Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Epigenetics of neurodegenerative diseases wikipedia , lookup
Pharmacogenomics wikipedia , lookup
Gene desert wikipedia , lookup
Polymorphism (biology) wikipedia , lookup
Human genome wikipedia , lookup
Nutriepigenomics wikipedia , lookup
Genetic testing wikipedia , lookup
Minimal genome wikipedia , lookup
Artificial gene synthesis wikipedia , lookup
Genomic imprinting wikipedia , lookup
Ridge (biology) wikipedia , lookup
Gene expression programming wikipedia , lookup
Epigenetics of human development wikipedia , lookup
Metagenomics wikipedia , lookup
Koinophilia wikipedia , lookup
Pathogenomics wikipedia , lookup
Behavioural genetics wikipedia , lookup
Site-specific recombinase technology wikipedia , lookup
Human–animal hybrid wikipedia , lookup
Biology and consumer behaviour wikipedia , lookup
Genome evolution wikipedia , lookup
Genetic engineering wikipedia , lookup
Population genetics wikipedia , lookup
Gene expression profiling wikipedia , lookup
Heritability of IQ wikipedia , lookup
Human genetic variation wikipedia , lookup
History of genetic engineering wikipedia , lookup
Designer baby wikipedia , lookup
Microevolution wikipedia , lookup
Genome (book) wikipedia , lookup
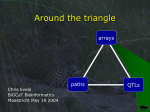
BIOINFORMATICS APPLICATIONS NOTE Vol. 21 no. 8 2005, pages 1737–1738 doi:10.1093/bioinformatics/bti209 Genetics and population analysis In silico fine-mapping: narrowing disease-associated loci by intergenomics Pablo Serrano-Fernández1,∗ , Saleh M. Ibrahim1 , Dirk Koczan1 , Uwe K. Zettl2 and Steffen Möller1 1 Institute of Immunology and 2 Institute of Neurology, University of Rostock, Schillingallee 70, D-18057 Rostock, Germany Received on September 17, 2004; revised on November 19, 2004; accepted on December 3, 2004 Advance Access publication December 10, 2004 ABSTRACT Summary: Genetic linkage and association studies define quantitative trait loci (QTLs) and susceptibility loci (SLs) that influence the phenotype of polygenic traits. A web-accessible application was created to identify intergenomic consensuses to fine map QTLs and SLs in silico and select particularly promising candidate genes for such traits. Furthermore, this approach offers an empirical evaluation of animal models for their applicability to the study of human traits. Availability: http://qtl.pzr.uni-rostock.de/qtlmix.php Contact: [email protected] MOTIVATION Genetic linkage analyses and association studies identify quantitative trait loci (QTLs) and susceptibility loci (SLs). QTLs are chromosomal regions containing genetic sequences that influence a continuously distributed phenotypic trait. SLs differ from QTLs in the kind of distribution of the trait, since it is a dichotomic one (development of the disease or not). QTLs and SLs have proven to help identify pathways involved in the pathogenesis of polygenic diseases (Doerge, 2002). Unfortunately, conventional approaches for fine-mapping such QTLs/SLs are time- and cost-intensive and experimentally complex (Rogner and Alvner, 2003; Lemon et al., 2003). Here, we present a bioinformatic tool to prioritize particular QTL/SL subregions for the wet-lab fine-mapping process and to preselect candidate genes jointly responsible for the trait. If animal models are driven by the same genetic mechanisms as those for human traits, we should expect to find conserved genetic sequences shared by QTLs of the animal models and susceptibility regions of the human trait. This principle has already been used to identify new SLs of certain human diseases, based on syntenic correspondence to QTLs of an animal model (Barton et al., 2001; Xu et al., 2001). Instead, we propose a user-guided multiple comparison of human traits and animal models of different species at a genome-wide scale to fine map known QTLs/SLs in silico. Furthermore, the approach provides an estimation of the validity of the selected animal models for a certain human trait or trait class. It has already been applied for the in silico fine-mapping of SLs of multiple sclerosis (MS) and its animal model, the experimental autoimmune encephalomyelitis (EAE) (Serrano-Fernández, 2004). ∗ To whom correspondence should be addressed. SOFTWARE DESCRIPTION The software is available as a web interface (http://qtl.pzr.unirostock.de/qtlmix.php), but for a higher performance independent of our local computing power, a local installation is recommended. Hardware and software requirements (platform-independent) for the latter are described in the help page (http://qtl.pzr.unirostock.de/qtlmix_help.htm). Data sources A local database was built with data collected from public databases and recent genetic linkage studies of rodent QTLs for EAE, an animal model for MS, and QTLs for collagen- and pristane-induced arthritis (CIA, PIA), models for the human rheumatoid arthritis (RA). The database was complemented with human MS and RA predisposition loci assembled from recent genetic association studies. References to the original publications are shown for each locus in the help page (http://qtl.pzr.uni-rostock.de/qtlmix_help.htm). Genetic linkage units are standardized to physical positions with the help of a map conversion tool (Voigt et al., 2004). The boundaries of the susceptibility regions are defined by the user whenever the original data are related to a single peak marker. Additionally, QTLs available in EnsEMBL (http://www.ensembl.org) are also included and the users are offered to submit their own data. Multiple data sources may be selected and freely combined for comparisons between species. In silico fine-mapping The links between organisms are queried from the EnsEMBL Compara database (Clamp et al., 2003), which comprises information about syntenic chromosomal regions of different species. Starting from QTL regions in one source species, any region in the second source species (if any) with a sequence similarity above a selectable percentage of base pairs is regarded as a syntenic region. That similarity threshold determines the restrictiveness of the fine-mapping. Overlapping sequences and sequences separated by gaps with a maximum size selectable by the user are merged in order to avoid redundancy and to reduce complexity. We will call those merged syntenic sequences ‘consensus region’ and the genes comprised within as ‘consensus genes’. In a final step, consensus regions between the source species are checked analogously for syntenic QTL fractions of the target species. The names and IDs of the consensus genes displayed as output refer always to the species selected as target. The number of consensus genes may be determined alternatively © The Author 2004. Published by Oxford University Press. All rights reserved. For Permissions, please email: [email protected] 1737 P.Serrano-Fernández et al. on the basis of the EnsEMBL pairwise gene homology, where gene products are compared for similarity. In that case the term ‘consensus’ refers to homologous genes instead of syntenic genes. Results can be displayed as a table, summary or figure and further analysed with conventional EnsEMBL tools. Segregation of consensuses The segregation pattern of the consensuses often yields insights on the minimum number of genes included in a QTL that are presumably influencing the trait. A consensus region torn apart into distinct consensuses (included in non-overlapping QTLs) in another species strongly suggests that those consensuses are independent from each other; each of them is most probably including at least one gene influencing the phenotype of the trait. Such cases are automatically detected by the software. Validation of models Consensuses may occur by chance with a certain probability. In order to determine that probability, the software can be fed with randomly located QTLs of the same size as the original ones. This process is repeated as a permutation test up to a limit determined by the user. With an increasing number of iterations the calculated distribution tends to fit the real random distribution. That distribution yields the probability of finding by chance a certain number of genes in consensuses. Whenever the observed number of genes in consensuses is above the 95th percentile (i.e. P < 0.05), it can be concluded that the correspondence between the animal models and the human trait is not likely to be the product of chance. The validation process is robust towards differential gene density. The average gene density of the chromosomal regions that serve as an input are calculated in order to normalize the size of the QTL or susceptibility region according to the average gene density of the whole genome for their use in the permutation test. This is particularly critical for the MHC locus that is systematically analysed for association or genetic linkage studies and has an extraordinarily high-gene density. Limitations QTLs identified with a low density of genetic markers tend to be very large. Sparely studied animal models may thus blur the results of the analysis of the better known ones. Therefore, for analyses 1738 involving three species, it is always recommendable to check the performance of the consensus search and its permutation test for all three combinations of two-way comparisons. CONCLUSIONS The search for intergenomic consensuses within trait-associated loci offers a systematic approach to objectively test the degree of similarity between a human disease and its animal model. It is directly applicable to fine map in silico SLs of every trait for which animal models are available and genetic linkage or association analyses have been performed. The potential of this in silico fine-mapping technique will further increase with the inclusion of additional genomes in the future. ACKNOWLEDGEMENTS The developers of EnsEMBL are thanked for their extraordinary efforts. This work was supported by the BMBF projects FKZ 01GG9831, 01GG9841 and NBL3 (FKZ 01ZZ0108). REFERENCES Barton,A., Eyre,S., Myerscough,A., Brintnell,B., Ward,D., Ollier,W.E.R., Lorentzen,J.C., Klareskog,L., Silman,A., John,S. et al. The Arthritis Rheumatism Campaign National Repository and Worthington,J. (2001) High resolution linkage and association mapping identifies a novel rheumatoid arthritis susceptibility locus homologous to one linked to two rat models of inflammatory arthritis. Hum. Mol. Genet., 10, 1901–1906. Clamp,M., Andrews,D., Barker,D., Bevan,P., Cameron,G., Chen,Y., Clark,L., Cox,T., Cuff,J., Curwen,V. et al. (2003) Ensembl 2002: accommodating comparative genomics. Nucleic Acids Res., 31, 38–42. Doerge,R.W. (2002) Mapping and analysis of quantitative trait loci in experimental populations. Nat. Rev. Genet., 3, 43–52. Lemon,W.J., Swinton,C.H., Wang,M., Berbari,N., Wang,Y. and You,M. (2003) Single nucleotide polymorphism (SNP) analysis of mouse pulmonary adenoma susceptibility loci 1-4 for identification of candidate genes. J. Med. Genet., 40, e36. Rogner,U.C. and Alvner,P. (2003) Congenic mice. Cutting tools for complex immune disorders. Nat. Rev. Immunol., 3, 243–252. Serrano-Fernández,P. (2004) Intergenomic consensus in multifactorial inheritance loci: the case of multiple sclerosis. Genes Immun., 5, 615–620. Voigt,C., Möller,S., Ibrahim,S.M. and Serrano-Fernández,P. (2004) Non-linear conversion between genetic and physical chromosomal distances. Bioinformatics, 20, 1966–1967. Xu,C., Dai,Y., Lorentzen,J.C., Dahlman,I., Olsson,T. and Hillert,J. (2001) Linkage analysis in multiple sclerosis of chromosomal regions syntenic to experimental autoimmune disease loci. Eur. J. Hum. Genet., 9, 458–463.