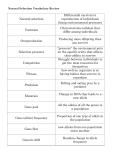
Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Viral phylodynamics wikipedia , lookup
Neuronal ceroid lipofuscinosis wikipedia , lookup
Frameshift mutation wikipedia , lookup
Gene therapy wikipedia , lookup
Saethre–Chotzen syndrome wikipedia , lookup
Genome (book) wikipedia , lookup
Gene expression profiling wikipedia , lookup
Genome evolution wikipedia , lookup
Vectors in gene therapy wikipedia , lookup
Gene nomenclature wikipedia , lookup
History of genetic engineering wikipedia , lookup
Gene desert wikipedia , lookup
Nutriepigenomics wikipedia , lookup
Gene expression programming wikipedia , lookup
Human genetic variation wikipedia , lookup
Therapeutic gene modulation wikipedia , lookup
Group selection wikipedia , lookup
Hardy–Weinberg principle wikipedia , lookup
Helitron (biology) wikipedia , lookup
Dominance (genetics) wikipedia , lookup
The Selfish Gene wikipedia , lookup
Point mutation wikipedia , lookup
Designer baby wikipedia , lookup
Artificial gene synthesis wikipedia , lookup
Polymorphism (biology) wikipedia , lookup
Site-specific recombinase technology wikipedia , lookup
Genetic drift wikipedia , lookup
Coalescent Theory •Considers the genealogical history of genes in populations •Uses DNA sequence data to make inferences about population size, genetic structure, and evolutionary processes. Coalescent Process t2 tm is time for coalescence from m to m-1 sequences t3 t4 t5 Gene Tree How long will the coalescence process take? Simplest case: If pick two random gene copies, probability that the second is the same as the first is 1 / (2Ne). This is the probability that two alleles coalesce in previous generation. It follows that 1 - 1 / (2Ne) is the probability that two sequences were derived from different sequences in the preceding generation. Therefore, the probability that 2 sequences derived from the same ancestor 2 generations ago (grandparent) is 1 - 1 / (2Ne) x 1 / (2Ne). It can be shown that the probability that two sequences were derived from the same ancestor t generations ago is: [1 - 1 / (2Ne)t x (1 / (2Ne)] ~ (1 / (2Ne(-t/2Ne)) [1 - 1 / (2Ne)g-1 x (1 / (2Ne)] Because N is in denominator, the probability will depend on sample size Consider probability of common ancestry for: Generations ago 1 Prob(N=5) 0.400 Prob(N=10) 0.200 2 0.320 0.182 3 0.256 0.162 It can be shown that the average time back to common ancestry of a pair of genes in a diploid population is 2Ne, and the average time back to common ancestry of all gene copies is 4Ne generations. Large pop Small pop Coalescence with no mutation The average degree of relatedness increases with time. All of the gene copies in a population can be traced back to a single ancestral gene. A population will eventually become monomorphic for one allele or another, with this probability determined by initial allele frequencies. Coalescence with mutation If each lineage experiences m mutations per generation, then the number of base pair differences between them will be #dif = 2mtca. If the average time to coalescence is 2Ne for two randomly chosen gene copies, then #dif = 2 m (2Ne). Therefore, expect the average number of base pair differences between gene copies to be greater in a larger population. Polymorphism Polymorphism: when two or more alleles at a locus exist in a population at the same time. Nucleotide diversity: P = ij xixjpij Freq (x) Seq 1 G A G G T G C A A C Seq 2 G A G G A C C A A C Seq 3 G A G C T G G A A G 0.4 0.5 0.1 considers # differences and allele frequency 1 2 3 1 p12 p13 2 0.2 p23 3 0.3 0.5 P = (0.4)(0.5)(0.2) + (0.4)(0.1)(0.3) + (0.5)(0.1)(0.5) = 0.077 p12 p13 p23 Polymorphism is also estimated by: K= Number of segregating (variable) sites in a sample of alleles. ATCCGGCTTTCGA K = 3 for-->ATCCGAATTTCGA ATTCGCCTTTCGA In Theory: K/a = P Coefficient that considers number of sequences examined Testing DNA Sequences for Neutrality Tajima’ s Test (1989): D= Rationale: P-K/a V(P - K/a) Using the difference in estimates of polymorphism to detect deviation from neutrality. Normalizing factor P and K are differentially influenced by the frequency of alleles. P K/a Few alleles at intermediate frequency > Many low frequency, variable alleles < D = 0 neutral prediction D > 0 balancing selection D < 0 directional selection Gene genealogies under no selection (positive, balancing, or background selection). No Selection : 7 neutral mutations accumulate since the time of the last common ancestor. D=0 Consider the Effects of Selection on Neutral Sites Linked to a Selected Site Positive Selection : neutral variation at linked sites will be eliminated (swept away) as the advantageous allele quickly is fixed in the population. This process is also called hitch-hiking. D<0 Consider the Effects of Selection on Neutral Sites Linked to a Selected Site Balancing Selection : neutral variation at linked sites accumulates during the long period of time that both allele lineages are maintained. D>0 Consider the Effects of Selection on Neutral Sites Linked to a Selected Site Background Selection : gene lineages become extinct not only by chance, but because of deleterious mutations to which they are linked, which eliminates some gene copies. D<0