Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Holonomic brain theory wikipedia , lookup
Response priming wikipedia , lookup
Eyeblink conditioning wikipedia , lookup
Neurocomputational speech processing wikipedia , lookup
Types of artificial neural networks wikipedia , lookup
Feature detection (nervous system) wikipedia , lookup
Synaptic gating wikipedia , lookup
Perceptual control theory wikipedia , lookup
Metastability in the brain wikipedia , lookup
Biological neuron model wikipedia , lookup
Central pattern generator wikipedia , lookup
Mathematical model wikipedia , lookup
Muscle memory wikipedia , lookup
Nervous system network models wikipedia , lookup
Embodied language processing wikipedia , lookup
Premovement neuronal activity wikipedia , lookup
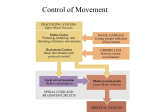
Brain Regions Involved in USCBP Reaching Models A High Level Overview Brain Regions • Cheol’s Models – – – – Motor cortex (M1) Spinal cord Basal Ganglia (BG) Dorsal Premotor (PMd, providing input) • Jimmy’s Models – – – – Parieto-occipital area (V6a) Lateral intraparietal area (LIP) BG PMd (specifically F2) Issues In Model Integration • • • • Unified View of M1 Interactions between PMd and M1 Role of the BG Involvement of the Cerebellum M1 Modeling • Cheol – Top-down model – directional tuning with supervised and unsupervised learning – Bottom-up model – input and output maps with controlling muscle synergies • Jimmy – Robotic control model – trajectory generator, inverse kinematics, PD controllers (probably not all in M1) Cheol’s Top-Down M1 Model • Directional tuning of M1 neurons tuned using supervised learning and unsupervised learning • Arm choice learned with reinforcement learning – Jimmy: Equivalent to noisy WTA based on executability – Cheol: connecting to unified view of motor learning Possible motor procedures in the motor cortex • Inverse dynamics and muscle models learned using temporal difference learning in an actorcritic architecture • The actor may correspond to the motor cortex. Trajectory Generator Joint static Level Planning ACTOR Inverse Dynamics Joint “force” Level Planning Inverse Muscle Model Muscle Level Planning Motoneurons (spinal cord) Arm CRITIC Evaluator Of Mvmt TD error Cheol’s Bottom-up M1 model (based on feedback signal) Target location (premotor) IDM: mapping the error direction to muscle synergy (directly related to directional tuning) ISM Motor Cortex Model (map) + Feedback signal (premotor) + (with optimal feedback controller) - Muscle Synergy Forward model Pesaran et al. (2006) indicated that PMd neurons encoded both target location and feedback signal. ILGA Motor Controller • Input - reach target in wrist-centered coordinates • Dynamic Motor Primitives – generate reach trajectory • Inverse Kinematics – pseudo-inverse of Jacobian matrix • PD controllers – one for each DOF Interactions Between PMd and M1 • Our views of the role of PMd are very similar • Jimmy – PMd (F2) provides M1 with target location in wrist-centered coordinates • Cheol – Supra-motor-cortex coding in PMd may be feedback error (target location in handcentered reference frame) and/or target location in the fixation point coordinates. ILGA: F2 Integrates Bottom-Up and Top-Down Reach Target Signals Tanne et al (1995) • Rostral F2 performs target selection based on parietal and prefrontal input • Caudal F2 encodes selected target and initiates reach – F6 detects go signal and disinhibits via BG Reconciliation with FARS view of PMd • FARS implicated F2 in conditional action selection and F4 in reach target selection • However many studies show F2 to contain directionally tuned neurons that discharge prior to reaching • F4 contains bimodal (visual / somatosensory) neurons that respond when objects approach their somatosensory receptive field on the arm or hand F2 vs. F4: Experimental Data • Neurons in F2 are broadly tuned to multidimensional direction in a reaching task (Caminiti, 1991; Fu et al., 1993) • Pesaran, Nelson & Andersen (2006) – PMd neurons encode relative positions of eye, hand, and target – PMd contains combined signals. – MIP contains more (target-eye) coding – fixation point coordinate • F4 bimodal visual-tactile neurons have very large visual and somatosensory receptive fields and visual field is anchored to somatosensory field – But most don’t fire for stimuli farther than 25cm away (Graziano et al., 1997) - Not suitable for encoding reach target! – May be involved in feedback control of reach-grasp coordination – tactile RFs may contribute to transition from visual- to haptic-based control Role of the BG • Cheol – Adaptive critic in actor-critic architecture • Jimmy – Adaptive critic gated by internal state – Action disinhibition • Role in previous USCBP models – – – – DA / DAJ – action disinhibition ILGM – reward signal Extended TD – adaptive critic Bischoff BG model – next-state prediction BG Disinhibition of Action • ILGA’s use of the basal ganglia to disinhibit actions is largely consistent with its role in the Dominey-Arbib and Dominey-ArbibJoseph Models • The cortical target of context-dependent biases are different BG as an Adaptive Critic • The basal ganglia’s role as an adaptive critic is not very controversial • However, each of our models uses it to learn different parameters – – – – Cheol’s top-down model – to modify arm selection Cheol’s bottom-up model – to learn inverse models ILGA – kinematic parameters and contextual bias ACQ – executability and internal state-dependent desirability • Does this imply several actor/critic combinations (1:1, N:1, 1:N, N:N)? – – – – Cheol’s top-down model – actor / critic Cheol’s bottom-up model – actor / critic ILGA – actor / critic ACQ – actor / multiple critics M1 & BG roles in Cheol’s unified view The reinforcement learning framework will replace “optimization of a taskrelated cost function” with “maximization of a task-related reward function” which also accounts for actuators’ limitation Visual signal (world representation) Action-oriented perception ? The critic encodes the current task-related reward function. The reward or an action value is defined only when we have an “objective”. So, the critic will try to encode which action might be the best action in terms of reward (action value) to achieve a certain objective. It will monitor that the current movement’s performance. If the performance is changed, Critic the X critic will give the information of the next best action. And it will facilitate changing the actor accordingly. Target related signal (vision-task-related) If there are multiple tasks, there should be multiple critics. Send limitation of isthe This arrow actuators the viaactor. TD error representation of the actuator What is now the critic’s role? It will encode the objective function and provide the “teaching” signal to the actor through TD error: if TD error is zero, we don’t need to change the actor, and so on. TD error. Critic (motor-task-related) It represent the current maximum capability of the motor actuators. Send limitation of the actuators via unsupervised Any motorlearning actuators So, if the motor actuators are based on muscles, it will be the muscle synergies and the limitation of muscle-based actuator. If there is a stroke on it, the maximum capability is changed and the limitation of the world increases. If there is a rehabilitation, the maximum capability is changed again and the limitation decreases. M1 & BG roles in Cheol’s unified view PLoS model Jool’s variability data Reaching module Coordination manager Critic Critic actor Representation of the actuators Because of the stroke on a motor cortex, we have a change in limitation (performance change) of the corresponding actuator. The action choice module will encode which arm is better in a certain direction. So when the performance of the affected arm decreased, it will say that the best action is using the unaffected arm. (i.e. behavioral compensation). Can we connect these ideas with the words executability and desirability? In general, the objective function contains both concepts I think. Hierarchical Optimal Feedback Controller Todorov et al (2005) found a similar idea on hierarchical optimization of the plants. But the reinforcement learning framework will provide the more general framework of the motor system learning and may be more applicable Grasping module Maybe separated obtaining of those two modules (early learning) In this coordination problem, we may have an objective of the coordination. As an example, we can weigh more on faster movement, or on the accurate movement, or accurate grasping. So based on the different objective, we may have variability in coordination. However, this coordination is not free from the actuators. First, if there is a signal dependent noise, we cannot have too fast movement. (This limitation is already in the Hoff-Arbib model). Second, too large initial aperture can assure the more accurate grasping but will give a limitation of the reaching module (slower reaching). Motor cortex model Kambara et al. (2008) showed the possibility and I also would implement it with map reorganization! Involvement of the Cerebellum • Schweighofer’s Modeling – corrects for nonlinearities in arm control • Cheol – what about learning projections from cerebellum to M1? References • • • • • • • • Caminiti, R., Johnson, P.B., Galli, C., Ferraina, S., Burnod, Y. (1991) Making Arm Movements within Different Parts of Space: The Premotor and Motor Cortical Representation of a Coordinate System for Reaching to Visual Targets. The Journal of Neuroscience, 11(5): 1182-1197. Fu, Q.G, Suarez, J.I., Ebner, T.J. (1993) Neuronal Specification of Direction and Distance During Reaching Movements in the Superior Precentral Premotor Area and Primary Motor Cortex of Monkeys. Journal of Neurophysiology, 70(5): 2097-2116. Graziano, M.S.A., Hu, X.T., Gross, C.G. (1997) Visuospatial Properties of Ventral Premotor Cortex. Journal of Neurophysiology, 77: 2268-2292. Tanne, J., Boussaoud, D., Boyer-Zeller, N., Roiuller, E.M. (1995) Direct visual pathways for reaching movements in the macaque monkey. NeuroReport, 7: 267-272. Pesaran, B., Nelson, MJ., Andersen, RA. (2006) Dorsal premotor neurons encode the relative position of the hand, eye, and goal during reach planning. Neuron 51, 125134 Buneo, CA., Jarvis, MR., Batista, AP., Andersen RA, (2002) Direct visuo-motor transformation for reaching, Nature 416, 632-636. Todorov, E., Li, W., Pan X., (2005) From task parameters to motor synergies: A hierarchical framework for approximately optimal control of redundant manipulator, J Robot Syst. 22(11), 691-710. Kambara, H., Kim, K., Shin, D., Sato, M., Koike, Y., (2006) Motor control-learning model for reaching movements, IJCNN2006