Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Polyadenylation wikipedia , lookup
Genetic code wikipedia , lookup
RNA interference wikipedia , lookup
Secreted frizzled-related protein 1 wikipedia , lookup
RNA silencing wikipedia , lookup
Gene desert wikipedia , lookup
Ridge (biology) wikipedia , lookup
Genomic imprinting wikipedia , lookup
List of types of proteins wikipedia , lookup
Community fingerprinting wikipedia , lookup
Epitranscriptome wikipedia , lookup
Non-coding DNA wikipedia , lookup
Non-coding RNA wikipedia , lookup
RNA polymerase II holoenzyme wikipedia , lookup
Eukaryotic transcription wikipedia , lookup
Molecular evolution wikipedia , lookup
Gene expression profiling wikipedia , lookup
Genome evolution wikipedia , lookup
Gene regulatory network wikipedia , lookup
Gene expression wikipedia , lookup
Artificial gene synthesis wikipedia , lookup
Promoter (genetics) wikipedia , lookup
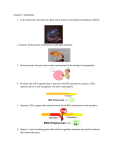
Genomics and Gene Recognition CIS 667 April 27, 2004 Genomics and Gene Recognition • How do we recognize the genes given the raw sequence data? • Two different cases: Prokaryotes: relatively easy Eukaryotes: relatively difficult Much “junk DNA” to search through • Signals determine the beginnings and ends of genes Need to find the signals Prokaryotic Genomes • Genomic information of prokaryotes dedicated mainly to basic tasks Make and replicate DNA Make new proteins Obtain and store energy • Over 60 prokaryotic genomes have been completely sequenced since mid-1990s Prokaryotic Genomes • Recall - prokaryotes have a single circular chromosome • Also - no cell nucleus, therefore no splicing out of introns • Therefore, prokaryotic gene structure is quite simple Translational Translational Promoter region start site (AUG) stop site Open Reading Frame Transcriptional start site Operator sequence Transcriptional stop site Promoter Elements • Gene expression begins with transcription RNA copy of a gene made by an RNA polymerase Prokaryotic RNA polymerases are assemblies of several different proteins b’ protein binds to DNA template b protein links nucleotides a protein holds subunits together s protein recognizes specific nucleotide sequences of promoters Promoter Elements • b’, b and a often very similar from one bacterial species to another • s can vary (less well conserved) Several variants often found in a cell The ability to use several different s factors allows a cell to turn on or off expression of whole sets of genes For example, s32 turns on gene expressions for genes associated with heat shock while s54 does the same for nitrogen stress and genes that always need to be expressed are transcribed by polymerases with s70 Promoter Elements • Each s factor recognizes a particular sequence of nucleotides upstream from the gene s70 looks for -35 sequence TTGACA and -10 sequence TATAAT Other s factors look for other -35 and -10 sequences The match need not always be exact The better the match, the more likely transcription will be initiated Promoter Elements • Protein products from some genes are always used in tandem with those from some other genes These related genes may share a single promoter in prokaryotic genomes and be arranged in an operon When one gene is transcribed, so are all of the others - one polycistronic RNA molecule is produced The lactose operon contains three genes involved in metabolism of the sugar lactose in bacterial cells Operon QuickTime™ and a TIFF (Uncompressed) decompressor are needed to see this picture. Operon • The protein encoded by the regulatory gene (pLacI) can bind to lactose or to the operator sequence of the operon So when lactose is abundant, less likely to bind to operator sequence When it does, it blocks transcription, thus acting as a negative regulator Even without negative regulation, we have low levels of operon expression due to poor match of consensus sequence for the s factor • A positive regulator (CRP) promotes expression Operon QuickTime™ and a Animation decompressor are needed to see this picture. Lac Operon QuickTime™ and a decompressor are needed to see this picture. Open Reading Frames • Recall - 3 of the 64 codons are stop codons (UAA, UAG, UGA) - they cause translation to stop • Most prokaryotic proteins are longer than 60 amino acids Since on average we expect to find a stop codon once in every 21 (3/64) codons, the presence of a run of 30 or more codons with no stop codons (an Open Reading Frame - ORF) is good evidence that we are looking at the coding sequence of a prokaryotic gene Open Reading Frames • AUG is a start codon Defines where translation begins If no likely promoter sequences are found upstream of a start codon at the start of an ORF before the end of the preceding ORF, assume the two genes are part of an operon whose promoter sequence is further upstream Termination Sequence • Most prokaryotic operons contain specific signals for the termination of transcription called intrinsic terminators Must have a sequence of nucleotides that includes an inverted repeat followed by A run of roughly six uracils The inverted repeat allows the RNA to form a loop structure that greatly slows down RNA synthesis Together with the chemical properties of uracil, this is enough to end transcription Termination Sequence QuickTime™ and a TIFF (Uncompressed) decompressor are needed to see this picture. GC Content in Prokaryotic Genomes • For every G within a double-stranded DNA genome there must be a C - likewise an A for every T Only constraint on fraction of nucleotides that are G/C as opposed to A/T is that the two must add to 100% Can use genomic GC content to identify bacterial species (ranges from 25% to 75%) Can also use GC content to identify genes that have been obtained from other bacteria by horizontal gene transfer Prokaryotic Gene Densities • Gene density within prokaryotic genomes is very high Between 85% and 88% of the nucleotides are typically associated with coding regions of genes Just as large portions of chromosomes can be acquired, they can also be deleted Portions left are those which code for essential genes Gene Recognition in Prokaryotes • Long ORFs (60 or more codons) • Matches to simple promoter sequences • Recognizable transcriptional termination signal (inverted repeats followed by run or uracils) • Comparison with nucleotide (or amino acid) sequences of known protein coding regions from other organisms Eukaryotic Genomes • Much more complex Internal membrane-bound compartments allows wide variety of chemical environments in each cell Multicellular organisms Each cell type has distinct gene expression Size of genome may be larger Allows for “junk DNA” • Gene expression more complex and flexible than in prokaryotes Eukaryotic Gene Structure Promoter Elements • Each different cell type requires different gene expression Therefore eukaryotes have elaborate mechanisms for starting transcription Prokaryotes have a single RNA polymerase eukaryotes have three RNA polymerase I - Ribosomal RNAs RNA polymerase II - Protein-coding genes RNA polymerase III - tRNAs, other small RNAs Promoter Elements • Most RNA polymerase II promoters contain a set of sequences known as a basal promoter where an initiation complex is assembled and transcription begins • Also have several upstream promoter elements (typically at least 5) to which other proteins bind Without the proteins binding upstream, initiation complex assembly is difficult QuickTime™ and a TIFF (Uncompressed) decompressor are needed to see this picture. Promoter Elements • RNA polymerase II does not directly recognize the basal sequences of promoters Basal transcription factors including a TATA-binding protein (TBP) and at least 12 TBP-associated factors bind to the promoter in a specific order, facilitating binding of RNA polymerase TATA-box 5’-TATAWAW-3’ (W is A or T) at -25 relative to transcriptional start site Initiator sequence 5’-YYCARR-3’ (Y is C or T and R is G or A) at transcriptional start site QuickTime™ and a TIFF (Uncompressed) decompressor are needed to see this picture. QuickTime™ and a decompressor are needed to see this picture. Transcription Regulatory Protein Binding Sites • Transcription initiation in eukaryotes relies heavily on positive regulation Constitutive factors work on many genes and don’t respond to external signals Regulatory factors have limited number of genes and respond to external signals Response factors (e.g. heat shock) Cell-specific factors (e.g. pituitary cells only) Developmental factors (e.g. early embryo organization) Open Reading Frames • Before translation, a heterogeneous RNA (hnRNA) is transformed into mRNA by being Capped 5’ end chemically altered Spliced Various splicings can occur Polyadenylated Long stretch of A’s added at 3’ end Introns and Exons • The introns are spliced out of the hnRNA Protein-coding genes conform to the GU-AG rule These are the nucleotides at the 5’ and 3’ end of the intron Other nucleotides are examined as well • Most of these are inside the intron • These signals constrain introns to be at least 60 bp long but there is no upper limit Alternative Splicing • About 20% of human genes give rise to more than one type of mRNA sequence due to alternative splicing • Splice junctions can be masked, causing an exon to be spliced out • The following slide shows how alternative splicing based on different splicing factors (proteins) can stop a useful protein from being produced Alternative Splicing GC Content • Overall GC content between different genomes does not vary as much in eukaryotes as in prokaryotes However variations in GC content within a genome can help us to recognize genes Of all of the pairs of nucleotides, statistically, CG is found only at 20% of its expected value No other pair is under or over represented GC Content • The expected levels of are found, however, in stretches of 1 -2 kbp at the end of the 5’ ends of many human genes These are called CpG islands and are associated with methylation Can cause make it easy for CG to mutate to TG or CA High levels of methylation imply low levels of acetylation of histones (a protein which, when acetylated makes transcription of DNA possible) Isochores • Vertebrates and plants display a level of organization called isochores that is intermediate between that of genes and chromosomes The GC content of an isochore is relatively uniform throughout There are five classes of isochores depending on the level of GC content Those with high GC content also have high gene density The types of genes found in different classes differs as well Codon Usage Bias • Another hint for gene hunting can be derived from the fact that every organism prefers some equivalent triplet codon to code for proteins • Real exons generally reflect the bias while randomly chosen strings of triplets do not Gene Recognition • In summary, useful DNA sequence features for gene hunting include Known promoter elements (I.e. TATA boxes) CpG islands Splicing signals associated with introns ORFs with characteristic codon utilization Similarity to the sequences of ESTs or genes from other organisms. Gene Expression • Expression varies greatly however • Tools for determining gene expression levels include cDNAs and ESTs Complementary DNAs are synthesized from mRNAs and can be used to provide expressed sequence tags useful for contig assembly or gene recognition cDNA Microarrays • Gene expression patterns can be studied using microarrays Small silica (glass) chips covered with thousands of short sequences of nucleotides of known sequence The microarray can then be used to compare the expression of all of the genes in the genome simultaneously A gene is represented by a set of 16 probes Microarrays • The probes representing genes are arranged in a grid on the chip • Fluorescently labeled cDNA from the tissue/organism we want to test is washed over the chip from the tissue/organism we want to test • If a gene is expressed, it will bind to the genes tags • We can detect this through pattern recognition Microarrays Make cDNA from cells before treatment with a drug Make cDNA from cells after treatment with a drug Microarrays Transposition • Transposons result from insertion of duplicate sequence from another part of the genome aided by a transposase enzyme If inserted in “junk DNA”, not harmful More common are retrotransposons which are by retroviruses (encapsulated RNA and reverse transcriptase which use a host to duplicate) like HIV Retrovirus Replication QuickTime™ and a TIFF (Uncompressed) decompressor are needed to see this picture. Virus Replication QuickTime™ and a TIFF (Uncompressed) decompressor are needed to see this picture.