Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Transcriptional regulation wikipedia , lookup
Protein moonlighting wikipedia , lookup
Protein (nutrient) wikipedia , lookup
Non-coding RNA wikipedia , lookup
Molecular cloning wikipedia , lookup
Gel electrophoresis of nucleic acids wikipedia , lookup
Silencer (genetics) wikipedia , lookup
Non-coding DNA wikipedia , lookup
Western blot wikipedia , lookup
Cre-Lox recombination wikipedia , lookup
Protein adsorption wikipedia , lookup
Expanded genetic code wikipedia , lookup
Cell-penetrating peptide wikipedia , lookup
Molecular evolution wikipedia , lookup
Gene expression wikipedia , lookup
Two-hybrid screening wikipedia , lookup
Genetic code wikipedia , lookup
Point mutation wikipedia , lookup
Artificial gene synthesis wikipedia , lookup
List of types of proteins wikipedia , lookup
Protein structure prediction wikipedia , lookup
Deoxyribozyme wikipedia , lookup
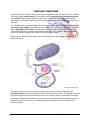
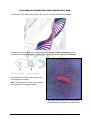
DIFFERENT LEVELS OF PROTEIN STRUCTURE PRIMARY STRUCTURE The primary structure of a protein is its unique sequence of amino acids, placed in the correct order by ribosomes under the coded instructions of DNA. e.g. Section of a polypeptide chain. peptide bond lys ile phe cys lys asp Even a minor alteration to the primary structure of a protein can have devastating consequences. For instance, a single amino acid substitution in the β chain of haemoglobin causes sickle cell disease, when valine replaces glutamic acid at a certain point in the chain. SECONDARY STRUCTURE Once a polypeptide has formed, its chain of amino acids can fold or turn upon itself as a result of hydrogen bonding, i.e. The coils and folds are the result of hydrogen bonding at regular intervals along the polypeptide chain. One common secondary structure is the alpha (α) helix which results from tight polypeptide coils held together by hydrogen bonding between every fourth amino acid. Another common secondary structure is the beta (ß) pleated sheet, in which two regions of the polypeptide chain lie parallel to each other. Hydrogen bonds between parallel parts of the backbone hold the structure together. An example of alpha helices is alpha–keratin in wool. It is coiled so it can stretch and reform the coiled fibre. Fibrin beta pleated sheets in silk and spider webs provide strength so the protein can span a large distance. α helix ß pleated sheet (Curtis H & NS Barnes, 1994) © The School For Excellence 2016 The Essentials – Unit 3 Biology – Book 1 Page 37 TERTIARY STRUCTURE A protein’s tertiary structure refers to the way a polypeptide folds and coils to form a complex molecular shape (conformation). It’s the way in which alpha helices, beta pleated sheets and random coils fold with respect to each other. Irregular bends from bonding between side chains (R groups) of amino acids in the polypeptide chain create the tertiary structure of a protein. For example, as a polypeptide folds into its functional shape, amino acids with hydrophobic (non polar) side chains are usually found in clusters in the middle of the protein, away from water. Hydrophilic side chains of other amino acids are also attracted to each other, but more commonly on the outside of the protein molecule, close to water. These interactions result in the folding, twisting and coiling of the final protein shape. Distant amino acids (in the primary structure) may in fact be close together due to the tertiary structure. (Campbell NA et al, 1999) The shape of a protein may be further reinforced by strong covalent bonds known as disulfide bridges which occur between adjacent cysteine amino acids. The sulphur atom of a cysteine amino acid bonds to the sulphur atom of a second cysteine in the amino acid chain. Along with hydrophobic interactions, hydrogen, ionic and disulfide bonds all contribute to the tertiary structure of a protein. The tertiary structure really determines the function of the particular protein. © The School For Excellence 2016 The Essentials – Unit 3 Biology – Book 1 Page 38 QUATERNARY STRUCTURE Many proteins consist of more than one polypeptide chain (e.g. haemoglobin contains two α and two ß polypeptide chains). The quaternary structure is the overall protein structure that results from the combined shape of all linked polypeptide chains. Haemoglobin is composed of four polypeptide chains: two alpha chains and two beta chains. Shadowed collagen fibres from the neck tendon of a bird seen under the electron microscope. The banding pattern is characteristic of collagen. Collagen is a fibrous protein composed of three polypeptide chains which supercoil to create a molecule of great strength. (Campbell NA & JB Reece, 2002) The forces that create the quaternary structure of proteins are the same as those which create the polypeptide’s tertiary structure. © The School For Excellence 2016 The Essentials – Unit 3 Biology – Book 1 Page 39 GLOBULAR AND FIBROUS PROTEINS Proteins can be divided into two main classes: globular and fibrous. GLOBULAR PROTEINS Globular proteins comprise “globe-like” proteins that are more or less soluble in aqueous solutions. The spherical structure is induced by the protein's tertiary structure. The molecule's non polar (hydrophobic) amino acids are bounded towards the molecule's interior whereas polar (hydrophilic) amino acids are bound outwards, allowing dipole-dipole interactions with the solvent, creating the molecule's solubility. e.g. Every membrane protein contains a variety of amino acids, some with hydrophobic side chains and others with hydrophilic chains. The amino acids with hydrophobic chains tend to be found across the centre of the protein molecule (in the hydrophobic interior of the membrane) while amino acids with hydrophilic chains tend to be located on the ends of the protein on the hydrophilic surfaces of the membrane. Hence hydrophilic portions of the protein are either exposed to the watery environment of the cytosol on the inside of the membrane or the extracellular fluid on the membrane’s exterior. (Evans B et al, 1999) Unlike fibrous proteins which only perform structural roles, globular proteins can act as: • Enzymes • Messenger molecules, e.g. hormones such as insulin • Membrane channel and carrier proteins • Regulatory proteins © The School For Excellence 2016 The Essentials – Unit 3 Biology – Book 1 Page 40 Fibrous Proteins Fibrous proteins form structural proteins which confer stiffness and rigidity to biological components, and are insoluble in aqueous solutions, e.g. • Actin and tubulin polymerise to form long, stiff fibres that comprise the cytoskeleton of cells. • Collagen and elastin are critical components of connective tissue such as cartilage. • Keratin is found in hard or filamentous structures such as hair, nails, feathers, hooves, and some arthropod exoskeletons in association with chitin. • Myosin, kinesin and dynein, which are capable of generating mechanical forces. These proteins are crucial for cellular motility of single-celled organisms and the sperm of many sexually reproducing multicellular organisms. They also generate the forces exerted by contracting muscles. FUNCTIONS OF PROTEINS Type of Protein Example Structural Collagen and elastin provide a framework in animal connective tissues, such as tendons and ligaments. the main protein of cocoons, webs, silk, cytoskeleton, fingernails. Storage Casein, the protein of milk, is a major source of amino acids for baby mammals. Transport Haemoglobin transports oxygen from the lungs to other body tissues in vertebrates. Protein carrier to carry molecule across cell membrane. Hormonal Insulin and glucagon regulate blood sugar levels. Receptor Thyroxin receptors bind to thyroxin to trigger an increase in metabolic rate of the cell. Contractile Contractile proteins are responsible for the motion of cilia and flagella. Defensive Antibodies combat bacteria, viruses etc. Enzymes Amylases break down carbohydrates in food. Neurotransmitters Endorphins reduce pain or stress by binding to nerve cell receptors. e.g. acetylcholine. Regulatory Turn genes on or off, controlling cell differentiation and activity. Hormones, enzymes. © The School For Excellence 2016 The Essentials – Unit 3 Biology – Book 1 Page 41 NUCLEIC ACIDS (POLYNUCLEOTIDES) Nucleic acids (e.g. DNA and RNA) store information that determines how organisms develop and function. Nucleotides are the monomers of the nucleic acid polymer. Nucleic acids are organic molecules containing carbon, hydrogen, oxygen, nitrogen (in the base) and phosphorus (in the phosphate group), i.e. CHONP. Nucleic acids carry instructions for making proteins by determining the amino acid sequence of the protein produced at the ribosome. • A nucleotide consists of a pentose (5-carbon) sugar, a nitrogenous base and a phosphate group (negatively charged). Label the following nucleotide: C A B • Nucleotides can link together by condensation reactions to form either RNA or DNA. • Each polynucleotide has a backbone consisting of phosphates and sugars. One of four possible nitrogen-containing bases is attached to the sugar molecule. DNA = DEOXYRIBONUCLEIC ACID DNA is the largest naturally-occurring molecule, containing the genetic instructions for all living organisms, i.e. its code is universal. Using genetic technology, DNA from one organism can be incorporated into the chromosome of any other organism and remain fully functional. E.g. transgenic pigs, cotton, mice, tomatoes, etc. DNA determines all the characteristics of all living organisms, from hair colour, to sex, to the actual type of species under investigation. • DNA is a nucleic acid, containing nucleotide subunits. Nucleotide = deoxyribose sugar + phosphate group + nitrogenous base (adenine, thymine, guanine or cytosine) C A B …. label this DNA nucleotide © The School For Excellence 2016 The Essentials – Unit 3 Biology – Book 1 Page 42 The nitrogenous bases are adenine (A), thymine (T), guanine (G), and cytosine (C). • The larger bases (adenine and guanine) are known as purines, while the smaller bases (thymine and cytosine) are called pyrimidine bases. lewallpaper.com • The size of the bases helps to determine which bases will pair. There is not enough room for two purines to pair and too much room for two pyrimidines to pair. • The sequence of base pairs along the DNA molecule is not the same in all DNA molecules or for all organisms. This is largely the reason for the wide variation, both between and within, species. © The School For Excellence 2016 The Essentials – Unit 3 Biology – Book 1 Page 43 THE DOUBLE HELIX A DNA molecule consists of two nucleotide strands. The bases on each separate strand pair together in forming a DNA molecule. Only two base pairing combinations are possible. Adenine (A) binds with thymine (T) and guanine (G) binds with cytosine (C). Using this knowledge, complete the table below: Nucleotide Base Content Organism % Guanine Yeast % Thymine 19 Bull sperm 29.5 Herpes virus 36 This feature is known as complementary base pairing. Hence, the two DNA strands are said to be antiparallel. • The base pairs are held together by weak hydrogen bonds (two between A and T; three between G and C). • If the order of bases on one strand of DNA is: A A T G T C G Then the sequence of bases on the other strand is: T T A C A G C • A phosphate group hangs from the 5’ end (fifth carbon of a deoxyribose) of a DNA strand, while a hydroxyl group hangs from the 3’ end (third carbon of a deoxyribose). (Campbell NA et al, 1999) • The DNA molecule forms a double helix shape as a result of the base pairing. While the two strands are held together by hydrogen bonds between the bases, stronger covalent bonds exist between sugars and phosphates, and between sugars and bases. • In DNA and RNA, the phosphodiester bond is the linkage between the 3' carbon of one sugar and the 5' carbon of the next sugar (i.e. between deoxyribose sugars in DNA and ribose sugars in RNA). It is a group of strong covalent bonds between the phosphorus atom in a phosphate group and two other molecules over two oxygen molecules. 3’ end 5’ end fig.cox.miami.edu © The School For Excellence 2016 The Essentials – Unit 3 Biology – Book 1 Page 44 Label the DNA molecules: A B C One nucleotide strand is known as the template or sense strand (it contains the genes) and the other is known as the antisense strand. • The sequence of base pairs along the DNA molecule varies between the DNA molecules of different organisms. The only organisms with identical DNA are clones. e.g. Identical twins. • Try this one: Template Strand: GTT GAA GCC GTC ATG CCT GAG Complementary Strand: © The School For Excellence 2016 The Essentials – Unit 3 Biology – Book 1 Page 45 LOCATION OF EUKARYOTIC AND PROKARYOTIC DNA In eukaryotic cells, DNA is found within the nucleus, mitochondria and chloroplasts. In prokaryotic cells (e.g. bacteria) DNA is found in a single circular chromosome, and most bacteria also possess small circular rings of double stranded DNA called plasmids. A B A plasmid can be used to carry genes from one organism to another. Note: The plasmids are really much smaller than depicted in the diagram above. The circular chromosome of an E. coli bacterium is revealed after the cell bursts via osmotic shock © The School For Excellence 2016 The Essentials – Unit 3 Biology – Book 1 Page 46 GENES A gene is a sequence of DNA nucleotides that codes for a particular protein/polypeptide. RNA = RIBONUCLEIC ACID Ribonucleic acid (RNA) is a single stranded nucleic acid that is synthesised from a DNA template strand in a process known as transcription. RNA is made up of nucleotides that are similar to those of DNA, however, some differences exist: An RNA nucleotide contains: • ribose sugar + phosphate group + nitrogenous base: Adenine (A), uracil (U), cytosine (C) or guanine (G). A C B …. label this RNA nucleotide • RNA is synthesised from a DNA template in the process of transcription. • Three forms of RNA exist: Messenger RNA (mRNA) which carries the DNA code to the ribosome for the purpose of making the desired protein/polypeptide. Transfer RNA (tRNA) which provides amino acids for the growing polypeptide. Ribosomal RNA (rRNA) which makes up most of a ribosome. Remembering that uracil takes the place of thymine in RNA (i.e. uracil also pairs with adenine), complete the base sequence for the following section of RNA being transcribed from the DNA molecule: DNA VS RNA SUMMARY DNA RNA No. of Nucleotide Strands Sugar Bases Functional Location © The School For Excellence 2016 The Essentials – Unit 3 Biology – Book 1 Page 47