Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Nervous system network models wikipedia , lookup
Types of artificial neural networks wikipedia , lookup
Sensory cue wikipedia , lookup
Externalizing disorders wikipedia , lookup
Biology of depression wikipedia , lookup
Molecular neuroscience wikipedia , lookup
Vesicular monoamine transporter wikipedia , lookup
Activity-dependent plasticity wikipedia , lookup
Neurogenomics wikipedia , lookup
Optogenetics wikipedia , lookup
Aging brain wikipedia , lookup
Neuropsychopharmacology wikipedia , lookup
Central pattern generator wikipedia , lookup
Feature detection (nervous system) wikipedia , lookup
Eyeblink conditioning wikipedia , lookup
Neuroanatomy of memory wikipedia , lookup
Neurotransmitter wikipedia , lookup
Time perception wikipedia , lookup
Multi-armed bandit wikipedia , lookup
Synaptic gating wikipedia , lookup
Premovement neuronal activity wikipedia , lookup
Substantia nigra wikipedia , lookup
Neuroeconomics wikipedia , lookup
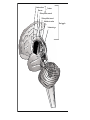
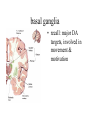
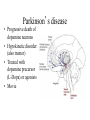
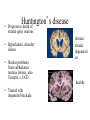
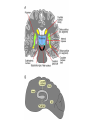
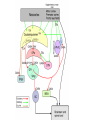
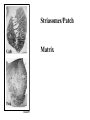
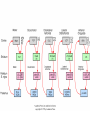
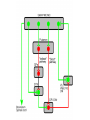
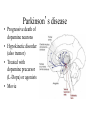
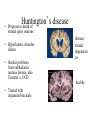
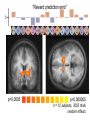
Basal Ganglia Caudate nucleus Putamen Striatum Globus pallidus, external Globus pallidus, internal Subthalamic nucleus Basal ganglia Substantia nigra basal ganglia • recall: major DA targets, involved in movement & motivation BG Disorders In humans, basal ganglia dysfunction associated with both hypokinetic and hyperkinetic movement disorders Hypokinetic akinesia bradykinesia rigidity Hyperkinetic chorea ballism tics A Parkinson’s Brainstem Parkinson’s disease • Progressive death of dopamine neurons • Hypokinetic disorder (also tremor) • Treated with dopamine precursor (L-Dopa) or agonists • Movie • Huntington’s disease Progressive death of striatal spiny neurons • Hyperkinetic disorder: chorea • Similar problems from subthalamic nucleus lesions, also Tourette’s, OCD • Treated with dopamine blockade disease: striatal degenerati on healthy Medium spiny neurons • Principal neuron type in striatum • Recipient of corticostriatal inputs • Extensive dendrites – each receives input from 10,000 fibers • Unusual: GABAergic (inhibitory) projections – Also collaterals (competitive network? for competition based on value?) Striasomes/Patch Matrix The corticostriatal projection • Input nucleus of basal ganglia: striatum • topographic projection from entire cortex (including sensory, motor, associative areas) – ultimately reciprocated • also dopamine Voorn et al 2004 Parkinson’s disease • Progressive death of dopamine neurons • Hypokinetic disorder (also tremor) • Treated with dopamine precursor (L-Dopa) or agonists • Movie • Huntington’s disease Progressive death of striatal spiny neurons • Hyperkinetic disorder: chorea • Similar problems from subthalamic nucleus lesions, also Tourette’s, OCD • Treated with dopamine blockade disease: striatal degenerati on healthy Parkinson’s treatment • Suggested by model, STN lesions (primates) & GPi lesions in humans alleviate PD symptoms – huge success of animal research, modeling • More recently, turned to reversible/tunable deep brain (STN) stimulation (DeLong 1990) Deep-brain stimulation for PD • Target subthalamic nucleus (usually) • High frequency rhythmic stimulation • Mechanism not entirely clear Model of BG disorders • • hypokinetic & hyperkinetic disorders caused by imbalance in direct/indirect pathways (Arbin et al. 1989; Alexander & Crutcher 1990) Dopamine excites striatal MSNs projecting to direct pathway and inhibits those projecting to indirect pathway (this is an oversimplification) (DeLong 1990) Model of BG disorders • • hypokinetic & hyperkinetic disorders caused by imbalance in direct/indirect pathways (Arbin et al. 1989; Alexander & Crutcher 1990) Dopamine excites striatal MSNs projecting to direct pathway and inhibits those projecting to indirect pathway (this is an oversimplification) Hypokinetic (Parkinson’s) (DeLong 1990) Hyperkinetic (Huntington’s) (DeLong 1990) The Dopamine Revolution A Parkinson’s Brainstem Dopamine responses • Burst to unexpected reward • Response transfers to reward predictors • Pause at time of omitted reward Schultz et al. 1997 The Standard Model Reward Prediction Error Q(t+1) = Q(t) + α[r(t+1) - Q(t)] Q(t) = Estimate of EU at t r = Reward on last trial 26 Bush and Mosteller New Old Association = Association + Strength Strength 27 Correction Bush and Mosteller New Value Estimate Correction 28 = Old Value Estimate = Old Value Estimate + Correction - Obtained Reward Association Strength Bush and Mosteller 1 2 3 4 5 6 7 Trial Number 29 8 9 10 More dopamine responses reward following 0% predictive cue reward following 50% predictive cue reward following 100% predictive cue (Fiorillo et al 2003) no reward following 100% predictive cue First trial Conditioned stimulus Reward Last trial 0.5s Bayer and Glimcher, 2005, 2007 32 33 34 Neuronal Population N=44 RPE in Humans: Specific model RPE = outcome ($) – lottery expected value ($) n = 12 subjects, 3003 trials random effects Basal ganglia • “Loop” organization • Input (from cortex): striatum • Output (back to cortex, via thalamus): globus pallidus (internal) Direct and indirect pathways • Parallel paths through BG • Opposite effects on thalamus, motor ctx – direct pathway has 2x inhibition: net facilitation, “go” – indirect pathway has 3x inhibition: net inhibition, “no-go” • Recordings: – Striatum: excitation & inhibition related to movement execution – GPi: inhibition related to movement execution • Why have two pathways? Alexander & Crutcher 1990 Striatal PANs 41 Post-Saccadic Neurons: •Class 1: Movement Just Completed •Class 2: Reward Just Received 42 •Qi(t) Coded Before Movement •Qchosen(t) Coded After Movement 43 Lau and Glimcher, 2009 Dopamine and plasticity • If dopamine carries a prediction error, where does learning happen? • Potentially, the cortico-striatal synapse DA and corticostriatal plasticity Wickens et al. 1996 Three-factor learning rule? (pre/post/dopamine) wi,t+1 = wi,t + edt Addiction If it is: The Standard RPE Model + Addiction (Redish) Q(t+1) = Q(t) + α[r(t+1) - Q(t)] +D D r 49 = Dopamine Activation = Reward on last trial Oculomotor matching task: Searching for Action Values Choice 0.10 0.20 Cues Fix Rewards arranged using independent reward probabilities Q(t+1) = Q(t) + α[r(t+1) - Q(t)] +D 51 Q(t+1) = Q(t) + α[r(t+1) - Q(t)] +D 52 Example 1 Example 2 Stim On Stim On End temporal-difference learning Rescorla-Wagner: Want Vn = rn units) (here n indexes trials, treated as Use prediction error dn = rn – Vn Temporal-difference learning (Sutton & Barto): Predict cumulative future reward: Want Vt = rt + rt+1 + rt+2 + rt+3 + … (here t indexes time within trial) = rt + Vt+1 (clever recursive trick) temporal difference learning Temporal-difference learning (Sutton & Barto): Want Vt = rt + rt+1 + rt+2 + rt+3 + … = rt + Vt+1 Use prediction error dt = [rt + Vt+1] – Vt • learn to predict cumulative future rewards rt + rt+1 +… • learn using what I predict at time t+1 (Vt+1) as stand in for all future rewards – • so I don’t have to wait forever to learn learn consistent predictions based on temporal difference Vt+1 – Vt – if Vt+1 = Vt, my predictions are consistent – if Vt+1 > Vt, things got unexpectedly better – if Vt+1 < Vt, things got unexpectedly worse and these act like reward to generate prediction error and learning More dopamine responses reward following 0% predictive cue Prediction error: Vt+1 = 0 dt = rt – Vt reward following 50% predictive cue reward following 100% predictive cue (Fiorillo et al 2003) no reward following 100% predictive cue More dopamine responses reward following 0% predictive cue Same story here Vt = 0; rt = 0 dt = Vt+1 reward following 50% predictive cue reward following 100% predictive cue (Fiorillo et al 2003) no reward following 100% predictive cue Dopamine responses interpreted r(t) V(t) V(t+1) – V(t) d(t) = r(t) + V(t+1) – V(t) r(t) V(t) V(t+1) – V(t) d(t) = r(t) + V(t+1) – V(t) (Schultz et al. 1997) How should this one look? Law of Effect “Of several responses made to the same situation, those which are accompanied or closely followed by satisfaction to the animal will, other things being equal, be more firmly connected with the situation, so that, when it recurs, they will be more likely to recur.” Thorndike (1911) policy p