Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Histone acetylation and deacetylation wikipedia , lookup
Community fingerprinting wikipedia , lookup
RNA interference wikipedia , lookup
Cre-Lox recombination wikipedia , lookup
Transcription factor wikipedia , lookup
List of types of proteins wikipedia , lookup
Gene regulatory network wikipedia , lookup
Genetic code wikipedia , lookup
Molecular evolution wikipedia , lookup
Endogenous retrovirus wikipedia , lookup
RNA silencing wikipedia , lookup
Two-hybrid screening wikipedia , lookup
Non-coding DNA wikipedia , lookup
Point mutation wikipedia , lookup
Polyadenylation wikipedia , lookup
Messenger RNA wikipedia , lookup
Nucleic acid analogue wikipedia , lookup
Artificial gene synthesis wikipedia , lookup
Deoxyribozyme wikipedia , lookup
Biosynthesis wikipedia , lookup
Non-coding RNA wikipedia , lookup
RNA polymerase II holoenzyme wikipedia , lookup
Promoter (genetics) wikipedia , lookup
Eukaryotic transcription wikipedia , lookup
Gene expression wikipedia , lookup
Epitranscriptome wikipedia , lookup
TARTU UNIVERSITY
FACULTY OF BILOGY AND GEOGRAPHY
DIFFERENT ASPECTS OF GENE REGULATION
Sten Ilmjärv
TARTU 2005
2
TABLE OF CONTENT
TABLE OF CONTENT ...........................................................................................................................2
GLOSSARY .............................................................................................................................................3
INTRODUCTION....................................................................................................................................4
1.
THE GENE .....................................................................................................................................5
2.
GENE TRANSCRIPTION .............................................................................................................6
3.
2.1
Transcription initiation ..........................................................................................................6
2.2
Transcription elongation........................................................................................................7
2.3
Transcription termination ......................................................................................................7
mRNA TRANSLATION ................................................................................................................9
3.1
Translation initiation .............................................................................................................9
3.2
Translation elongation and termination ...............................................................................10
4.
DNA REPLICATION...................................................................................................................11
5.
RNA SPLICING ...........................................................................................................................12
6.
PROMOTERS...............................................................................................................................14
7.
ENHANCERS, INSULATORS, SILENCERS & TANSCRIPTION FACTOR ..........................16
8.
miRNA..........................................................................................................................................18
REFERENCE .........................................................................................................................................19
Tartu 2005
3
GLOSSARY
•
Eukaryotes: Organisms (ranging from yeast to humans) which have nucleated cells.
•
Gene expression: The process by which a gene's coded information is converted into the
structures present and operating in the cell. Expressed genes include those that are transcribed into
mRNA and then translated into protein and those that are transcribed into RNA but not translated
into protein (e.g., transfer and ribosomal RNAs).
•
Phenotype1: The observable traits or characteristics of an organism, for example hair colour,
weight, or the presence or absence of a disease. Phenotypic traits are not necessarily genetic.
•
Prokaryotes: Organisms, namely bacteria and blue green algae, characterized by the lack of a
distinct nucleus.
•
snRNA2: an abundant class of eukaryotic RNA found in the nucleus, usually less than 300
nucleotides long but excluding ribosomal or transfer RNA of this size; most occur as
ribonucleoproteins and they appear to play a role in processing of heterogeneous nuclear RNA.
•
sRNA3: A non-coding RNA (ncRNA) is any RNA molecule that functions without being
translated into a protein. A commonly used synonym is small RNA (sRNA). Less-frequently used
synonyms are non-messenger RNA (nmRNA), small non-messenger RNA (snmRNA), and
functional RNA (fRNA). The DNA sequence from which a non-coding RNA is transcribed is often
called an RNA gene or non-coding RNA gene.
•
tRNA4: Transfer RNA (abbreviated tRNA) is a small RNA chain (74-93 nucleotides) that transfers
a specific amino acid to a growing polypeptide chain at the ribosomal site of protein synthesis
during translation.
•
Protein5: A molecule composed of amino acids linked together in a particular order specified by a
gene's DNA sequence. Proteins perform a wide variety of functions in the cell; these include
serving as enzymes, structural components, or signalling molecules.
•
Anticodon6: a set of three tRNA nucleotides that binds to the codon.
•
Ribosome7: A cytoplasmic cellular structure composed of ribonucleic acid and protein that
functions in the synthesis of protein. Ribosomes interact with messenger RNA and transfer RNA to
join together amino acid units into a polypeptide chain according to the sequence determined by
the genetic code. [24]
•
Primer8: A primer is a nucleic acid strand (or related molecule) that serves as a starting point for
DNA replication. A primer is required because most DNA polymerases (enzymes that catalyze the
replication of DNA) cannot begin synthesizing a new DNA strand from scratch, but can only add
to an existing strand of nucleotides. [25]
1
http://www.pxe.org/virtpat/docs/genetics/glossary.html
http://www.mercksource.com/pp/us/cns/cns_search_results.jsp
3
http://en.wikipedia.org/wiki/SRNA
4
http://en.wikipedia.org/wiki/TRNA
5
http://www.hhmi.org/genetictrail/glossary.html
6
http://genome.pfizer.com/glossary.cfm
7
http://www.amfar.org/cgi-bin/iowa/bridge.html
8
http://en.wikipedia.org/wiki/Primer
2
Tartu 2005
4
INTRODUCTION
The purpose of this paper is to give a simple overview about biological aspects and
features of gene regulation. That includes DNA transcription regulation, RNA
translation regulation, miRNAs, promoter region specialities and more.
There are many ways to manipulate with genes, so therefore the scale is very wide
and it differs between different subjects as human, bacteria, viruses and more. For
example some viruses do not have DNA as their infinite source of existence but
instead they have RNA. And prokaryotes don’t have a nucleus, so therefore they do
not need to transport their DNA products like mRNA out of the nucleus to the
cytoplasm. And even more, products of one cell can influence other cells, so overall it
is very hard to follow all the directions, possibilities and mechanisms of gene
regulation.
Tartu 2005
5
1.
THE GENE
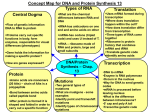
First of all what is a gene? The widest spread version explains gene as the most
fundamental physical and functional unit of heredity. This means that genes make us
who we are and what we can do. The gene is a segment of DNA located in a specific
site on a chromosome and it operates the formation of an enzyme or other proteins.
The fundamental dogma of molecular biology states that DNA produces RNA, which
in turn produces proteins. The action of the protein then produces the phenotype.
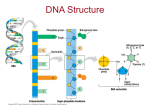
The gene and of course DNA (deoxyribonucleic acid) consists of nuclei acid, which
are as we all know A, T, C, and G. But the DNA has something else to it as well. A
strand of DNA contains as said genes, areas that control genes and areas that either
have no function or a function which we do not know about. In eukaryotic species,
very little of DNA actually encodes proteins and therefore the genes may be separated
by vast sequences of junk DNA. As well as there are non-coding sequences between
different genes, there can be such areas within the gene as well. These areas are called
introns, which can actually be many times longer then the gene itself. In the end
introns will be cut off and exons, the areas that code the protein, will be joined
together. This happens after transcription and before translation with pre-mRNA and
is called splicing.
Tartu 2005
6
2.
GENE TRANSCRIPTION
The genetic code of the DNA is made up of three letter nucleic acids which are
overall named as codon. In the end every codon is opposed by an amino acid. But one
amino acid can be formed by different codons which differ by their nucleic acid
sequence.
The first action in producing a protein from DNA is called transcription. The genes
that are transcribed together are part of a mutual operon. Also the regulative
sequences belong to that operon. Transcription is a process through which a DNA
sequence is enzymatically copied by RNA polymerase to produce a complementary
RNA. This will lead to formation of mRNA. The transcription is divided into three
stages: initiation, elongation and termination.
2.1
Transcription initiation
In the initiation stage the RNA polymerase specifically finds and binds to the DNA
promoter region, which enables the gene to be transcribed. There are different kinds
of RNA polymerases: Pol I transcribes the rRNA, Pol II the mRNA and Pol III
5sRNA genes, the snRNA genes and all the tRNA genes. In prokaryotic RNA
polymerase the enzyme consists of five polypeptides: two α subunits, β, β´ and σ
subunit. The transcription elongation is carried through by the RNA polymerase
apoenzyme (α2, β, β´). α subunits are responsible for the assembling of the apoenzyme
and they can also interact with transcription activators. β subunit has polymerase
activity and β´ binds to the DNA strain. The belonging of σ factor in the RNA
polymerase carries out the specific recognition and binding on the promoter area. Due
to the difference in σ factors it is possible for the RNA polymerase binding on
different promoter sequences. On the elongation the σ is released.
The RNA polymerase responsible for the transcription in eukaryotic cell is more
complicated and has more subunits to it. In eukaryotic cell, before binding the RNA
Pol II, the transcription factors have to bind on the promoter. This is not necessary in
prokaryotic cell, where transcription can start without transcription factors. There are
several conserved elements on the promoters which bind with RNA Pol II. Closest to
Tartu 2005
7
the transcription initiation sites are TATA-elements, which have the sequence of
TATAAAA and it starts somewhere about -33 nucleotides upstream from the
transcription starting point. The next conserved area in the promoter is CAAT
(CGCCAATCT), which is 80 nucleotides from transcription starting point. The first
transcription factor (TF) that binds to promoter is TFIID, which includes a protein that
connects with TBP (TATA-binding protein) and several smaller proteins associated
with TBP. Then TFIIA and TFIIB associate with the promoter. The fourth TF called
TFIIF binds first to the RNA polymerase and then they bind to other proteins which
all together makes up transcription initiation complex. The TFIIF is also responsible
for the dsDNA to detangle, in order to transcribe the DNA. Then after the initiation of
transcription comes transcription elongation.
2.2
Transcription elongation
In prokaryotic cell elongation is being catalyzed by RNA polymerase, which now is
without the sigma factor. The polymerisation speed of RNA is 40 nucleotides a
second. In the exact place where the transcription is taking place the DNA and RNA
are bind together along three nucleic acids. But the stability of the complex is still
related to RNA and DNA binding with polymerase. The elongation in eukaryotic cell
is quite similar to previous.
2.3
Transcription termination
The last process in transcription is termination. This takes place when RNA
polymerase meets with the death codon or the termination signal. Again this is
different in eukaryotes and prokaryotes. In prokaryotes the termination is either
dependant on Rho protein or not dependant on Rho protein. The last variant
terminators carry regions with high level of G:C, which are accompanied by 6 or more
pairs of A:T. The explanation for that is quite logical. The single stranded RNA forms
a secondary structure, which calls for the polymerisation to end. And if right after the
secondary structure there is a long sequence of only U nucleotides, then this helps the
dissociation from the transcription complex. This is due to the weak interaction
between nucleotide U and A. If the Rho protein is included in the termination process,
then the termination sequences are longer. In that case the Rho protein binds with the
growing RNA strain and when the termination point comes or polymerization slows
down, then the RNA is being dissociated from the complex by the Rho protein. In
Tartu 2005
8
eukaryotes the termination of RNA Pol III work is also Rho dependant or
independent. But the termination of Pol I and Pol II is different. RNA Pol I will stop
when it gets signal from 18 nucleotide length sequence where the terminator protein
has bind. The termination of Pol II is a bit more difficult. The early transcripts 3´ ends
are cut off. The termination takes part in 1000 to 2000 nucleotide towards the other
end. After the cut an enzyme called poly(A) polymerase adds to the 3´ end of the
RNA molecule a poly(A) tail. The poly(A) tails increase the stability of mRNA and
they also play a role in transporting the mRNA from nucleus to cytoplasm. The 5´ cap
is modified with adding the guanine nucleotide to the “front” of the pre-mRNA. This
modification is critical for recognition and proper attachment of mRNA to the
ribosome. It may be also important for other essential processes, such as splicing and
transport.
Tartu 2005
9
3.
mRNA TRANSLATION
The second part of protein making is translation process. Translation is protein
production from mRNA. Protein is the unit that is being formed thanks to translation
of mRNA. Similarly to transcription translation is carried in three different stages:
initiation, elongation and termination.
3.1
Translation initiation
The translation differs between eukaryotic and prokaryotic cells. Since prokaryotic
cells don’t have a nucleus, the mRNA can be translated at the same time as
transcription. In eukaryotic cell this is impossible, since translation is outside of
nucleus and the mRNA has to be ready for it to go to cytoplasm. The translation is
said to be polyribosomal when there is more than one active ribosome. When tRNA is
charged with the amino acid corresponding to its anticodon, it is called aminoacyltRNA. Also mRNA is always longer then the coding region. To initiate the translation
it is necessary for the small ribosomal unit to bind to the “start” codon on the mRNA.
This indicates the starting point where mRNA starts coding the protein. Most
commonly this protein is AUG, but alternative ones are common in prokaryotes.
Initiation consists of the reactions wherein the first aminoacyl-transfer RNA and the
mRNA are bound to the ribosome. The only transfer RNA (tRNA) capable of
initiating translation is a special initiator tRNA (tRNA), which carries the amino acid
methionine. The first reactions involve the formation of an initiation complex
consisting of methionyl-initiator tRNA bound to a 40S (measured in Svedbergs, in
which a higher S value indicates a greater rate of sedimentation and a larger mass)
ribosomal subunit. This reaction is catalyzed by the active form of eukaryotic
initiation factor 2 (eIF2-GTP), which binds the initiator Met-tRNA to the 40S
ribosomal subunit. Note that this binding occurs in the absence of mRNA. The
mRNA is added next. First, cap-binding protein eIF4E binds to the 7methylguanosine cap at the 5′ end of the message. Without this cap, the binding of
mRNA to the ribosomal subunit is often not completed (Shatkin, 1976, 1985), and
eIF4E is critical for the translation to proceed. However, there is less eIF4E than the
number of messages in the cell, so it is thought that each mRNA has to compete for
this cap-binding protein (Thach, 1992). Initiation factor 4A then complexes with
Tartu 2005
10
eIF4E and positions itself on a helical hairpin loop in the leader sequence of the
mRNA. The eIF4A (stimulated by eIF4B and ATP) unwinds the helix. This step can
be rate-limiting if the hairpin loop helix is hidden by some other stable secondary
structure. The 40S ribosomal subunit then travels down the message until it reaches
an AUG codon in the proper context. Kozak (1986) has shown that not just any AUG
will do. For the 40S ribosomal subunit to stop and initiate translation, the nucleotides
around AUG are also important. Kozak found the "optimum" sequence to be
ACCAUGG. The binding of the 40S subunit to the AUG of the message positions the
initiator tRNA over the AUG codon. Only after the mRNA has been properly
positioned on the small ribosomal subunit can the 60S ("large") ribosomal subunit
bind. This completes the initiation reaction. During this process, the GTP on eIF2 is
hydrolyzed to GDP. For the eIF2 to pick up a new initiator tRNA, it must be
regenerated to eIF-GTP by eIF2B.
3.2
Translation elongation and termination
The next step is elongation. Elongation involves the sequential binding of aminoacyltRNAs to the ribosome and the formation of peptide bonds between the amino acids
as they sequentially relinquish their tRNA carriers. As amino acids are joined
together, the ribosome travels down the message, thereby exposing new codons for
tRNA binding. The termination of protein synthesis takes place when one of the
mRNA codons UAG, UAA, or UGA is exposed on the ribosome. These nucleotide
triplets (called termination codons) are not recognized by tRNAs and hence do not
code for any amino acids. Rather, they are recognized by release factors, which
hydrolyze the peptide from the last tRNA, freeing it from the ribosome. The ribosome
separates into its two subunits, and the cycle of translation begins anew. In E. coli two
related proteins catalyze termination. They are specific for different sequences. RF-1
(release factor) recognises UAA and UAG; RF-2 recognises UGA and UAA.
Mutations in the RF genes reduce the efficiency of termination, as seen by an
increased ability to continue protein synthesis past the termination codon.
Tartu 2005
11
4.
DNA REPLICATION
Another important procedure that involves DNA is DNA replication, where exact
DNA is copied. In order for the DNA to replicate it has to be single stranded. In
eukaryotes DNA is double stranded, in prokaryotes and viruses it varies. The
segregation of DNA strands is catalyzed by DNA helicase. The synthesis is being
carried out with DNA polymerase which needs a primer. This is necessary for the
polymerase to be intact with the template strand. The enzyme that synthesises a
complementary strand from the RNA into DNA is called reverse transcriptase. In the
replication of DNA, results will be that one new strand is combined together with one
old strand because both of the olds strands serve as template strands during the
replication. The initiation of DNA replication is limited by the existence of specific
initiation regions called ori-regions. In difference with bacteria in eukaryotes there is
a lot of starting sites for replication. They are allocated all over the chromosome
appearing about every 100 000bp. In S. cerevisiae there have been isolated ARS
elements (Autonomously Replicating Sequences). They are about 50bp long A:T rich
sequences.
Tartu 2005
12
5.
RNA SPLICING
Most of eukaryotic genes contain non-coding sequences – introns. In order for the
formation of translative mRNA it is necessary for the splicing of introns and combing
of exons. But what is an intron and what is an exon has at that stage not yet been
decided. The decision is made during the splicing process. The regulation and
selection of splice sites is done by Serine/Arginine-residue proteins. Alternative
splicing is of great importance for genetics. This means that the old idea of one DNA
sequence coding one polypeptide is no longer correct. External information is needed
in order to decide which polypeptide is produced, given a DNA sequence and premRNA. It has been proposed that for eukaryotes it was a very efficient step forward
since information can be stored much more economically. There are four known
modes of alternative splicing: 1) Alternative selection of promoters – this is the only
method of splicing which can produce an alternative N-terminus domain in proteins.
In this case, different sets of promoters can be spliced with certain sets of other exons.
2) Alternative selection of cleavage/polyadenylation sites: this is the only method of
splicing which can produce an alternative C-terminus domain in proteins. In this case,
different sets of polyadenylation sites can be spliced with the other exons. 3) Exon
cassette mode: in this case, certain exons are spliced out to alter the sequence of
amino acids in the expressed protein.
But questions still arise: does splicing occur in a particular part of the nucleus, what
ensures that the ends of each intron are recognized in pairs so that the correct
sequence is removed from the RNA? Introns are removed from the nuclear RNAs of
higher eukaryotes by a system that recognizes only short consensus sequences
conserved at exon-intron boundaries and within the intron. This requires a
spliceosome. There are two splicing sites to cut the intron out: one is 5’ a.k.a. left
a.k.a. donor site and the other is 3’ a.k.a. right a.k.a. acceptor site. In the structural
protein coding genes the introns have in both ends very short conserved sequences.
There is 100% conservation on both sides next to introns. On the left side there is GT
and on the right side conserved area is AG. Inwards from these sites there is a less
conserved sequences. One of them is TACTAAC element, which is situated 30
nucleotides upstream from the 3´ splicing site. The nucleotides are of course different
in RNA. There are three ways to cut out introns: 1) in the case of tRNA precursors the
Tartu 2005
13
cuts are made by endonucleas and exons are bind together. The enzymes involved
recognize specifically pre-tRNA higher rank structures, not specific nucleotide
sequences. 2) In some pre-tRNA molecules the molecule itself catalyzes the splicing.
3) spliceosome is involved.
Tartu 2005
14
6.
PROMOTERS
A little more about promoters and the sequences they carry. A promoter differs from
other DNA sequence whose role is to be transcribed and later translated. The
information for promoter function is provided directly by the DNA sequence: its
structure is the signal. In comparison the expressed genes gain their meaning when
the information is transferred into the form of some other nucleic acid or protein. The
key question is that how the RNA polymerase recognises the specific promoter
sequence. Does the enzyme have an active site that distinguishes the chemical
structure of a particular sequence of bases in the DNA double helix? What are the
requirements for that binding?
In the bacterial genome the minimum length required by for unique recognition is
12bp. But the length increases with the size of the genome. Any shorter region is
likely to occur, just by chance, a sufficient number of additional times to produce
false signals. The sequence doesn’t have to be contiguous. There can be some
separation in the middle. So because of that the combined length of the sequence is
shorter, but since the distance of the separation itself provides a part of the signal it
doesn’t matter.
A sequence is called conserved when the essential nucleotide sequence is present in
all the promoters. Still, it doesn’t have to be conserved in every single position. A
consensus sequence is defined by aligning all known examples so as to maximize
their homology. For a sequence to be accepted as consensus, each base has to be
reasonably predominant at its position. What is actually happening is that there is still
a lot of irrelevant sequence in the binding site. But some short stretches within the
promoter are conserved, and they are critical for its function.
In the bacterial promoter there are four conserved features:
•
The startpoint is usually, 90% of the time, a purine, which is most commonly
the central base of CAT. But it’s not really an obligatory signal.
•
The next region is recognisable in almost all promoters. The bacterial -10
TATAAT element, also referred as -10 sequence, was the first promoter
element to be identified. The consensus can be summarized in the form
Tartu 2005
15
T80A95T50A60A50T96, where the numbers referrers the percentage occurrence of
the most frequently found base.
•
Another conserved hexamer is centred ~35 upstream of the starting point.
Hence
the
name
-35
sequence.
The
consensus
is
TTGACA
(T82T84G78A65C54A45).
•
The sequence between those two sequences is unimportant, but the distance is
critical in holding the two sites at the appropriate separation for the geometry
of RNA.
No element/factor combination is an essential component of the promoter, which
suggests that initiation by RNA polymerase II may be sponsored in many different
ways. A common feature is that inducible transcription factors bind to sequence
elements located upstream of the startpoint. In the end sequence components of the
promoter are defined operationally by the demand that they must be located close to
the startpoint and help the transcription initiation stage. But there is also sequences
called enhancers.
Tartu 2005
16
7.
ENHANCERS,
INSULATORS,
SILENCERS
&
TANSCRIPTION FACTOR
Enhancers are sequences which also stimulate initiation but that are located a
considerable distance from the startpoint. DNA may be coiled or otherwise
rearranged so that transcription factors at the promoter and at the enhancer interact to
form a large complex. Enhancers are often used on temporal regulation. The
components resemble those of the promoter. However the elements in enhancers are
very close together, but in promoters they could have been separated. The elements
functions the same but an enhancer does not need to be close to startpoint. Proteins
that bound to the enhancer elements also interact with the proteins from promoter
elements. The concept that the enhancer is distinct from the promoter reflects two
characteristics. The enhancer position relative to promoter can vary substantially and
it can function in either orientation. Enhancer can stimulate any promoter placed in its
vicinity. Elements analogous to enhancers which are called upstream activator
sequences (UAS) are found in yeast. As enhancers they can function in either
orientation but cannot function when located downstream from the startpoint. UAS
plays a regulator by binding with regulatory proteins that activates the genes
downstream.
Enhancer works upon the promoter nearest to it. A nearby enhancer is used to
increase the efficiency of promoters or if promoters lack specific regulation they
become active only when a nearby enhancer is specifically activated. If to remove
enhancer from its original place on the DNA and put it somewhere else, then normal
transcription can still be sustained as long as the enhancer is somewhere or anywhere
on the DNA molecule.
How is it possible for the enhancers to work at any distance or on both sides of the
startpoint? There are several possibilities: an enhancer could change the overall
structure of the template – for example, by influencing the density of supercoiling; it
could be responsible for locating the template at a particular place within the cell – for
example, attaching it to the nuclear matrix; an enhancer could provide an “entry site,”
a point at which RNA polymerase associates with chromatin. So in the end enhancers
can be seen as containing promoter elements that are grouped closely together, with
Tartu 2005
17
the ability to function at large distances from the startpoint. The essential role for
enhancers may be to increase the concentration of transcription factors in the vicinity
of promoter. The organisation of DNA must be flexible enough to allow the enhancer
and promoter to be closely located.
Elements that prevent the passage of activating or inactivating effects are called
insulators and have been identified in two circumstances. When an insulator is placed
between an enhancer and a promoter, it prevents the enhancer from activating the
promoter. This may explain how the action of an enhancer is limited to a particular
promoter. When an insulator is placed between an active gene and heterochromatin, it
protects the gene against the inactivating effect that spreads from the
heterochromatin.
Silencers behave like negative enhancers. Each silencer contains an ARS sequence
(an origin of replication) The ARS is bound by the ORC (the origin recognition
complex) that is involved in initiating replication. Mutations in ORC gene prevent
silencing, indicating that ORC protein binding at the silencer is required for silencing.
Any protein which is needed for the initiation of transcription but itself doesn’t
belong to RNA polymerase is called transcription factors. A factor may recognise
another factor, or may recognise RNA polymerase, or may be incorporated into an
initiation complex only in the presence of several other proteins.
Tartu 2005
18
8.
miRNA
miRNA is actually short for micro-RNA. It is usually 20-25 nucleotides long and is
thought to regulate the expression of other genes. miRNAs are RNA genes therefore
they are not translated into protein. miRNA is complementary to a part of one or more
messenger RNAs, usually at the site of 3´ UTR. The binding of the miRNA to the
mRNA inhibits protein translation. In some cases, the formation of the doublestranded RNA through the binding of the miRNA triggers the degradation of the
mRNA transcript, though in other cases it is believed that mRNA won’t be degraded.
Tartu 2005
19
REFERENCE
Internet pages:
1.
http://www.google.com/search?hl=en&lr=&oi=defmore&q=define:gene
2.
http://stemcells.nih.gov/info/glossary.asp
3.
http://en.wikipedia.org/wiki/The_Selfish_Gene
4.
http://www.google.com/search%3Fhl%3Den%26q%3Dfrom%2Bgene%2Binto%2Bprotein
5.
http://www.pxe.org/virtpat/docs/genetics/glossary.html
6.
http://en.wikipedia.org/wiki/Gene
7.
http://gslc.genetics.utah.edu/units/basics/transcribe/
8.
http://users.rcn.com/jkimball.ma.ultranet/BiologyPages/T/Transcription.html
9.
http://www.iephb.nw.ru/labs/lab38/spirov/hox_pro/pro-enh.html
10.
http://en.wikipedia.org/wiki/Promoter
11.
http://tymri.ut.ee/loengud/maia/gen1/Geneetika%201.htm#TRANSKR
12.
http://www.hhmi.org/genetictrail/glossary.html
13.
http://en.wikipedia.org/wiki/Translation_%28genetics%29
14.
http://www.devbio.com/article.php?ch=5&id=51
15.
http://opbs.okstate.edu/~melcher/MG/MGW2/MG242.html
16.
http://en.wikipedia.org/wiki/Alternative_splicing
17.
http://www.mercksource.com/
18.
http://depts.washington.edu/~genetics/courses/genet372/w2000Terms.html
19.
http://www.amnh.org/exhibitions/epidemic/glossary.html
Books:
•
“Genes VII” Benjamin Lewin, Oxford University Press, 2000
Tartu 2005