Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Molecular cloning wikipedia , lookup
Gene regulatory network wikipedia , lookup
RNA polymerase II holoenzyme wikipedia , lookup
Cell-penetrating peptide wikipedia , lookup
Bottromycin wikipedia , lookup
Polyadenylation wikipedia , lookup
Eukaryotic transcription wikipedia , lookup
Cre-Lox recombination wikipedia , lookup
Promoter (genetics) wikipedia , lookup
Community fingerprinting wikipedia , lookup
Non-coding DNA wikipedia , lookup
Epitranscriptome wikipedia , lookup
Transcriptional regulation wikipedia , lookup
RNA silencing wikipedia , lookup
List of types of proteins wikipedia , lookup
Vectors in gene therapy wikipedia , lookup
Amino acid synthesis wikipedia , lookup
Non-coding RNA wikipedia , lookup
Silencer (genetics) wikipedia , lookup
Molecular evolution wikipedia , lookup
Gene expression wikipedia , lookup
Point mutation wikipedia , lookup
Deoxyribozyme wikipedia , lookup
Artificial gene synthesis wikipedia , lookup
Biochemistry wikipedia , lookup
Expanded genetic code wikipedia , lookup
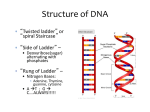
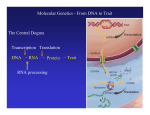
Objectives • • • Explain the "one gene–one polypeptide" hypothesis. Trace the information flow from DNA to protein. Describe how amino acids are coded. Key Terms • • • • RNA (ribonucleic acid) transcription translation codon When you were younger, did you ever use codes to send secret messages to your friends? Your first codes might have had simple rules such as using the alphabet backwards or using numbers to represent letters. Perhaps you developed codes with even more complex rules. Code-breaking can be an interesting challenge. Just think of the challenges scientists faced in breaking the genetic code. One Gene, One Polypeptide With the structure of DNA in mind, you can now put into molecular terms the concepts of genotype and phenotype you learned about in Chapter 10. An organism's genotype, its genetic makeup, is the sequence of nucleotide bases in its DNA. The molecular basis of the phenotype, the organism's specific traits, lies in proteins and their wide variety of functions. What is the connection between the DNA that defines the genotype and the proteins that, along with environmental influences, determine the phenotype? The major breakthrough in demonstrating the relationship between genes and proteins came in the 1940s. American geneticists George Beadle and Edward Tatum worked with the orange bread mold Neurospora crassa. Beadle and Tatum studied mutant strains of the mold that were unable to grow on the usual nutrient medium. Each of these mutant strains turned out to lack a single enzyme needed to produce some molecule the mold needed, such as a vitamin or an amino acid. Beadle and Tatum also showed that each mutant was defective in a single gene. Their research led them to propose the "one gene–one enzyme" hypothesis. This hypothesis states that the function of an individual gene is to dictate the production of a specific enzyme. Since then, scientists have learned that some genes actually dictate the production of a single polypeptide, which may make up part of an enzyme or another kind of protein. Beadle and Tatum's hypothesis is now generally stated as one gene–one polypeptide. Information Flow: DNA to RNA to Protein The language of genes is written as a sequence of bases along the length of a DNA chain. If the bases are the language's letters, each gene is like a sentence. Specific strings of bases make up each gene "sentence" on one DNA strand. What is the connection between these genes and the polypeptides in a cell? The answer involves RNA, another kind of nucleic acid with a structure similar to that of DNA. RNA (ribonucleic acid) is any nucleic acid whose sugar is ribose rather than the deoxyribose of DNA. Another difference between RNA and DNA is that RNA contains a nitrogenous base called uracil (U) instead of the thymine of DNA. Uracil is very similar to thymine, and pairs with adenine. The other components of RNA are the same as those for DNA. RNA typically forms a single, sometimes twisted strand, not a double helix like DNA. Several RNA molecules play a part in the intermediate steps from gene to protein. In the first step, DNA's nucleotide sequence is converted to the form of a single-stranded RNA molecule in a process called transcription (Figure 11-12). This "transcribed" message leaves the nucleus and directs the making of proteins in the cytoplasm, while the DNA remains in the nucleus. Figure 11-12 Information flows from gene to polypeptide. First, a sequence of nucleotides in DNA (a gene) is transcribed into RNA in the cell's nucleus. Then the RNA travels to the cytoplasm where it is translated into the specific amino acid sequence of a polypeptide. When a reporter transcribes a speech, the language remains the same. However, the form of the message changes from spoken language to written language. Similarly, when DNA is transcribed, the result is RNA—a different form of the same message. The next step, however, does require changing languages. Much as English can be translated into Russian, genetic translation converts nucleic acid language into amino acid language. The flow of information from gene to protein is based on codons. A codon is a three-base "word" that codes for one amino acid. Several codons form a "sentence" that translates into a polypeptide. The Triplet Code What are the rules for translating the nucleotide sequence of RNA into an amino acid sequence? In other words, which codons are translated into which amino acids? American biochemist Marshall Nirenberg began cracking this code in the early 1960s. He built an RNA molecule that only had uracil nucleotides, called "poly U." (Recall that RNA has U instead of T.) Because it contained only uracil nucleotides, it contained only one type of codon: UUU, repeated over and over. Nirenberg added poly U to a test-tube mixture containing all 20 amino acids, plus the enzymes and other chemicals required for building polypeptides. The result was translation of the poly U into a polypeptide consisting entirely of a single kind of amino acid: phenylalanine. Nirenberg concluded that the RNA codon UUU codes for the amino acid phenylalanine (Phe). Using similar methods, Nirenberg and others determined the amino acids represented by each codon. As Figure 11-13 shows, 61 of the 64 triplets code for amino acids. Notice that some amino acids are coded for by more than one codon, but no codon represents more than one amino acid. For example, codons UUU and UUC both specify phenylalanine, and neither of them ever codes for any other amino acid. The three codons that do not code for amino acids are "stop codons" that come at the end of each gene sequence. Figure 11-13 Each codon stands for a particular amino acid. (The table uses abbreviations for the amino acids, such as Ser for serine.) The codon AUG not only stands for methionine (Met), but also functions as a signal to "start" translating an RNA transcript. There are also three "stop" codons that do not code for amino acids, but signal the end of each genetic message. This same genetic coding system is shared by almost all organisms. In experiments, genes can be transcribed and translated after being transferred from one species to another, even when the species are as different as a human and a bacterium! The universal nature of the genetic code suggests that it arose very early in the history of life and has been passed on over time to all the organisms living on Earth today. Concept Check 11.4 1. How did Beadle and Tatum's research result in the "one gene–one polypeptide" hypothesis? 2. Which molecule completes the flow of information from DNA to protein? 3. Which amino acid is coded for by the RNA sequence CUA? 4. List two ways RNA is different from DNA.