Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Silencer (genetics) wikipedia , lookup
Transcriptional regulation wikipedia , lookup
Non-coding DNA wikipedia , lookup
Molecular evolution wikipedia , lookup
Peptide synthesis wikipedia , lookup
Protein moonlighting wikipedia , lookup
List of types of proteins wikipedia , lookup
Ligand binding assay wikipedia , lookup
Endogenous retrovirus wikipedia , lookup
Homology modeling wikipedia , lookup
Protein–protein interaction wikipedia , lookup
Western blot wikipedia , lookup
Bottromycin wikipedia , lookup
Cooperative binding wikipedia , lookup
Protein adsorption wikipedia , lookup
Protein structure prediction wikipedia , lookup
Drug design wikipedia , lookup
Cell-penetrating peptide wikipedia , lookup
Ancestral sequence reconstruction wikipedia , lookup
Ribosomally synthesized and post-translationally modified peptides wikipedia , lookup
Self-assembling peptide wikipedia , lookup
Protein mass spectrometry wikipedia , lookup
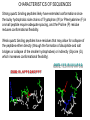
DESIGN OF INORGANIC BINDING PROTEINS RAM SAMUDRALA ASSOCIATE PROFESSOR UNIVERSITY OF WASHINGTON How can we design peptides and proteins capable of binding to inorganic substrates with specific selectivity and affinity? MOTIVATION The functions necessary for life are undertaken by proteins. Protein function is mediated by protein three-dimensional structure. A vast number of computational methodologies have been developed for the analysis and modelling of the sequences and structures of naturally occurring proteins. We can harness these knowledge- and biophysics-based computational methodologies to design peptides and proteins capable of binding to inorganic substrates with specific affinity and selectivity. Goal is to develop generalised computational techniques to construct molecular building blocks based on peptides and proteins that can be easily assembled to design higher order structures. Applications in the area of medicine, nanotechnology, and biological computing. KNOWLEDGE-BASED DESIGN Proteins that are evolutionarily related generally have similar sequences, structures, and functions. We hypothesised that this applies to experimentally discovered peptides capable of binding to inorganic substrates. We then examined similarity of sequences between experimentally discovered peptides and random peptide sequences using standard sequence comparison tools. Random peptide sequences most similar to a particular group of experimentally discovered peptides were considered to possess the same functional property. Some examples of experimentally discovered peptides (from Mehmet Sarikaya): Platinum binders: Hydroxyapatite binders: Quartz binders: DRTSTWR RLNPPSQMDPPF MLPHHGA TSPGQKQ QTWPPPLWFSTS TTTPNRA IGSSLKP LTPHQTTMAHFL PVAMPHW SIMILARITY ANALYSIS The similarity of two protein or peptide sequences is determined by their optimal alignment score (PSS) according to a scoring matrix: QSVTSTK SVTQNKY QSVTSTK-SVTQNKY PSS=12 The scoring matrix determines the similarity of any two amino acids based on their evolutionary and biophysical preferences. BLOSUM and PAM are two popular scoring matrices derived from amino acid preferences observed in representative sets of proteins: Henikoff S, Henikoff JG. Proc. Natl. Acad. Sci. USA 89: 10915-10919, 1992. The optimal alignment and score is determined using dynamic programming. SIMILARITY ANALYSIS Our goal is to determine to the total similarity score (TSS) of one set of sequences (which may contain only one member) to another set of sequences. The total similarity score is effectively a normalised sum of pairwise similarity scores between sequences in the two sets: TSS A B Set A Set B TSTYKHS NTATKKV EASTRHG HSTDNKT SVTQNKY RATLNQQ . . . KNWHSLH LGPSGPK EPYNQNM AYPTQLD SEWLSAL RGLPAPT . . . Axa - Bxb ya yb xa , xb 1 PSSij 1 ij AB xa xb AB i 1, j 1 Initial studies were done by Ersin Emre Oren using the BLOSUM and PAM matrices on a set of 39 strong (10), moderate (14) and weak (15) quartz binding sequences provided by Mehmet Sarikaya. PRIMARY HYPOTHESIS VERIFICATION Strong Moderate Weak BACKTESTING PREDICTIVE POWER The total similarity score of each quartz binder to the set of strong quartz binders were calculated and used as an indicator of binding affinity. Quartz binders TSTYKHS NTATKKV EASTRHG HSTDNKT SVTQNKY RATLNQQ KNWHSLH LGPSGPK EPYNQNM AYPTQLD . . . Strong quartz binders KNWHSLH LGPSGPK EPYNQNM AYPTQLD SEWLSAL RGLPAPT OPTIMISATION OF SCORING MATRICES We perturbed the PAM 250 scoring matrix systematically to produce a higher strong-strong self-similarity and lower strong-weak cross-similarity score, and backtested the predictive power of the new QUARTZ I matrix. TSSs-s as high as possible TSSs-w as low as possible OPTIMISATION OF SCORING MATRICES We perturbed the PAM 250 scoring matrix systematically to produce a higher strong-strong self-similarity and lower strong-weak cross-similarity score, and backtested the predictive power of the new QUARTZ I matrix. KNOWLEDGE-BASED PEPTIDE DESIGN We hypothesised that random sequences similar to a set of sequences with a particular functional property must also possess that property. We calculated the TSS of 1,000,000 random sequences (12,000,000 aa) to the set of experimentally determined strong quartz binding sequences. EXPERIMENTAL VERIFICATION Three sets of experiments were performed by Mehmet Sarikaya’s group to validate the computationally designed sequences. DESIGN OF SECOND GENERATION MATRICES DESIGN OF CROSS-SPECIFIC BINDERS Quartz matrix scores Hydroxapatite matrix scores DESIGN OF CROSS-SPECIFIC BINDERS This procedure can be generalized to any number of inorganic substrates as long as there is enough initial data to calculate the TSS. CHARACTERISTICS OF SCORING MATRICES Quartz I – PAM 250 CS T PAGNDE QH R K M I L V F Y W C S T P A G N D E Q H R K M I L V F Y W CHARACTERISTICS OF SEQUENCES CHARACTERISTICS OF SEQUENCES Strong quartz binding peptides likely have extended conformations since the bulky hydrophobic side chains of Tryptophan (W) or Phenlyalanine (F) in a small peptide require adequate spacing, and the Proline (P) residue reduces conformational flexibility. Weak quartz binding peptides have residues that may allow for collapse of the peptides either directly (through the formation of disulphide and salt bridges or collapse of the smaller hydrophobes) or indirectly (Glycine (G), which increases conformational flexibility). DS072: Y E S I R I G V A P S Q DS202: R L N P P S Q M D P P F BIOPHYSICS-BASED DESIGN Characterise sequences and structures of naturally occurring proteins in terms of their total similarity scores using different scoring matrices. This will produce a database of sequences with predicted and known structures with specific selectivity and affinity to different inorganics. This database can be analysed for atom-atom preferences, torsion angle preferences, and other characteristics to define energy functions and move sets for performing protein structure simulations. We will combine this with our all-atom energy function capable of handling inorganics and our protein structure simulation software. Design higher order protein-like scaffolds with specific functionalities: Strong hydroxyapatite binding region Active site Strong quartz binding region ACKNOWLEDGEMENTS People: Ersin Emre Oren Mehmet Sarikaya and his group Candan Tamerler-Behar Samudrala group Primary support from: Defense University Research Initiative on NanoTechnology Genetically Engineered Materials Science and Engineering Center Other support from: National Institutes of Health National Science Foundation Kinship Foundation