Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Transcriptional regulation wikipedia , lookup
Western blot wikipedia , lookup
Protein adsorption wikipedia , lookup
Promoter (genetics) wikipedia , lookup
Magnesium transporter wikipedia , lookup
List of types of proteins wikipedia , lookup
Community fingerprinting wikipedia , lookup
Ancestral sequence reconstruction wikipedia , lookup
Protein structure prediction wikipedia , lookup
Expression vector wikipedia , lookup
Genome evolution wikipedia , lookup
Gene expression wikipedia , lookup
Endogenous retrovirus wikipedia , lookup
Gene expression profiling wikipedia , lookup
Protein moonlighting wikipedia , lookup
Molecular evolution wikipedia , lookup
Gene regulatory network wikipedia , lookup
Silencer (genetics) wikipedia , lookup
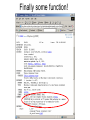
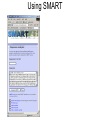
Identifying Novel Proteins So you’ve found a gene you’re interested in, you’ve blasted it against the biggest protein database you can find, and have got no real clues as to what its function might be. What do you do next… Now, apart from making sure you really have a gene on your hands, there are two ways forward: 1. If there are believable BLASTx matches, but they are all predicted genes with no functional annotation, it might still be possible to use them as stepping stones to other, more informative, BLASTx matches which would not show up as similar to the original sequence. Think of this as traversing the phylogenetic tree. 2. Accumulate as much partial data about the sequence in the hopes that it sheds light on the function. This will include functional protein domains, expression data, genomic alignment and secondary structure. It’s unlikely that you will become casually involved with higher order structures as solving or comparing these is a complex and specialised task. Orphan Genes Your lack of knowledge about protein function, having compared your sequence with all known proteins in the database, will manifest itself in two rather different ways. 1. There are good BLASTx matches with phylogenetically close organisms, but all the reasonably close hits are things like ‘Theoretical ..’ or ‘Predicted …’ or ‘Riken ..’ or ‘ORF285, chromosome 9’ – we find plenty of evidence for orthologous genes, but these are just different ways of saying but we know nothing about their function either. 2. There are no close BLASTx matches. This is a sign that this protein only exists in your organism. These are known as ‘orphan genes’, and the phenomenon is quite well documented (see reference). Obviously these are going to be quite tough to work on, as nothing like them has been seen before… Special case. There are good BLASTx matches with phylogenetically DISTANT organisms – check for contamination! An Evolutionary Analysis of Orphan Genes in Drosophila. Domazet-Loso T, Tautz D. Genome Res. 2003 Oct; 13(10): 2213-2219. Phylogenetic Stepping Stones Consider a gene which has the same function across many phyla, and suppose we consider a phylogenetic tree based on sequence similarity: species E – function known species D species C species B your species It’s possible that the sequence of the gene in your species is sufficiently similar to its orthologs in species B and C that these will show up in a BLAST search, but not in species D or E. But the sequence of the gene in species C is more similar to those in D or E. So once you get to C, and BLAST from there you might get to E, which happens to have been researched and its function known. This could be done manually, but it has been formalised in PSI BLAST, which uses iterative rounds of BLAST searching to build a more generalised model of the gene sequence, and uses this ‘evolving’ model to gradually traverse the tree. Although if not used carefully it can go horribly wrong… PSI BLAST (Position Specific Iterated – since you asked) Initial Query SREFTHYQWERLIKKTYFARFHNCMLISFSWER Matches from database SREKLSYQAERLIIWERFARFHICMLIPQSWER SREKDSYQUERLIPWTYFARFHLCMLIPKSWER New Composite Query SREFTHYQWERLIKKTYFARFHNCMLISFSWER KLS A IWER I PQ D U P TY L K 2nd Round Matches from database SREKLSYQAERLIIWERFARFHICMLIPQSWER SREKDSYQUERLIPWTYFARFHLCMLIPKSWER TUEKDSYPASAASPWERQREAFLHKLAPQSIEY And so on… PSI BLAST Round 1 results PSI BLAST Round 2 results PSI BLAST Round 3 results PSI BLAST Round 4 results Finally some function! Functional Domain Analysis Proteins are considered to have functional domains within them, specific regions of the protein which have specific tasks, and that these domains are recognisably conserved between different proteins, even though the overall similarities of the proteins may be quite low. Typical Diagram of Functional Domains on a Protein Functional Domain If you can find functional domains, you may know something about the general behaviour of your protein, even if you don’t know exactly what its function is. But, as usual, be aware that non-significant matches are quite likely to be displayed in any analysis website – and at least look for some confidence score or other measure of significance. And treat everything with a degree of caution. Main specialised sites for this type of analysis are SMART and Pfam. Which have considerable overlapping functionality. Also InterProScan which attempts to integrate all the available tools… The search methods are rather different from BLAST, and rely primarily on building up a model of the functional domain from known examples. The model is then a generalised pattern for a given domain, and your unknown sequences are searched against the models, using rather more advanced methods, typically involving Hidden Markoff models. Functional Domains and Hidden Markoff Models Once a functional domain has been identified in a number of sequences, we can build a model of it. By which we just mean a summation of our understanding of the linear sequence variants. 1234567890 YSCMVGHEAL FSCVVGHEAL YTCKVDHETL FTCQVTHEGD YSCRVKHVTL YTCVVGHEAL model 1 YF 2 ST 3 C score 5 5 10 4 ? 5 V 10 6 ? 7 H 8 ~E 10 8 9 ? 0 ~L 8 The scores may be arbitrary but they constitute the Hidden Markoff Model by which we evaluate other proteins to see if they contain this domain. As you accumulate more examples the model gets more refined, and hopefully more accurate… The higher the score of your test protein sequence against the model the more likely it is presumed to contain the domain. The model will also allow for the possibility of (expensive) gaps if the spacing of your real sequence doesn’t fit the model. Known variable regions can be modelled as cheaper gaps. Problems with Models by Example There are two conceptual problems with building models from examples. The likelihood is that the behaviour of the protein domain is related to the three dimensional shape of the molecule, and the nature of its interactions with other molecules, and as we are not taking these into account at all, we cannot expect our model to be very realistic. Secondly, the model is (by its nature) highly biased towards the examples already found, and further examples found with the help of the model will tend to reinforce any initial bias. So our model may tend to grow away from the actual consensus across all possible proteins, and lock us out of whole subsets of data. Incidentally this problem of bias is very similar to what can happen with PSI BLAST if your choice of proteins to include in your growing model diverge from your original sequence too much, and can quickly take you off into strange territory… Using SMART Exercise 1: Using Pfam and SMART Online Scratch Pad For the following exercises, you may find a scratch pad useful for keeping information from previous stages of a search. If you open up the file scratch-pad,html you’ll find you can keep text data in the outlined box. You cannot save the data, and it’ll vanish if you close the window, or refresh it! Go to the example-sequences.html file and the Protein Domain Searches section, and copy the sequence for >igf4D. Then go to the SMART web site, paste your sequence, tick at least the signal peptides box, and then run the search. While that’s running, go to the Pfam site (in a new browser window) and search the same sequence there. Compare the two results sets. Is there any difference? Should we expect any? Now go to the NCBI BLAST page, and do a protein-protein BLASTp – this may be a useful way of getting to the same data. What could you have learned about the function of this gene? If you are ahead of the rest of the group, check out the results for the much longer >titin sequence. Using SMART Exercise 2: Random Sequences Again We recall that random DNA sequences gave us alignments against real proteins when using BLASTx, and that E-values can gave us a good idea whether alignments are biologically meaningful or not. This becomes even more important when searching for subtler matches – generally shorter sequences with considerable variation allowed at most positions. Go to the file random-protein-sequences.html and copy the sequence assigned to you. Go to whichever of Pfam or SMART web sites you preferred, and run the search on your sequence. Did you find any domain hits? Were they significant? Was it possible to tell? Look at the actual alignments, if you can find out how to, and also see if you can find the model that the domain is based on. Repeat with a second sequence if you have time. Functional Motifs in Proteins We may be more familiar with functional motifs in DNA sequences, e.g. transcription factor binding sites. Here for example is the (Xenopus) TBox motif: T[CG]A[CG]AC[CG]T But short motifs are also present in protein sequences, FHA domain interaction motif 1: T..[ILA] Forkhead-associated (FHA) domain binds phosphothreonine or phosphoserine containing peptides The general problem with motifs is the number of false positives, as they are ge The ELM server (http://elm.eu.org/) ELM is a resource for predicting functional sites in eukaryotic proteins. Putative functional sites are identified by patterns (regular expressions). To improve the predictive power, context-based rules and logical filters are applied to reduce the amount of false positives Functional Motifs Reported by ELM in a Random Amino Acid Sequence Secondary Structure Analysis 3-dimensional protein structures that you see pictures of, are often composed of alph-helices and betasheets linked by less well structured sections of the protein. There are a large number of web pages devoted to analysing proteins for secondary structure, and even some which attempt to aggregate the results of several different methods (at PBIL). http://www.chemsoc.org/exemplarchem/entries/2004/durham_mcdowall/prot-3.html The weak neighbour-neighbour interactions between amino acids in a protein molecule give rise to a small number of basic structural arrangements. The two main forms are linear helical structures (alpha-helices) or sheets of parallel chains (beta sheets), the intermolecular bonds stabilise the structures. We may consider that the larger scale structure of the whole protein is built from these smaller scale structures, and as such they may give us some insight into the role of the protein even in the absence of much functional data. Is it Really a Gene? If you are really getting nowhere with your functional analysis, it may worth checking whether you have got a gene at all. There are several circumstances in which this might arise. If you are using a physical reagent like a cDNA clone, it’s possible that it contains an incomplete mRNA sequence, and you are just looking at a plausible but unreal ORF in the 3’ UTR. Or it could contain an unspliced immature transcript. Or it could even be a contamination from some other, very different species, e.g. bacteria. You may learn a lot by aligning your sequence with the organism genome, to check that it’s there and that it appears to have exons (if you would expect them). Or if you found the gene by some sort of mapping/positional analysis, and you are analysing sequences from gene models shown on the genome, check that there is real (e.g. EST) evidence for this gene – it may be purely theoretical, and entirely bogus… Genomic Analaysis It is possible that analysing the position of your gene on the genome can tell you something about its possible function. Genes sometimes function in ‘expression cassettes’, where neighbouring genes are either co-expressed, or under closely related (temporal or spatial) regulation. So if nearby genes are well characterised it would be worth considering this as a possibility. Equally, if there are obvious orthologs of this gene in other species, check out the genomic context there too. You should also be able to find out if your gene is a member of a gene family, or whether it shares small regions of coding sequence with other genes. Is there a way of doing tBLASTn or tBLASTx against the genome in your preferred browser? Expression Data Genes that are co-expressed may well be involved in the same pathways, the more intricate the pattern of co-expression, the greater the likelihood. You may find genes of known function that yours is associated with. If you found the gene originally in an expression array experiment this may be an easy way in. Alternatively there is a growing amount of expression data out there in databases, although at the moment it’s pretty difficult to systematically mine it. Various efforts are underway to facilitate this (FlyMine, ArrayExpress) tho’ it’s not clear how effective these are yet. It may also be difficult to track ‘your gene’ down in the data sets. If your gene is from an EST or cDNA sequence, see if the ESTs are clustered and check out which libraries they come from. This may tell you whether your gene is expressed in specific stages/tissues, or whether it is more ubiquitous. Exercise 3: Genuine Unknowns The sequence file identification-example-sequences.html contains 12 gene sequences from Xenopus tropicalis which superficially look hard to identify. The full cDNA sequence, is given along with the amino acid sequence translated from the presumed ORF. Pick one of the first six sequences, and start to accumulate data about it. 1. Check BLASTx – new sequences are arriving on the database all the time 2. Consider whether PSI BLAST might be useful 3. Check against the genome 4. Look for functional protein domains 5. Look for secondary structure If you find anything that looks useful keep a note of it. But bear in mind that, in the real world, you may soon be thinking about going back to the laboratory for further experimental work! Exercise 3: Results >u-one Xt6.1-CAAL21151.3 Dpy30, SCOP domains – PSI 2 rounds -> chloroplast enolase?ADP-ribosylation factor-like >u-two Xt6.1-CABJ8169.5 sipP, RUN, PDZ, PTB domains – PSI 2 rounds -> rap2 interacting protein x >u-three TEgg047e16 clear orphan, no domains, no results with PSI BLAST, Egg/Ova/Gas EST expression >u-four IMAGE:7016814 Globin domains, odd organisms, no hit on genome - worm contamination, adult whole body lib. >u-five IMAGE:5384335 signal peptide, seven transmembrane regions (!) >u-six TEgg044i21 signal peptide, coiled coils domain - PSI 2 rounds -> yeast-tht1 >u-seven Xt6.1-CAAO3979.3 coiled coils domain - PSI 2 rounds, meaningless name -> myosin (?) >u-eight TEgg001m03 single exon ORF, 5 RRM_1 domains, 5th(!) mouse hit, Rbm12 >u-nine CABE11813 long protein, no domains, no more additions after 2 rounds of PSI BLAST, all_predicted >u-ten TGas024h08 long protein, no domains, sort-of-name, PSI 2 rounds -> chloroplast RNA processing 1 1e-05...