Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Cognitive neuroscience wikipedia , lookup
Multielectrode array wikipedia , lookup
Haemodynamic response wikipedia , lookup
Neuromarketing wikipedia , lookup
Neural oscillation wikipedia , lookup
Artificial general intelligence wikipedia , lookup
Recurrent neural network wikipedia , lookup
Neural engineering wikipedia , lookup
Feature detection (nervous system) wikipedia , lookup
Development of the nervous system wikipedia , lookup
Neurophilosophy wikipedia , lookup
Synaptic gating wikipedia , lookup
Optogenetics wikipedia , lookup
Neuroanatomy wikipedia , lookup
Channelrhodopsin wikipedia , lookup
Time series wikipedia , lookup
Neural modeling fields wikipedia , lookup
Neuroeconomics wikipedia , lookup
Holonomic brain theory wikipedia , lookup
Types of artificial neural networks wikipedia , lookup
Neuropsychopharmacology wikipedia , lookup
Neuroinformatics wikipedia , lookup
Biological neuron model wikipedia , lookup
Single-unit recording wikipedia , lookup
Metastability in the brain wikipedia , lookup
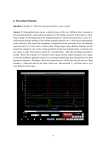
Neural Networks 16 (2003) 601–607 www.elsevier.com/locate/neunet 2003 Special issue Developments in understanding neuronal spike trains and functional specializations in brain regions Roberto A. Santiagoa, James McNamesb, Kim Burchielc, George G. Lendarisa,* b a NW Computational Intelligence Laboratory, System Science, Portland State University,1 USA Biomedical Signal Processing Laboratory, Electrical and Computer Engineering, Portland State University,2 USA c Department of Neurological Surgery, Oregon Health Sciences University,3 USA Abstract Understanding information processing at the neuronal level would provide valuable insights to computational intelligence research and computational neuroscience. In particular, understanding constraints on neuronal spike trains would provide indication about the type of syntactic rules used by neurons when processing information. A recent discovery, reported here, was made through analyzing microelectrode recordings (MER) made during surgical procedure in humans. Analysis of MERs of extracellular neuronal activity has gained increasing interest due to potential improvements to surgical techniques involving ablation or placement of deep brain stimulators, done in the treatment of advanced Parkinson’s disease. Important to these procedures is the identification of different brain structures such as the globus pallidus internus from the spike train being recorded from the intracranial probe tip during surgery. Spike train data gathered during surgical procedure from multiple patients were processed using a novel feature extraction method reported here. Distinct structures within the spike trains were identified and used to build an effective brain region classifier. The extracted features upon analysis provide some insight into the ‘syntactic’ constraint on spike trains. q 2003 Elsevier Science Ltd. All rights reserved. Keywords: Microelectrode recordings; Globus pallidus internus; Spike trains 1. Introduction Analysis of microelectrode recordings (MERs) of extracellular neuronal activity has importance from both a neurosurgical and neuroscience perspective. For neurosurgery, MER analysis offers potential benefits to surgical techniques involving ablation or placement of deep brain stimulators as in the treatment of Parkinson’s disease. From the neuroscience perspective, in vivo recordings of neurons provide an opportunity to analyze the patterns of spike trains and the interactions of neurons in near normal operational conditions. Fundamental to either of these pursuits understands the connection between the spike trains recorded in MERs and the neurons from which they are being recorded. Unlike in vitro experimentation, the cell type producing the recorded spike train is much harder to determine. From the neurosurgical perspective it would be of great advantage to * Corresponding author. E-mail address: [email protected] (G.G. Lendaris). 1 www.nwcil.pdx.edu 2 www.bsp.pdx.edu 3 www.ohsu.edu have real time algorithms that would reliably translate MERs into cell source classifications, which in turn could be used to provide accurate estimation and confirmation of intracranial probe placement. The work reported here was done for this end purpose but with the knowledge that any success on this front would also be important for computational neuroscience and for computational intelligence research. From the neuroscience perspective, the ability to identify cell types from recorded spike trains in vivo would provide some data about the unique information processing happening in a given brain region. Moreover, it would also provided some guidance for modifying current neuronal models such that they capture the information processing specializations found within specific brain regions. Much of the literature studying biological spiking behavior simultaneously treats dendritic processing as highly complex and treats spiking behavior as characterized by a distribution of spike intervals (Koch & Segev, 1989). Many of the spiking neuron models from computational intelligence research use many variations of integrate and fire models for connecting the dendritic processing to 0893-6080/03/$ - see front matter q 2003 Elsevier Science Ltd. All rights reserved. doi:10.1016/S0893-6080(03)00123-0 602 R.A. Santiago et al. / Neural Networks 16 (2003) 601–607 spiking behavior (Maass & Bishop, 1999). Other alternatives exist to integrate and fire, which are inspired both from the biology as well as mathematics (Gerstner & Kistler, 2002). Missing between these two approaches is the ability to ground the computational models onto the biological models such that the characteristics of information processing could be understood. More specifically, in order to get agreement between the computational intelligence models and computational neuroscience models it would be advantageous to estimate the type of distributions that not only correspond to biologically observed spike trains but that also provide some indication of the ‘syntactic’ constraint placed on the creation of spike trains from the computational perspective. Such distributions would take on the form of joint or conditional probability tables. In the research reported here this type of analysis is done to spike trains and is the source of the information for accurate identification of brain region from the spike train. In next few sections, the details of the spike train feature extraction algorithm are explained. This is followed a by a review of results on unseen data. In Section 5 the discussion returns to the connections between the feature of spike trains and functional specialization of brain regions. 2. Background The research reported here was performed in a neurosurgical context. Currently, Oregon Health Science University performs deep brain stimulation procedures. This procedure involves the use of a probe, which is slowly inserted into the patient’s brain in a stepwise manner. At each step a reading is taken from the probe, which is sensitive to the spiking of neurons within the local vicinity of the probe tip. The signal from the probe is then sampled and translated into an audio signal as well as visual presentation on an oscilloscope, which the surgeon uses to confirm the brain structure in which the probe tip is located. The insertion path is mapped out presurgically using magnetic resonance imaging. This process is very precise. As such, the signal from the probe is used only for confirmatory information. Still, at time of surgery, the only information available to the surgeon is the intracranial position of the probe tip and the signal recorded by the probe. As such, automated methods to translate this signal into useful information about the brain structures surrounding the probe tip would add another level of consistency and accuracy to deep brain stimulation procedures. Because of the speed and affordability of digital processing equipment, it now seems feasible to support and improve this surgical procedure. In order to do this, the probe data must first be digitally sampled and filtered for noise. Because this resultant digital signal is of several neurons firing simultaneously, it must undergo processing to isolate spike trains from individual neurons. Surgical recordings were processed postsurgically through a source separation algorithm to be detailed in McNames (2003). This algorithm not only separated the signals from each neuron but also identified spike occurrences. Thus the resulting individual spike train signal was an array of clock times with millisecond or better resolution indicating when a spike was detected. For this research there were a total of 140 spike trains each containing from 2 to 5 s worth of spike train recording. The set of data used was gathered during surgical procedure from 26 patients. These data came in two groupings nominally referred to as the Dirty Data Set (DDS) and the Starr Data Set (SDS). The DDS contained 93 spike trains from several patients which were randomly broken into two subsets, the training DDS (47 spike trains) and the test DDS (46 spike trains). The test DDS was isolated and used to test the effectiveness of the resulting algorithm developed from the training DDS and the Starr DDS. The reason for the label ‘Dirty’ is due to the unfortunate fact that the data from the DDS was labeled postsurgically; that is, the expert opinion about the brain structure source for each spike train was captured outside the context of the actual surgery. This method for labeling spike train data has the disadvantage of not having the depth and spatial location of the probe to assist with identification. The SDS was gathered under ideal conditions and represents ‘perfect’ examples of spike trains from individual neurons in the brain regions of interest. There were four major brain structures of interest: Globus Palidus Externus (GPE), Globus Palidus Internus (GPI), the Border (BRD) regions between GPE and GPI, and finally Tremor cells (TRM). This last area, TRM, is not a distinct brain structure but instead describes regions inside the GPI, where the cells fire in a tremor like manner and are linked to the physical tremoring common to Parkinson’s disease. Both data sets contained a large amount of spike trains from neurons in GPE. Exact numbers are reported in Section 6. 3. Approach Spike train analysis has been done for many reasons ranging from understanding the biology of single neurons to the type of medical application motivating this research. Spike train research, regardless of motivation, has the underlying presupposition that the characteristic of spike trains tell us something about the neuron, its operation and/or the information it processes. Most often, this type of research is done in settings, where both input and output of a neuron can be isolated. From this vantage point it is easy to gain a better understanding of the type of information processing being done by a single neuron. Understanding neuron processing involves understanding the mechanisms by which incoming signal is integrated and the process by which a new signal is created and transmitted to other neurons. Historically, these sub-processes have been understood by means of a rate-coding model. That is, a model, where neuronal processing is only concerned with the rate R.A. Santiago et al. / Neural Networks 16 (2003) 601–607 of spike arrival defined over some finite window. Unfortunately, simple rate coding models are not sufficient to explain fast response characteristics of many neuronal circuits, particularly those involved with visual processing (Koch, 1999). Put simply, there is significant presence of neuronal processing that involves dependency only on single spikes or on the time interval between spikes. This latter point is critical since it indicates that the time between spikes, the inter-spike interval (ISI), may contain useful information. This insight has fueled research into understanding methods by which neurons may encode and decode information in these ISIs (Koch, 1999; McNames, 2003). The models from this research are commonly referred to as temporal coding or correlation coding. More complex models have also been developed that describe information encoded across the spikes of more than one neuron. These models are commonly referred to as population coding and pulse coding which each have correlated and non-correlated forms (Koch, 1999). While these latter coding models are not of much use for single spike train analysis, the entire body of coding research provides information about where to look for information in the spike train of individual neurons (hereafter referred to as single spike trains). The use of coding research in this context is aimed at understanding the timeframe in which the physical properties of a neuron could contribute discernable information in an individual spike train. At the lower end, research supporting rate coding models for neuronal information processing have an upper end of 5– 10 ms as the effective length for information encoding/decoding. By way of explanation, since rate coded models rely essentially on counting the number of spikes that arrive during a time period, the critical time factor is the rate at which a spike signal decays on the neuronal membrane of the receiving neuron. As it turns out, the upper bound for the decay in this signal is around 10 ms (Koch, 1999). So assuming that rate coding is at least a partially correct model for neuronal processing, any contribution that an individual neuron makes to this process would be most discernable above this 10 ms threshold. Below this threshold, the spike train behavior is most attributable to the input signal being received from the dendrites. Finding an upper bound is very difficult in light of work in temporal and correlation coding. Precise firing patterns over 200 ms in length have been observed in the visual processing systems of the macaque monkey (Koch, 1999). Moreover, in laboratory setting, neurons can be stimulated to produce firing patterns that are precise and regular for almost indefinite periods. The period of these patterns are as short as 20 ms and as long as 300 ms. The structures involved in these spiking patterns involve both single spikes and sets of spikes separated by very small time intervals, known as bursts. Analysis of single spike and bursting patterns in vivo seem to indicate that 200 ms is the upper bound for discerning any real correlated pattern to spike times (Koch, 1999). In many contexts, though, 603 the nature of the spike train seems random with ISIs exhibiting a Poisson distribution. Some research indicates strongly that the stochastic nature of neuronal processing is far from stationary and may be highly dependent on input stimulus. Again, with the lack of neuronal input data, 200 ms is the apparent upper bound for pattern recognition in just the output spike train. So for the research reported here a window of 10– 200 ms was used for analyzing spike trains. Returning to the surgical context, an important clue was taken from the existing method of train source identification, listening. In terms of description, the sound produced by the MER from the surgical probe is roughly like static with much popping and whirring. Individual spike trains when converted to sound also have a similar characteristic. Discernable are regular patterns of popping intensity; roughly speaking, one can hear bursts and changes in spike frequency. This last comment seems to support research into spike bursting which seeks to isolate and characterize burst events. Given these clues it was hypothesized that within the 10– 200 ms window, there should exist discernable patterns of spiking that would happen repeatedly and ultimately would be the source of the characteristics discernable when listening to MER data. As a note, the search for a novel approach to feature extraction was motivated by the lack of strong results from research involving single statistics, power spectrums, smoothing, averaging and histogram approaches (McNames, 2003). These approaches have similar insights and motivations as the research presented here. Moreover, none of these approaches have been able to yield sufficient feature information from individual spike trains to provide a reliable automated spike source identification algorithm. 4. Feature extraction method The majority of the effort for the present research project was spent analyzing spike trains using a 10– 200 ms moving window. This analysis focused on developing a visualization technique for behavior in the moving window. In essence, the research sought features that made visually distinguishing different neuron types very easy. After many attempts only one feature extraction method worked very well and is described here. The method involved the use of two moving windows across a digital spike train (DST). The DST breaks up the duration of a spike train into fixed width intervals with each interval represented by a one or zero. One indicates a spike occurred during that time interval while a zero indicates no spike occurred during that interval. Two adjacent moving windows counted the number of ones in each window, producing a pair of integers. These pairs of integers were used to create a two dimensional histogram. This histogram was used to produce a surface plot, which revealed visually distinguishable features to each of the different types of neurons of interest. Figs. 1 – 4 are 604 R.A. Santiago et al. / Neural Networks 16 (2003) 601–607 Fig. 1. Example of GPI 2-D histogram. Fig. 3. Example of BRD 2-D histogram. representative examples of the type of histograms produced by this method. These particular histograms were produced using a sampling rate of 100 Hz and with window sizes of 9 bits. These were not the histograms that were ultimately used for the classification algorithm but because of resolution limitations these histograms demonstrate the types of features that were found and indicated that this method would be useful in the context of classification. It is important to note that while there is much symmetry in each graph, the localization of histogram activity for each type is unique. Moreover, these differing localizations and presence of asymmetries is what inspired looking at these histograms as estimates of joint and conditional distribution and the subsequently as possible indication of syntactic constraints which will be discussed later. Before moving on, a more detailed explanation of the algorithm is now provided Fig. 2. Example of GPE 2-D histogram. 1. The spike train is converted to a binary digital signal. This involves setting up an array of zeros, where each element represents a time interval. End to end these elements represent the duration length of a given spike train. So for example, each element of the array could represent 1 ms (i.e. the temporal spike train is sampled at 1000 Hz). If a spike train of 5.7 s were being analyzed, this would indicate that the array would have to be 5700 units in length. The array is initialized with all zeros. Continuing with the example, the first spike might occur at 0.1189 s. Translated into milliseconds this time would mean that the first spike of the spike train came after a 118.9 ms pause. Rounding up this number to 119, the 119th element of the array is changed to a one. 2. The binary digital signal is then sampled with two adjacent moving windows of finite length. So for example, a window length of 8 would gather all pairs of 8 bit binary words that occur in the DST. Fig. 4. Example of TRM 2-D histogram. R.A. Santiago et al. / Neural Networks 16 (2003) 601–607 3. The number of ones in each binary word is counted converting each pair of binary 8 bit words into a pair of decimal integers. So for example if a pair of eight digit words were 01110101 and 10011001, this would be converted to the decimal integer pair of 5 and 4. 4. These integer pairs are then binned together to create a two dimensional histogram. 5. The 0,0 entry in the histogram is then removed. This was done because the most common binary word pairs were all zeros, which yielded no information about the spike train. Additionally the histogram was normalized by dividing by the number of entries and doing a natural logarithmic conversion. This last step was used to avoid problems with histograms generated from different spike trains of significantly different durations. In some cases spike trains were as short as 2 s in duration. What bears mentioning is the nature of the features seen in the visualization of the histogram. In early experimentation, one dimensional histograms were created using a single moving window. These histograms did not provide enough information for visual identification. The one dimensional histogram is equivalent to looking at the distribution of spike rates. We recall that one of the models of neuron to neuron communication is a rate model that only cares about the number of spikes that occur during a finite time window. The one dimensional histogram essentially analyzes the spike train from that perspective. The two dimensional histogram analyzes the change in the rate of spike arrivals. Although not fully a temporal coding model it does reveal common changes in firing rate. So for example, a histogram created from a GPE spike train sampled at 1000 Hz with window size of 20 bits may have large numbers associated with the 4,18 and 10,10 bins. This would indicate that if four spikes occur in a 20 ms period it is very likely that it will be followed by 18 spikes in the next 20 ms period. Likewise if 10 spikes occur in a 20 ms period it is likely to be followed by the same rate of spiking. Again, in essence the two dimensional histogram analyzes the changes in spike rate. What it reveals is that changes in spike rate can uniquely characterize the spike trains of different neurons. More analysis is needed to understand all the information revealed in these histograms. 605 classifiers do not provide any easy methods for predicting performance on unseen test data. Unlike linear methods that provide characterizations associated with bias and variance, neural networks do not have any analog to these informative statistics. Neural networks were applied to this problem and were found to generalize very poorly. Instead, a support vector machine was employed. Support vector machines have gained much popular acclaim. In essence, they provide a method for calculating optimal hyperplanes for separating points in feature space. In the context of this project, the feature space is the set of values from the histogram. Returning to the example of the histogram created using 1000 Hz sampling rate and 20 bit window, each histogram has 21 £ 21 ¼ 441 values. These 441 values form a single point in the feature space into which the support vector machine will place hyperplanes to draw boundaries between the points representing GPI, GPE, BRD and TRM cells. More detailed discussion on the operation of support vector machines for classification can be found in Haykin (1999). The application of support vector machines was very successful as will be discussed in Section 6. A set of support vector MATLAB libraries from Ohio State University were used (Ma, Zhao & Ahalt, 2002). 6. Results Because the test DDS was held separate, early results were generated using a leave one out cross validation method. The support vector classifier was computationally very efficient making this form of testing possible. The first cross validation was performed with the SDS. The spike trains from the SDS were sampled at 400 Hz to create spike trains and a 20 bit window size was used. Table 1 shows a confusion matrix summarizing the results from the cross validation. The results are perfect. As stated before, the SDS was collected under ideal conditions and represents a ‘perfect’ set of spike train recordings. As such this result indicates that enough features are extracted in the rate change histogram to perform accurate classification in ideal circumstances. Next, the same cross validation was performed with the training DDS. This data was not gathered under ideal 5. Application of support vector machines The algorithm just described performs well at the task of feature extraction. In order to make this feature extraction applicable to the surgical context it was necessary to choose some form of classifier. Many linear and non-linear classifiers exist. Among the most popular non-linear classifiers that exist are neural networks. While neural networks are effective in many contexts, they often fall short in being able to generalize, or generalize in predictable manners. What is meant by this is that neural network Table 1 Results of leave one out cross validation testing with the dirty data set Actual Predicted GPE GPE GPI BRD TRM 31 1 2 2 GPI BRD TRM 2 2 1 5 1 606 R.A. Santiago et al. / Neural Networks 16 (2003) 601–607 Table 2 Results from test of classification algorithm on unseen data Actual GPE GPI BRD TRM Predicted GPE GPI 30 2 6 BRD TRM 2 3 3 conditions and it is known that at least one of the spike trains is labeled incorrectly. Still, the DDS has some characteristics of data that would be encountered in the surgical context. As such it provides a good bench mark with respect to robustness of this classification method with respect to noise. Table 1 is a confusion matrix summarizing the results of this cross validation. Finally, the training DDS was used to create a support vector classifier that was applied to the testing DDS. Again, this data set was held independently and was not accessible during the development of the feature extraction algorithm and the subsequent development of the support vector classifier. The confusion matrix describing the classification results with the testing DDS is provided in Table 2. It is important to emphasize that the results in Table 2 are the result of a single pass through the unseen testing data. It is not a leave one out cross validation test as is shown in Tables 1 and 3. After cross validation, it seemed like the algorithm was performing in a consistent and accurate manner. As a final test, a set of completely unseen data was presented to the classifier. The classifier was ‘trained’ using data from both the Starr and the Dirty sets. The unseen data set was held by a separate person and was never seen by the researchers prior to the final testing. The classifier was only allowed one single attempt to classify this unseen data. The results of this final test are summarized in Table 2. It seems apparent that the rate change histogram provides efficient and effective feature extraction for spike trains. The ability to visually identify the different types of neurons was a strong indicator that it would be effective in an automated classification context. The application of support vector machines seems to support Table 3 Results of leave one out cross validation testing with the starr data set Actual Predicted GPE GPE GPI BRD TRM GPI BRD TRM 13 9 7 8 this conclusion. The cross validation results from the training DDS and the final results from the testing DDS strongly indicate the feature extraction is fairly resistant to noise but that additional work is needed to cope with irregularities in recorded data, the source of many of the misclassifications. These irregularities are caused by many conditions that are encountered during the surgical procedure. Overall, though, the preliminary results are strong enough to warrant much additional work in further developing this feature extraction technique. 7. Discussion Returning to the neuroscience perspective, it is important to seek an explanation as to why this type of classification should even be possible. While it seems that the underlying cellular mechanisms for actions potentials (spikes) are well understood, what is not understood is their role in the processing of information beyond the most general description as a method to transmit information from one cell to another. By way of analogy, understanding the significance of neuron spiking is like trying to understand the significance of transistor switching in digital microprocessors without having an understanding of digital computing theory. More to the point, what these regular patterns indicate about the cells of interest is very ambiguous. Along these lines there seem to be two general hypothesis that could be explored. First, it might be possible that neurons by their physiology have a specific spiking pattern, which is activated when the membrane potential reaches a threshold. This is slightly different that the standard integrate and fire models of neurons since it includes the ability of neurons to not just simply fire but to fire specific temporal patterns that show conditional statistical regularity. This would provide a foundation for why the histogram visualization shown before should have such consistency. This model fails, though, to take into account any significant sensitivity to incoming signal. If the recorded spike trains represent primarily the effect of incoming signals, then it implies that regions of the brain have the ability to consistently produce spiking patterns, which are common among all the cells within a region. If this model is true then it would also suggest that the recorded spike trains represent functional specialization within a region. But this model, in the extreme, would suggest functional specialization independent of cell physiology which seems unlikely given what is known about the cell types studied here. Not enough data exists yet to firmly conclude that either of these models (or some other form in between) is truly correct. This in turn points to deeper research issues surrounding both the nature of what MERs represent and how ablation and stimulation is actually affecting circuits in the brain as understood from a systemic neurophysiological R.A. Santiago et al. / Neural Networks 16 (2003) 601–607 level and not just a behavioral model perspective. The fact that such regular patterns can be discerned in these recorded spike trains indicates that it might be possible to develop neuronal population models that more closely described and explain the functioning of these brain regions. Further research will look to extend this algorithm to cell types found in the substantia nigra which are much more challenging to recognize. Related research will seek to move these and other source identification techniques into the surgical context to asses their impact on the effectiveness of ablation and deep brain stimulation procedures. Still, further research will also seek to ground these methods in the physiology of neuron populations in search of a clearer understanding of these spike train patterns. Finally, after studying the types of histograms as shown in Figs. 1 – 4 it seemed reasonable to conclude that if these histograms are indeed unique to brain region then they indeed did characterize the types of spiking patterns inherent to the information processing occurring in that brain region. In turn, if this were true then these same histograms could be looked at as conditional distributions. Assuming that spike trains are essentially binary digital communication between neurons then the proper syntactic input and output of the neurons within a given region is characterized by this estimated distribution. Returning to 607 the idea of studying digital processors without understanding digital computing theory, the uniqueness of the spike train syntax provides an indication of the type of instruction sets that are encoded into the operation of the neuron. This is a loose hypothesis but the current results seem to significantly support the feasibility of this type of analysis which is one of the foci of the continuing research. References Gerstner, W., & Kistler, W. (2002). Spiking neuron models. Cambridge, UK: Cambridge University Press. Haykin, S. S. (1999). Neural networks: A comprehensive foundation. Upper Saddle River, NJ: Prentice Hall. Koch, C. (1999). Biophysics of computation: Information processing in single neurons. New York, NY: Oxford University Press. Koch, C., & Segev, I. (1989). Methods in neuronal modeling: From synapses to networks. Cambridge, MA: MIT Press. Ma, J., Zhao, Y., Ahalt, S (2002). OSU SVM Classifier Matlab Toolbox (ver. 3.00). http://eewww.eng.ohiostate.-edu/maj/osu_svm/ Maass, W., & Bishop, M. (1999). Pulsed neural networks. Cambridge, MA: MIT Press. McNames, J. (2003). Microelectrode signal analysis techniques for improved localization. Microelectrode recordings in movement disorder surgery. New York, NY: Thieme Medical Publishers.