Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Genetic studies on Bulgarians wikipedia , lookup
Molecular Inversion Probe wikipedia , lookup
DNA paternity testing wikipedia , lookup
Fetal origins hypothesis wikipedia , lookup
Pathogenomics wikipedia , lookup
Metagenomics wikipedia , lookup
Nutriepigenomics wikipedia , lookup
Non-coding DNA wikipedia , lookup
Site-specific recombinase technology wikipedia , lookup
Genomic library wikipedia , lookup
Designer baby wikipedia , lookup
Hardy–Weinberg principle wikipedia , lookup
Pharmacogenomics wikipedia , lookup
Genetic drift wikipedia , lookup
Whole genome sequencing wikipedia , lookup
Genetic engineering wikipedia , lookup
Human genome wikipedia , lookup
History of genetic engineering wikipedia , lookup
Medical genetics wikipedia , lookup
Behavioural genetics wikipedia , lookup
Quantitative trait locus wikipedia , lookup
Human Genome Project wikipedia , lookup
Genome evolution wikipedia , lookup
Genome editing wikipedia , lookup
Population genetics wikipedia , lookup
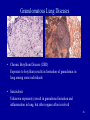
Heritability of IQ wikipedia , lookup
SNP genotyping wikipedia , lookup
Genetic testing wikipedia , lookup
Genealogical DNA test wikipedia , lookup
Genome (book) wikipedia , lookup
Microevolution wikipedia , lookup
Human genetic variation wikipedia , lookup
Design and Analysis of Genome-Wide Association Studies Workshop on Statistical Genetics and Genomics February 12, 2009 Tasha E. Fingerlin Departments of Epidemiology and Biostatistics & Informatics Colorado School of Public Health University of Colorado Denver 1 Today • Goal of a genetic association study • Rationale for genome-wide association studies • Design and analysis considerations for GWAs • Application to two clinically similar granulomatous lung diseases 2 Complex Traits - Multifactorial Inheritance Genetic Variants Trait Trait Non-genetic factors • Examples – – – – – Some cancers Type 1 diabetes Type 2 diabetes Alzheimer disease Inflammatory bowel disease - Schizophrenia - Cleft lip/palate - Hypertension - Rheumatoid arthritis - Asthma 3 Genetic Association Studies • Short-term Goal: Identify genetic variants that explain differences in phenotype among individuals in a study population – Qualitative: disease status, presence/absence of congenital defect – Quantitative: blood glucose levels, % body fat • If association found, then further study can follow to – Understand mechanism of action and disease etiology in individuals – Characterize relevance and/or impact in more general population • Long-term goal: to inform process of identifying and delivering better prevention and treatment strategies 4 DNA Variation • >99.9 % of the sequence is identical between any two chromosomes. - Compare maternal and paternal chromosome 1 in single person - Compare Y chromosomes between two unrelated males • Even though most of the sequence is identical between two chromosomes, since the genome sequence is so long (~3 billion base pairs), there are still many variations. • Some DNA variations are responsible for biological changes, others have no known function. • Alleles are the alternative forms of a DNA segment at a given genetic location. • Genetic polymorphism: DNA segment with 2 common alleles. 5 Single Nucleotide Polymorphisms: SNPs • SNPs – DNA sequence variations that occur when a single nucleotide is altered A T G A C A G G C A T G A C A T G C • Alleles at this SNP are “G” and “T” • SNPs are the most common form of variation in the human genome • SNPs catalogued in several databases 6 Genotypes and Haplotypes • Genotype: pair of alleles (one paternal, one maternal) at a locus Maternal A T G A C A G G C Paternal A T G A C A T G C Genotype for this individual is GT • Haplotype: sequence of alleles along a single chromosome Maternal A T G C C A T G C Paternal A T G A C A T G C Genotypes for this individual (vertical) : CA and TT Haplotypes (horizontal): CT and AT 7 Scope of a Genetic Association Study • Candidate gene – Known functional variants – Variants with unknown function in exons, introns, regulatory regions • Linkage candidate region * Sabeti PC et al. (2002). Nature 419: 832-837 – Functional variants, or those with unknown function in candidate genes – More general coverage of region using many markers • Genome-wide – Test for association with hundreds of thousands (millions) of SNPs spread across the entire genome. – Many design strategies possible for distributing markers 8 Genome-Wide Association Studies Rationale: • Linkage analysis using families takes unbiased look at whole genome, but is underpowered for the size of genetic effects we expect to see for many complex genetic traits. • Candidate gene association studies have greater power to identify smaller genetic effects, but rely on a priori knowledge about disease etiology. • Genome-wide association studies combine the genomic coverage of linkage analysis with the power of association to have much better chance of finding complex trait susceptibility variants. 9 Why are They Possible Now? Genotyping Technology: • Now have ability to type hundreds of thousands (or millions) of SNPs in one reaction on a “SNP chip.” The cost can be as low as $200-$300 per person. • Two primary platforms: Affymetrix and Illumina. Design and analysis: • Availability of SNP databases, HapMap, and other resources to identify the SNPs and design SNP chips. • Faster computers to carry out the millions of calculations make implementation possible. 10 Design and Analysis Strategies: Moving Target • A genetic factor is like any other potential risk factor and the same study design and analysis principles hold – in addition to those specific to GWAs. • Standard case-control (matched or unmatched), cohort-based quantitative trait and longitudinal designs are common. • In what follows, I will talk about current ideas and methods, with a focus on assumptions and quality control. • Focus today is on case-control design, but many of the principles apply to other designs. 11 SNP Chips: Number and Placement of SNPs • A “typical” SNP chip has at least 317,000 SNPs distributed across the genome. Newest: ~1 million. • The newest chips can also measure (directly or indirectly) some types of copy number variation. • We do not directly measure genotypes at all genetic polymorphisms, but rely on association between the polymorphisms we do assay and those which we do not assay. • SNP-SNP association, or linkage disequilibrium, is fundamental to our ability to sample the whole genome with relatively few SNPs. 12 Linkage Disequilibrium (LD) • Linkage disequilibrium: the non-random association of alleles at linked loci. • A measure of the tendency of some alleles to be inherited together on haplotypes descended from ancestral chromosomes. A T G A C A A G C A T C A C A T G C • If these where the only two haplotypes in the population, then alleles G and A ( C and T) are in perfect linkage disequilibrium. • If we genotype the first SNP, we know what the alleles are at the second SNP. 13 • In general, LD between two SNPs decreases with physical distance • Extent of LD varies greatly depending on region of genome • If LD strong, need fewer SNPs to capture variation in a region 14 www.hapmap.org 15 HapMap • Multi-country effort to identify, catalog common human genetic variants. • Developed to better understand and catalogue LD patterns across the genome in several populations. • Genotyped ~4 million SNPs on samples of African, east Asian, European ancestry. • All genotype data in a publicly available data base. • Can download the genotype data – Able to examine LD patterns across genome – Can estimate approximate coverage of a given SNP chip • Can represent 80-90% of common SNPs with ~300,000 tag SNPs for European or Asian samples ~500,000 tag SNPs for African samples 16 Case and Control Selection • Case and control samples may be population-based • Cases and controls may be chosen to increase magnitude of contrast Case sample may be selected to be enriched for predisposing variant(s) - Family history - Early age of onset - Increased severity of disease Control sample may be selected to be “very healthy” or “super controls” - E.g. for type 2 diabetes, may select individuals who have normal response to glucose at age 70 - Control selection just as important (and tricky) as for any case-control study. 17 Testing for Genetic Association with Disease • Question of interest: Are the alleles or genotypes at a genetic marker associated with disease status? • Use usual statistical machinery get estimates of measures of association and to test for association for each of the SNPs. • One typical approach: Test for association between having 0, 1 or 2 copies of rare allele at a SNP using Cochran-Armitage test for trend. 18 Pearson, T. A. et al. JAMA 2008;299:1335-1344. Interpreting the Statistical Results • Testing for association at each of hundreds of thousands of markers dictates that traditional statistical significance thresholds (e.g. =.05) not appropriate. • That aside (more in a few minutes), if you identify a SNP that is significantly associated with disease, there are three possibilities: – There is a causal relationship between SNP and disease – The marker is in linkage disequilibrium with a causal locus – False positive • Many potential sources of systematic errors that might lead to false positive results. • Genotyping quality control issues particularly important. 19 Confounding by Ancestry (a.k.a. Population Stratification) • Control selection critical as always • Confounding by ancestry: Distortion of the relationship between the genetic risk factor and the outcome of interest due to ancestry that is related to both the frequency of the putative genetic risk factor and whether or not subject is a case or a control. Ancestry Genetic Risk Factor Case/Control Status 20 Population Stratification Cases Controls Genotype TT AT AA • Distribution of genotypes differs between cases and controls • Might conclude that allele A (or genotype AA) related to disease 21 Population Stratification Cases Controls Pop 1 Genotype Pop 1 TT AT AA Pop 2 Pop 2 • If cases and controls not well-matched ancestrally – Unequal distribution of non-disease-related alleles between cases and controls – Any allele more common in population with increased risk of disease may appear to be associated with disease 22 Population Stratification • Unequal distribution of alleles may result from – Sample made up of more than one distinct population – Sample made up of individuals with differing levels of admixture Parra et al. AJHG 63:1839, 1998 23 Using the GWA Data to Avoid Population Stratification • Several options exist to allow controlling for ancestry using markers across the genome • All based on idea that stratification should exist across the genome, and that we can use the information on the genome-wide markers to - estimate ancestry groups, remove extreme outliers, control for other variation - estimate inflation of test statistic and adjust all test statistics • In each case, assumes constant effect of ancestry, which may or may not be appropriate • Bottom line is that with genome of data, can do a very good job of understanding potential for and minimizing impact of population substructure. 24 Potential Solutions to Multiple Testing Issue • Bonferroni correction – Assume all tests performed are independent – Estimate number of independent polymorphisms in genome – Threshold often considered appropriate: 5x10-8. • Other less conservative allocation of experiment-wide over the genome – Perhaps spend more on linkage regions or for SNPs in coding regions of gene • Permutation • Implementation for case-control study: permute case and control status, perform all tests record the most significant p-value among those tests and then re-permute case-control status and test again. Repeat many times. • P-value for most significant test is the proportion of permutations that had a “best” p-value as small or smaller than the one you observe with the observed data (the data with the right case and control labels). 25 Q-Q Plot • If points deviate (significantly?) from line of equality indicate that the two distributions are different. • Some will take point at which the observed p-values differ from the expected as the point to declare statistical significance. Important points: • Can have deviation from line that is indicative of violated assumptions (e.g. existence of population stratification) Figure from: G. Abecasis • In tails of distribution, have less information, and so might require large divergence from expected 26 Using Multiple Samples Rationale: Given the very large number of tests performed, use multiple samples as a way to reduce the expected number of false positive results at that end of the study. • Split-sample Approach: Rather than testing entire sample on entire genome, test for association with some proportion of your samples and then test some proportion of those markers in the rest of your samples*. • Independent samples Approach: Rather than split your own sample, use another independent sample. • In either case, can dramatically reduce number of false positive results while maintaining power. 27 Granulomatous Lung Diseases • Chronic Beryllium Disease (CBD) Exposure to beryllium results in formation of granulomas in lung among some individuals • Sarcoidosis Unknown exposure(s) result in granuloma formation and inflammation in lung, but other organs often involved 28 Hypothesis Sarcoidosis and CBD share genetic factors important in their similar granulomatous inflammatory pathways Disease Severity CBD Disease Risk Sarcoidosis 29 GWA : Preliminary data 30 Top Region for CBD p=10-11 31 Region Shared by both CBD and Sarcoidosis on 8p23.2 p=10 – 10 -2 -4 32 Other Important Topics of Present and Future • Imputation • Careful consideration of non-genetic factors • Investigation of interactions: gene-environment and gene-gene • Sequencing data 33 Acknowledgements Wake Forest University Carl D. Langefeld, PhD University of Michigan Michael Boehnke, PhD Goncalo R. Abecasis, PhD National Jewish Health Lisa Maier, MPH, MD Lori Silveira, MS 34