Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Gene regulatory network wikipedia , lookup
Cell-penetrating peptide wikipedia , lookup
Expanded genetic code wikipedia , lookup
Molecular evolution wikipedia , lookup
G protein–coupled receptor wikipedia , lookup
Genetic code wikipedia , lookup
Silencer (genetics) wikipedia , lookup
Bottromycin wikipedia , lookup
Magnesium transporter wikipedia , lookup
Artificial gene synthesis wikipedia , lookup
Gene expression wikipedia , lookup
Ancestral sequence reconstruction wikipedia , lookup
Rosetta@home wikipedia , lookup
Protein design wikipedia , lookup
List of types of proteins wikipedia , lookup
Biochemistry wikipedia , lookup
Intrinsically disordered proteins wikipedia , lookup
Protein domain wikipedia , lookup
Circular dichroism wikipedia , lookup
Protein moonlighting wikipedia , lookup
Protein folding wikipedia , lookup
Protein (nutrient) wikipedia , lookup
Metalloprotein wikipedia , lookup
Western blot wikipedia , lookup
Protein–protein interaction wikipedia , lookup
Protein adsorption wikipedia , lookup
Homology modeling wikipedia , lookup
Nuclear magnetic resonance spectroscopy of proteins wikipedia , lookup
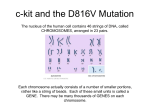
Bioinformatics and Protein Structure – Questions Step 1. Getting sequences and learning about your protein Gene database at NCBI 1. Is this a primary or a secondary database? Explain your answer. 2. What type of information may be available for a gene in this database? 3. What subset of sequences is included in this database? 4. What is a refseq? (You will have to search the NCBI Web Site to find this – go back to the home page and select NCBI Web Site from the drop down list). PTGS entry 5. What is the official Gene symbol? 6. What is Gene name? 7. What is the GeneID number? 8. Where in the human genome is this gene located? 9. What is the function of this protein? 10. What specific role does it play in the cell? 11. What is the RefSeq accession number for the mRNA of this gene? 12. What is the RefSeq accession number for the protein sequence (it is the product of the gene)? Swiss-Prot 13. Is this a primary or secondary database? Why? 14. Would you expect to see the same protein sequence represented more than once? Why or why not? 15. What is the SwissProt accession number? (Hint: for proteins it always starts with a P), 1 Bioinformatics and Protein Structure – Questions 16. What are the alternate names for this protein? 17. Where in the cell is this protein located? (If it is known it will be in the comments – if it is not listed your answer is “unknown”.) 18. Does this protein exist as a monomer, dimmer (homo or hetero) etc.? OMIM 19. What information is available at this site? 20. Is this a primary or a secondary database? Why? again it is annotated so a 2ndary database 21. What book is the information in OMIM base on? 22. Would you expect to find information on an infectious disease such as Herpes in this database? Why or why not? 23. What disease is associated with the protein you are studying? Project specific questions 24. In addition to the general questions, answer the following PAH specific questions (use information from these databases or the Berg reading material, note that you may need to clink on links). Please indicate which source each answer comes from. a. What metabolic pathway does this protein belong to? b. Which three amino acid residue numbers bind the iron atom and how was this determined? c. Which residue is modified by phosphorylation? d. Diagram the reaction catalyzed by this enzyme (include structures). e. What is the difference between PKU and the related disease hyperphenyalanine? f. Suggest an explanation for why there is a range of symptoms among different hyperphenylalaninemia individuals (I’m looking for your own ideas here)? g. Normally, what fraction of phenylalanine is converted to tyrosine? 2 Bioinformatics and Protein Structure – Questions Step 2. Finding related sequences and setting up a multi-sequence FASTA file BLAST (at NCBI) 25. What does this acronym stand for and what is it used for? 26. In your own words, describe what FASTA format is. Step 3. Creating the MSA using ClustalW 27. What information can be obtained from a multiple sequence alignment of related proteins? 28. What are three ways this information can be used? 29. What types of sequences can be aligned by ClustalW? 30. Print the output to hand one in at the end of today’s lab. Also answer the following questions. 31. What is the mutation? Write it in the following format "Res123Res" where Res is the threeletter code for the amino acid in the un-mutated (wild type) protein and the second Res is the amino acid in the mutated protein. In place of "123" put the amino acid residue number of the mutation. 32. Is the mutation in a region of conservation – how do you know? 33. What properties differ between the mutant and normal protein (see Betts and Russel, 2003)? Step 4. Secondary structure prediction 34. What is the secondary structure predicted for the region containing the mutation? 35. What type of secondary structure(s) is the most common in the alignment? If it seems an even mix between -helixes and -sheets, state that. 36. Do you think that the mutation in your protein may alter the secondary structure, why or why not? 37. How could you test your prediction? 3 Bioinformatics and Protein Structure – Questions Step 5. Analysis of the 3D structure 38. Experimental method used to obtain the data: 39. Resolution of the structure 40. Species the protein was obtained from 41. List any ligands, cofactors or metal ions included in the structure (particularly important for enzymes): Project specific questions. These can be answered using the PDB specific information available at RCSB, or by going to the journal article on which this structure is based (direct link to the abstract at RCSB). a. What is the first author and journal name for the primary citation for this crystal structure? b. Was the entire PAH protein used to obtain the crystal structure (if not what portion was included)? c. What molecules were bound to the protein and what ‘real’ molecules do they represent? d. Compare and contrast the structure of the substrate analog with phenylalanine. 42. The actual secondary structure of your protein is shown in Control Panel. Using the same symbols as for the predicted structure, but a different colour pen, write the actual secondary structure above the predicted secondary structure on your MSA. What major differences, if any, do you see? 43. PSIPRED states its predictions are ~80% correct. Do you agree this is a good estimate of the accuracy? 44. What groups, and what exact atom of each group is involved in the H-bond (for example backbone O of Glu14)? 45. What type of secondary structure are these groups involved in? 46. List any changed, lost, or new H-bonds between the mutated amino acid and other groups. 47. If a new group(s) has been associated with the mutant amino acid (ct the normal amino acid), what types of structure(s) is this group(s) involved in? 4 Bioinformatics and Protein Structure – Questions 5