Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
No-SCAR (Scarless Cas9 Assisted Recombineering) Genome Editing wikipedia , lookup
United Kingdom National DNA Database wikipedia , lookup
Whole genome sequencing wikipedia , lookup
Non-coding DNA wikipedia , lookup
Genomic library wikipedia , lookup
Point mutation wikipedia , lookup
Microevolution wikipedia , lookup
Pathogenomics wikipedia , lookup
Genealogical DNA test wikipedia , lookup
Human genome wikipedia , lookup
Artificial gene synthesis wikipedia , lookup
Helitron (biology) wikipedia , lookup
Smith–Waterman algorithm wikipedia , lookup
Computational phylogenetics wikipedia , lookup
Public health genomics wikipedia , lookup
Human genetic variation wikipedia , lookup
Genome editing wikipedia , lookup
Molecular Inversion Probe wikipedia , lookup
Multiple sequence alignment wikipedia , lookup
Metagenomics wikipedia , lookup
Haplogroup G-M201 wikipedia , lookup
Sequence alignment wikipedia , lookup
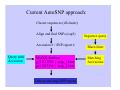
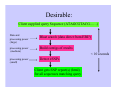
Mining Single Nucleotide Polymorphisms from public sequence databases. Gary Barker IACR Long Ashton What are Single Nucleotide Polymorphisms (SNPs)? ATGGTAAGCCTGAGCTGACTTAGCGT-AT ATGGTAAACCTGAGTTGACTTAGCGTCAT ↑ ↑ ↑ snp snp indel SNPs result from replication errors and DNA damage Why are these polymorphisms useful? It’s sometimes possible to correlate a SNP with a particular trait. This is known as association genetics. Disease resistant population Disease susceptible population Genotype all individuals for thousands of SNPs ATGATTATAG geneX ATGTTTATAG Resistant people all have an ‘A’ at position 4 in geneX, while susceptible people have a ‘T’ To use SNPs, you first have to find them. Poorly studied organisms: Sequence many ‘loci’ (different places in the genome) for many individuals. Many well studied organisms: Required data is already present in public sequence databases, it just needs to be processed. Number of ESTs* in EMBL database Search string (common) Homo sapiens Hordeum vulgare Triticum aestivum Zea mays Oryza sativa (man) (barley) (wheat) (maize) (rice) ESTs in EMBL (07-11-02) 4,798,137 308,301 264,910 181,164 112,240 *ESTs are single pass (often partial) gene sequences Mining SNPs from EST sequences in the database AutoSNP (PERL script) can find likely SNPs in data sets downloaded from public databases. 1) Marks up only those polymorphisms where each allele is supported by at least two independent sequences. This filters out most sequencing errors. 2) Adds further confidence scores based on co-segregation 3) Results written to HTML reports. Accessing AutoSNP results 1) Search by accession number: Accessing AutoSNP results 2) Search with a query sequence Current AutoSNP approach: Cluster sequences (d2cluster) Query with Accession Align and find SNPs (cap3) Sequence query Accession # / SNP report # Blast client MySQL database gi|11117503 | snip_1.htm gi|12217138 | snip_2.htm Matching Accessions Links to existing SNP reports Desirable: Client supplied query Sequence (ATAGCGTACG……) Data and processing power (large) Blast search (data direct from EBI?) processing power (medium) Build contigs of results processing power (small) Detect eSNPs < 10 seconds Client gets SNP report(s) (html) for all sequences matching query Conclusions SNPs (single nucleotide polymorphisms) are abundant and useful genetic markers. Software exists to mine them from public data sets, but this doesn’t work in real time. GRID technology could help to deliver up-to-date alignments to users for any query sequence with putative SNPs marked up. Related useful features would include bootstrapped trees for each alignment, generated on the fly.













![[edit] Use and importance of SNPs](http://s1.studyres.com/store/data/004266468_1-7f13e1f299772c229e6da154ec2770fe-150x150.png)







