Integrated) circuits; parallel, grid and cloud processing techniques; wide variety of their application areas. Dr. I. Jordanov 21 2. The Perceptron The perceptron is the simplest type of ANN, it represents a single brain cell. It mimics a neuron by summing its weighted inputs and producing output 1 if the sum is greater than some adjustable threshold value, and 0 otherwise (Fig.10). Iuput x0 x1 w0 x2 w1 w2 … xn 13/09/2012 Summing junction Activation function Output O(x) wn Figure 10. A Perceptron. Dr. I. Jordanov 22 13/09/2012 The first part of a perceptron is a set of its inputs (xi , i=1, ..., n). These are usually binary (0 / 1; or 1 / -1). An input is referred to: if xi = 1 - active (excitatory); if xi = 0 – inactive; and if xi = -1 – inhibitory. The connection weights (wi, i=1, ..., n) are typically real valued (both positive and negative). The perceptron itself consists of the inputs, the weights, the summation processor, and the adjustable threshold processor (activation function). Dr. I. Jordanov 23 ADALINE 13/09/2012 ADALINE (ADAptive LINear Elements) is one of the earliest NN that incorporated perceptrons. Developed by Widrow and Hoff (Picton, Neural Networks, Palgrave, 2000). -1 +1 +1 +1 +1 -1 -1 -1 -1 +1 -1 -1 -1 -1 +1 -1 -1 +1 +1 +1 -1 -1 -1 -1 +1 -1 -1 -1 -1 +1 -1 +1 +1 +1 +1 Fig. 11. The digit 3. Dr. I. Jordanov 24 Inputs xi, i=1,…, n: +1 for black, and -1 for white. Weights wi, i=1,…, n: +1 for black, and -1 for white. y( x ) 1 if x 0, 1 if x 0. where the net is n x wi xi , n= 35, x0 = +1, and w0 = -34. i0 During the training, a set of examples of input patterns, that have to be classified, is shown to the NN, and the weights (and the threshold) are adjusted until the NN produces correct output. 13/09/2012 Dr. I. Jordanov 25 13/09/2012 A single perceptron will produce an output of +1 or -1 if the input pattern belongs, or not, to a particular class. If ADALINE is used to recognize (classify) the digits from 0 to 9, then 10 output neurons can be used, one for each class. For example, there should be one neuron, which fires when the digit 3 is presented as input (and the others 9 won't). The weights in that neuron will be set such, that when a 3 appears, the weighted sum (net) will be positive, and for any other number the net will be negative (or zero). Dr. I. Jordanov 26 Input Layer (Layer 0) x0 1 x1 -1 -1 +1 -1 -1 -1 -1 -1 +1 x2 1 -1 -1 +1 -1 -1 +1 1 -1 -1 +1 +1 +1 -1 -1 -1 -1 +1 -1 -1 -1 -1 +1 -1 +1 +1 +1 +1 +1 +1 +1 x3 Output Layer (Layer 1) w0i -34 -1 +1 +1 -1 x35 y0 y( x ) 1 if x 0, 1 if x 0. -1 y1 0 -1 y2 1 -1 2 y3 +1 3 -1 9 y9 -1 Fig. 11(a). Network of simple perceptrons (to recognize the digits 0 to 9 - just some of the weight connections are shown). When number 3 is presented, only the corresponding output neuron should fire. Each weighted input is: –1 * –1 = 1 (white), or 1 * 1 = 1 (black). If the threshold (offset) is set to -34, than the weighted sum, net = (35*1) - 34 = 1 (which is > 0), so the output is +1 after passing through the signum function. For any other pattern (numeral) the net will be maximum -1 (one corrupted white/black, 33-34=-1), or minimum -69 (white 3 on black background, -35-34=69), so the neuron won't fire. Now, what if slightly different 3 is to be classified (one bit corrupted, black instead of white, or vice versa) (Fig. 2)? 13/09/2012 Dr. I. Jordanov 28 net = (34*1) + (1*-1) - 34 = -1, -1 +1 +1 +1 +1 -1 -1 -1 -1 +1 -1 +1 -1 -1 +1 -1 -1 +1 +1 +1 What if we change ω0 to -32? -1 -1 -1 -1 +1 -1 -1 -1 -1 +1 -1 +1 +1 +1 +1 Both, the perfect pattern and the pattern with 1 corrupted bit, will be correctly classified. so, net < 0, output -1, the neuron won't fire. Fig. 12. Digit 3 with one corrupted bit. In fact there are many more patterns with one corrupted bit, and they all will be recognized without being previously presented in the training session. 13/09/2012 Dr. I. Jordanov 29 13/09/2012 This is called generalization - when from few (or several) training patterns (examples), the NN can later correctly classify patterns that haven't been shown during the training session. Or, during the training (when presenting to the NN just few (or several) patterns of a class), the weights are adjusted with such values, that later, a set of unseen patterns of the same class will produce the same output response. Based on Kolmogorov's theorem, which states that a function of several variables can be represented as a superposition (a sum of) several functions of one variable, backpropagation MLP are considered to be universal approximators. Dr. I. Jordanov 30 Linear separability classification problem Let's consider the two dimensional (2D) case from Fig.13, when a pattern has only two inputs (+ bias). The weighted 2 sum will be: net x w x = w x + w x + w x i 0 i i 0 0 1 1 2 2 x2 x1 Fig. 13. A Linearly separable pattern classification problem: black points belong to class1 and whites to class2 (e.g., ‘thin’ and ‘fat’ classes for people: x2- body height; x1 – body weight). 13/09/2012 Dr. I. Jordanov 31 If we solve the equation f ( x ) 0 , i. e., w0x0 + w1x1 + w2x2 = 0, (bear in mind that x0=1), we shall receive equation of a line: w0 w0 w1 w1 x2 x1 , ( x2 ax1 b, a , b ). w2 w2 w2 w2 x2 b x1 13/09/2012 -b/a Fig. 13a. The two coefficients (weights) define the angle between the line and x1 axes. Dr. I. Jordanov 32 The line equation will be equal to 0 for every point (x1, x2) belonging to the line (less than 0 for every point below and greater than 0 for every point above the line): f ( x ) x2 ax1 b 0 13/09/2012 The line location is determined by the three weights. If a point (x1, x2), Fig. 13, lies on one side of the line (f(x)>0), the perceptron will output 1, and if on the line, or on the other side (f(x)<0), it will output 0 (assuming the Heaviside step activation function is used). Thus, a line, that separates perfectly the training patterns, represents correctly functioning perceptron (& vise versa). Dr. I. Jordanov 33 Perceptron Learning as a Minimization Problem While the sign of the net is crucial for the produced output (whether the perceptron will fire or not), the modulus (magnitude) of this function shows how far from the decision boundary the considered input x = (x0, x1,…, xn) is. 13/09/2012 This helps us to evaluate how good the weight vector w = (w0, w1,…, wn) values are. Dr. I. Jordanov 34 3 x2 2 1 x1 Fig. 14. Decision surfaces (line 1 and line 2) with two misclassified patterns. The distances are given in blue. Line 2 is better than line 1 (smaller sum of distances, but still not a solution). Line 3 (green) is one possible solution. (Assume, e.g., class1 (o) –”fat people”; class2 (●) - “thin people”; (x1 – body weight, x2 – body height). 13/09/2012 Dr. I. Jordanov 35 If we define perceptron objective function J (w), as a sum of the distances (Fig. 14, drawn in blue) to the decision surface of the misclassified input vectors (in other words, the sum of the errors): J ( w) n wi xi w x xX i 0 xX where the weight vector is w = (w0, w1,…, wn), and x is a subset of the training patterns X, misclassified by this set of weights (in Fig.14, x is 2 misclassified patterns). 13/09/2012 We aim to minimize the value of this function through changing the weight vector elements (obviously, if all inputs are classified correctly, then J (w) = 0). Dr. I. Jordanov 36 Perceptron convergence theorem (Rosenblatt) guarantees that a perceptron will find a solution state (a weight vector), if a solution exists. In other words, if a problem is linearly separable, a perceptron is able to classify it (Fig. 14). An example of a nonlinear problem, which cannot be solved by a single perceptron is the boolean XOR problem (Fig. 15). input 2 x2 : class 1, : class 2 1.5 1 0.5 0 0 0.5 1 1.5 x1 x1 x2 x1 XOR x2 0 0 0 0 1 1 1 0 1 1 1 0 input 1 Fig. 15. The XOR nonlinear problem. 13/09/2012 Dr. I. Jordanov 37 Multi-Layer Perceptrons (MLP) x0 1 x1 w1 ij 1 h0 w2ij h1 x2 h2 y1 y2 yk xn Input Layer (Layer 0) hm Hidden Layer (Layer 1) Output Layer (Layer 2) Fig. 16. A Multilayer Neural Network (MLP). 13/09/2012 Dr. I. Jordanov 38 Fig. 16 shows a fully connected (between the adjacent layers) feed-forward network (MLP). x0 x1 w0j x2 w1j w2j x3 w3j yj Node j Fig. 17. A node j of a backpropagation MLP. 13/09/2012 The weighted sum of the incoming inputs plus a bias term gives the net input of a node j (Fig. 17): Dr. I. Jordanov xj n xw i 0 i ij 39 Backpropagation Learning Algorithm The BP algorithm (also known as generalized delta rule) is used for supervised learning (when the outputs are known for given inputs). It has two passes for each input-output vector pair: forward pass - in which the input propagates through the net and an output is produced (http://www.youtube.com/watch?v=G3-ppsCCNww&NR=1 ); 13/09/2012 backward pass - in which the difference (error) between the desired and obtained output is evaluated (with an error function), this error function is minimised towards the weights of the net, starting backwards from the output layer to the input layer (http://www.youtube.com/watch?v=oxjt_xyjkrU&NR=1). Dr. I. Jordanov 40 We say that one epoch has been completed, once the BP has seen all the input-output vector pairs (samples, or patterns) and has adjusted its weights (batch mode). For a given experiment with P learning samples (inputoutput pairs), the difference between the produced (y) and desired, or targeted output (t) is estimated by means of an error (cost or energy) function, which usually is: 1 E P 2 P nL ( p) ( ti p 1 i 1 ( p) 2 y ) i where nL is the number of nodes in the output layer L. 13/09/2012 Sometimes, a square root of this error is used as a metric, which is called a root-mean-square error. Dr. I. Jordanov 41 Which is the ‘best fitted ’ model in Fig. 5 ? Fig. 18. ‘Best fitted ’ model (overfiting)? 13/09/2012 Dr. I. Jordanov 42 NN Learning and Generalisation The ability of a network to recognize and classify (separate, map) input patterns, that haven’t been shown during the training process, and produce reasonable outputs, is called Generalization. The aim of the learning process is to develop NN that can generalise. NN model development Training subset Validation subset NN generalisation (performance) evaluation Testing subset Fig. 19. Using the data set (split sample) for training and generalisation evaluation. 13/09/2012 Dr. I. Jordanov 43 Split sample (‘hold out’) method. Fig. 20. ‘Split sample’ method. 13/09/2012 Dr. I. Jordanov 44 One reasonable stopping criterion is to stop if the training error is small enough when the validation error starts to increase (‘early stopping’). % Error Validation Training Number of epochs Fig. 21. Training with validation (to avoid overfitting). 13/09/2012 Dr. I. Jordanov 45 Cross-validation – the data set (N samples) is divided into k subsets (folds) of approximately equal size (N/k ). Train the net k times, each time leaving out one of the subsets for testing. 1 ··· 9 10 Training 1 Testing ··· 9 10 Training Testing … 1 ··· 9 10 Training Testing Fig.22 K-fold cross-validation (k=10). 13/09/2012 Dr. I. Jordanov 46 During the iterative process of minimizing the error function, the BP convergence is guaranteed only in the vicinity of a minimum. BP can become entrapped in wrong extreme (local minimum), thus resulting in suboptimal training. Heuristic (stochastic) methods: Genetic Algorithms; Simulated Annealing; Taby Search; Clustering Methods; ACO (Ant Colony Optimization); PSO (Particle Swarm Optimization), and other approaches have been used to tackle this problem. 13/09/2012 Dr. I. Jordanov 47 To summarise, NN: are biologically inspired; learn from data (during training); are based on a network of artificial neurons; handle noisy data and are able to generalise (can cope with examples of problems that they have not experienced during the training). A cat that once sat on a hot stove will never again sit on a hot stove or on a cold one either … (Mark Twain). 13/09/2012 Dr. I. Jordanov 48