Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Protein adsorption wikipedia , lookup
Community fingerprinting wikipedia , lookup
Promoter (genetics) wikipedia , lookup
Gene expression profiling wikipedia , lookup
Transcriptional regulation wikipedia , lookup
Expanded genetic code wikipedia , lookup
Whole genome sequencing wikipedia , lookup
RNA silencing wikipedia , lookup
Deoxyribozyme wikipedia , lookup
Ancestral sequence reconstruction wikipedia , lookup
Epitranscriptome wikipedia , lookup
Biochemistry wikipedia , lookup
RNA interference wikipedia , lookup
Cell-penetrating peptide wikipedia , lookup
Proteolysis wikipedia , lookup
Silencer (genetics) wikipedia , lookup
Non-coding DNA wikipedia , lookup
Nucleic acid analogue wikipedia , lookup
Genome evolution wikipedia , lookup
Genetic code wikipedia , lookup
Endogenous retrovirus wikipedia , lookup
Homology modeling wikipedia , lookup
Biosynthesis wikipedia , lookup
Two-hybrid screening wikipedia , lookup
Non-coding RNA wikipedia , lookup
Artificial gene synthesis wikipedia , lookup
Gene expression wikipedia , lookup
Structural alignment wikipedia , lookup
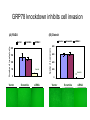
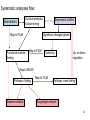
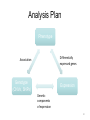
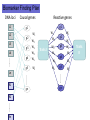
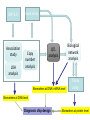
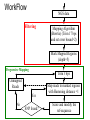
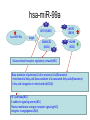
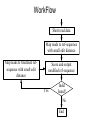
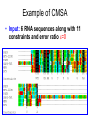
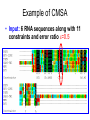
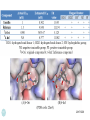
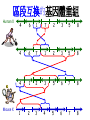
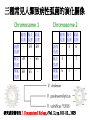
From Laboratory to Hospital – The New Challenge of Bioinformatics Researchers 唐傳義 清大資訊系 [email protected] 合作醫院及相關項目 •癌症 林口長庚口腔癌團隊 林口長庚婦癌團隊 工研院生醫中心(成大醫院食道癌團隊、 嘉義基督教醫院團隊) •感染性疾病 長庚病毒中心(流感病毒、腸病毒) 署立新竹醫院與竹東榮民醫院(孢氏不動桿菌) 清大生命科學系(幽門桿菌、白色念珠球菌) 由演講、合開課程及共同執行計畫建立合作關係 從講述「淘汰低產蛋能力雞的經驗」開始 •收集台灣土雞不同發育時期之四種蛋白質 樣品,根據實驗室分析結果,判讀蛋白質 樣品及其濃度 •記錄每隻台灣土雞之產蛋數量 •基於蛋白質樣品濃度及蛋產率,設計篩選 法提昇台灣土雞產蛋率 •目前已找出方法可在14週就可預測雞的未 來是否為低產雞,專利申請中 •合作:動物科技研究所及雞場 Egg production rate of TRFCC (n=157). (A) Total egg number of all hens, (B) hens in four groups (A) (B) 100 120 Group I Group II Group III Group IV 90 Egg production rate (%) Egg production rate (%) 100 80 60 40 80 70 60 50 40 30 20 20 10 0 0 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 week of age 25 30 35 Week of age 40 45 Lack of association of relative protein levels with total egg numbers (A) Vitellogenin (B) Apo A-I 6 24w (r=0.14) 35w (r=-0.52. p<0.01) 24w (r=0.23, p<0.01) 35w (r=0.53, p<0.01) 5 5 Relative levels of apo A-I Relative levels of vitellogenin 6 4 3 2 1 4 3 2 1 0 0 30 50 70 90 Total egg number 110 130 30 50 70 90 Total egg number 110 130 組合序號篩選法 (幾何上鄰近點問題) •將兩批雞的4個蛋白質濃度轉成序號(Rank),從一 批已知低產雞的蛋白質濃度可以找出其序號組合 碼,利用序號轉換方式搜尋出另一批雞有類似序 號組合碼的雞,預測其為低產雞 •檢查14週血清蛋白質序號組合碼 (尚未產蛋),即 已可以發現其與未來低產雞的強烈規則性 •利用組合序號篩選法可於14wk淘汰19.5%雞隻,其 中包含78.8% 之50%低產雞 臨床醫療資訊探勘與轉譯醫學 授課教師:唐傳義教授、統計學研究所謝文萍助理教授、核 子醫學科閻紫宸主任、婦癌研究中心賴瓊慧主任、神經科 學研究中心陸清松主任、腦中風中心李宗海主任 上課時間:S2S3 課程說明 本課程將從臨床醫學、醫療統計與生物資訊的整合性角 度,探討在後基因體時代如何進行臨床醫療資訊探勘與轉 譯醫學的發展研究。此課程著重於結合臨床電子病歷資訊, 臨床醫學圖像資訊,癌症臨床醫學及遺傳性疾病之基因庫 分析。本課程集合來自臨床醫師、資訊、生物統計教授等 師資,以跨領域研究實做專題方式,引入生物統計與系統 生物學相關資訊技術,將珍貴的臨床醫學資訊作加值應用, 以輔助制訂更有效的醫療決策模式。 Cdc2 cutoff 1 NDRG1 cutoff 1 EF1A cutoff 2 Biomarker Visualization: Functional Interaction Linkage Map 11,612 11,402 353,043 6,434 SNP 34,435 169,093 59,852 594,111 ………. dbEST 9 KIT FLT1 KDR ERBB 2 EGFR ESR1 PGR 1 0.107 0.142 0.137 0.084 0.022 0.01 FLT1 1 0.268 0.102 0.055 0.016 0 KDR 1 0.102 0.069 0.027 0.024 ERBB 2 1 0.231 0.043 0.026 EGFR 1 0.057 0.026 ESR1 1 0.088 PGR 1 KIT--- C-KIT, FLT1--- VEGFR-1, KIT KDR --- VEGFR-2 ERBB2 --- HER-2/neu EGFR --- EGFR ESR1 --- ER PGR --- PR the ratio of common neigh 長清計畫 Oral Cancer with 閻紫宸 Imaging and Clinical Data Psycho-social Study and Supportive Care Epidemiology and Translational Study 互補、信賴 Informatics Systems Biology Approach: 4 M’s Paradigm 清 華 團 隊 長 庚 團 隊 GRP78 knockdown inhibits cell invasion (A) FADU (B) Detroit Scramble Scramble siRNA-1 800 200 150 100 50 * P=0.016 0 Vector Vector siRNA-1 Number of invaded cells Number of invaded cells Vector 600 400 200 P=0.0013 ** 0 Scramble siRNA Vector Scramble siRNA Systematic analyses flow: Survival analyses & data mining Biomarkers Map to FILM Functional module finding Expression profiles Significant changed genes Map to FILM Clustering Up- or downregulation Map to KEGG Pathways finding Disease network Map to FILM Pathway cross linking Drug-target network 14 Pathway prediction Missing link Missing gene 15 hsa7153 hsa2099 has6256 16 長庚頭頸癌研究團隊 病 歷 資 料 長庚婦癌研究團隊 長庚癌症臨床 及研究中心 剩餘檢體 長庚大學生物技術暨檢驗學系 血清免疫 生物標記測量 長庚臨床病理科 資料探勘, 存活分析, 系統生物分析 其他生物標記測量 長庚大學生化與生醫工程系 基因晶片測量 清華大學資訊工程系 Sample Classification pN+ There are 112 patients in total. Relapse Tumor depth ECS+ SUVnodal >= 5.7 20 ECS+ SUVnodal < 5.7 14 ECS- SUVnodal >= 4.1 14 ECS- SUVnodal < 4.1 14 <= 10 months SUVnodal >= 5.5 11 <= 10 months SUVnodal < 5.5 15 > 10 months SUVnodal >= 3.6 10 > 10 months SUVnodal < 3.6 13 >= 12mm SUVtumor >= 19.3 13 >= 12mm SUVtumor < 19.3 40 <= 12mm SUVtumor >= 19.3 12 Recurrence 11 Second Primary 10 pT4N0 17 pT1N2b 12 NOABC 11 18 Data provided by CGMH: Analysis Plan Phenotype Differentially expressed genes Association Genotype (CNVs, SNPs) Expression Genetic components of expression 20 Biomarker Finding Plan DNA loci Causal genes L1 g1 L2 L3 g2 g3 L4 ………. ………. Rn W2 W2 W3 g4 W5 g5 Wn Traits I W3 W4 g2 g3 g4 W5 Wn W1 W2 W3 W4 W5 g5 ………. R2 W1 W1 ………. R1 g1 W4 Ln Reactive genes gn gn Wn Traits II SNP 6.0 Association study LOH analysis Exon array Copy number analysis Biological network analysis QTL analysis Biomarkers at DNA/ mRNA level Tissue array Biomarkers at DNA level Diagnosis chip design Biomarkers at protein level 臨床病歷 及生醫資料庫 疾病關連與 藥物-靶點作用 網路資料庫 FILM資料庫 (基因功能 網路) 臨床病歷及 生醫資料分析 平台 Gene Expression 分析模組 Survival 分析模組 SNP Array 分析模組 分析平台 生醫資料庫 Text Mining 模組 Gene Module Analysis模組 Pathway Analysis模組 Biomarker and Drug Target Prediction 模組 臨床知識探勘平台 New Module: Next-generation Sequencing Data Analysis • Roche 454 GS-FLX System • ABI SOLID sequencing system • Illumina Solexa 1G Genome Analyzer Read: short (35~100bp), small error rate, high coverage and low cost. Genome Reads Re-sequencing Problem Definition • We are given a text T=t1t2…tn, a set of patterns P1, P2, … PN , and a constant k. We are asked to find all the occurrences of Pj in T with k errors (Hamming distance). Algorithms • Indexing Genome with Hash Tables: SOAP … • Indexing Reads with Hash Tables: MAQ, ZOOM, SeqMap and RMAP, … • Indexing Genome with Suffix Array/BWT: Bowtie, … Indexing Genome with Suffix Array/BWT • Bowtie algorithm is the faster one. This is probably the fastest short read aligner to date. Length 36bp Program CPU time Bowtie 6 m 15 s Maq 3 h 52 m 54 s SOAP 16 h 44 m 3 s As Quick as Bowtie and with Ability of Alignment Distance • If there are many indels (deletions or insertion) when align sequencing data onto reference sequence, the results of alignment with Hamming Distance are not acceptable. (<40% of read mapped) Delete …ACGGATAGCTAGCTAGCATCAGGGCAGATCA… TAGCTAGCTGCATCAGGG GCTAGCTGCATCAGGGCA AGCTGCATCAGGGCAGAT +G Insert …ACGGATAGCTAGCTCATCAGGGCAGATCA… TAGCTAGCTGCATCAGGG GCTAGCTGCATCAGGGCA AGCTGCATCAGGGCAGAT WorkFlow NGS data Filtering Mapping Algorithm (Bowtie) (Trim 17 bps and set error bound=2) Mark Mapped Regions (depth=5) Progressive Mapping Trim 3 bps Unmapped Reads Yes No SNP found? Map reads to marked regions with Hamming distance =1 Score and modify the ref-sequence hsa-miR-99a 59 2 IGF1R(3480) hsa-miR-99a target SMARCD1 (6602) 13 78 WISP2 (8839) HADHB (3032) Glucocorticoid receptor regulatory network(NCI) Beta oxidation of palmitoyl-CoA to myristoyl-CoA(Reactome) mitochondrial fatty acid beta-oxidation of unsaturated fatty acids(Reactome) Fatty acid elongation in mitochondria(KEGG) IGF1 pathway(NCI) E-cadherin signaling events(NCI) Plasma membrane estrogen receptor signaling(NCI) Integrins in angiogenesis(NCI) Green: miRNA target Red: mRNA Purple: miRNA +mRNA target 感染科醫生常問的問題 • 為新的本土抗藥菌株定序 (NGS Assembly) • 了解抗藥菌株的抗藥機置 (NGS re-sequencing, SNP finding) • 利用過去資料找宿主專一性,毒性 • 設計新藥 HP Experiments (Edit distance) Reference sequence size ≒1.6M Read Number: 3074139 Read Size = 76bp % of read mapped Ref 1 Ref 2 Ref 3 Ref 4 Ref 5 Ref 6 Ref 7 error 59% 59% 55% 57% 50% 57% 67% <6 Genome Sequence Modification Ref Seq: … A C C G A T C A score 25 0 1 0 1 0 1 C score 1 30 35 0 40 1 32 G score 0 1 0 40 0 0 0 T score 1 0 0 0 0 1 0 Deletion score 0 0 0 0 0 30 0 Insertion score +A 31 Modified sequence: …ACACGCTC… … WorkFlow Short read data Map reads to ref-sequence with small edit distance Map reads to Modified refsequence with small edit distance Score and output modified ref-sequence Yes Indel found? No End error < % of read 6 mapped # of deletion # of insertion Genome Coverage Run 1 61.6% 497 435 86.6% Run 2 71.2% 235 234 88.9% Run 3 72.7% 132 157 89.6% Run 4 73.2% 78 82 90% Run 5 73.5% 37 74 90.2% 73.9% 13 9 90.4% … Run 16 找功能所需要的特殊軟體:以 RNase proteins 為例 PI RNase 1 (human pancreatic rnase) (HPR) 9.1 RNase2 (eosinophil-derived neurotoxin) (EDN) 9.2 RNase 3 (eosinophil cationic protein) (ECP) (potent anti-parasitic agent) 10.8 RNase 4 9.3 RNase 5 (angiogenin) (ANG) 9.73 RNase 6 (k6) 9.49 RNase 7 10.5 RNase 8 8.6 substrate specificity Antiviral activity Antibacterial activity for prokaryote neurotoxicity No No No Yes Yes (E. coli) Yes (required active ribonuclease activity) Yes (against RSV) Yes (E. coli) Yes (much lower than EDN) uridine-preferring No No No tRNA-specific cytidine preferring No No No No No unknown No Yes unknown No No Viral genomic DNA (antiviral activity against RSV and HIV studied in vitro) Multiple Sequence Alignment • Given s set of sequences,the MSA problem is to find an alignment of the sequences such that some object function is minimized • ie.(Sum of Pair Score) S1:ATTCG S2:AGTCG S3:ATCAG S’1:A T – T C – G MSA S’2:A – G T C – G S’ 3:A T–– CAG Cost = 8 2 4 2 MSA of 7 RNases (by Workbench3.2) MSA of 7 RNases 1ONC 1RCN 1DE3 1BC4 PDB ID 1ONC 1RCN 1DE3 1BC4 RNase Name Source Pancreatic Ribonuclease Ribonuclease A Ribonuclease -Sarcin Ribonuclease Rana Pipiens Bovine (Bos Taurus) Pancreas Aspergillus Giganteus Rana Catesbeiana Recombinant/Native pI Native Native Recombinant Native 8.96 8.64 9.17 9.20 disulfide bond 4 4 2 4 Substrate/li gand SO4 Dna (5'-D(Aptpapap)-3') X-ray/NMR X-ray X-ray NMR NMR J Biol Chem 269 pp. 21526 (1994) J.Mol.Biol. 299 pp. 1061 (2000) J Mol Biol 283 pp. 231 (1998) Reference J Mol Biol 236 pp. 1141 (1994) Multiple Sequence Alignment with Constraints MuSiC (Bioinformatics, 2004) MuSiC-ME (Memory Efficient, Bioinformatics, 2005) RE-MuSiC (Regular Expression, NAR, 2006) Multiple Sequence Alignment with Constraint • Input: (1) multiple Protein/DNA/RNA sequences and (2) several constraints (represented by regular expressions), with each consisting of known functionally, structurally or evolutionarily related residues/nucleotides of the input sequences. • Output: an optimal multiple sequence alignment in the condition that the constrained amino acids/ nucleotides should be aligned together in the alignment. CMSA: Constrained Multiple Sequence Alignment Problem • Input: a set of k sequences along with a order set of r constraints (C1, …, Cr) and an error ratio 0 <1 • Output: an optimal CMSA, say A, in which r disjoint bands B1, …, Br are in A such that d(Ci, Bi(Sj)) l(Ci) for all 1ir and 1jk. – – – – band: a block of consecutive columns in A d(x,y): the Hamming distance between x and y Bi(Sj): the fragment of Sj whose bases are all in Bi Ci: the length of Ci (also denoted by i) Example of CMSA • Input: 6 RNA sequences along with 11 constraints and error ratio =0 Example of CMSA • Input: 6 RNA sequences along with 11 constraints and error ratio =0.5 Web Interface of MuSiC http://genome.life.nctu.edu.tw/MUSIC/ Syntax of Regular Expression • The IUPAC codes for the amino acids and nucleotides are used in the regular expression. • “-”: separate the elements of a regular expression. • “[]”: the amino acids (or nucleotides) that are allowed to appear at a given position. • “{}”: The amino acids (or nucleotides) that are not accepted at a given position. • Repetition of an element is indicated by appending, immediately following that element, an integer or a pair of integers in parentheses. Example: G-[AG]-x(4)-{AG}-x(4,5) RE-MuSiC: Multiple Sequence Alignment with Regular Expression Constraints 限制型多重序列比對的軟體工具 RE-MuSiC發表在Nucleic Acids Research (Vol. 35, pp. W639-644,2007) Too many false positives ! MSA of RNase1~RNase6 - 3 active sites (His42, Lys65, His155 ) - 4 disulfide bonds (Cys50, Cys64, Cys82, Cys89, Cys98, Cys110, Cys123, Cys138 ) - MSA showed that 11 residue were conserved in RNase3, RNase2 (functionally related enzyme) and RNase1~RNase4 (sequence related proteins). Clustering of 8 RNase • Group1: ECP (RNase3) • Group3: EDN (RNase2) that is functionally related to ECP • Group2: RNase1, RNase4, RNase5 and RNase6 don’t have toxicity. • Group4: RNase7 and RNase8 have toxicity, but their toxicity is still unknown. Algorithm Voting score (1) Rat imidase Aye from G3 Blackball from G2 Vscore There are five possible coordinates: (1) Residues at rat imidase, functionally identical or related proteins (group3 or group4, respectively) and sequence related proteins (group2) are different, the score is set to zero. (2) The score is set to 1 if residues at all sequences are the same. (3) Residues common at rat imidase and proteins of group3 or group4 but differ from that of group2, the score is set to 3. (4) Residues common at imidase and group2 proteins but differ from that of group3 or group4, the score is set to –2. (5) Residues common at sequence related proteins and functional related proteins but differ from that of imidase, the score is set to zero. RNase: Comparison of MSA and our method (2) - The first row is the amino acid sequence of ECP, the second and the third row represent the total scores and their correspondent ranks respectively. - green residues: the top 5 high ones in our method - red residues: 3 active sites and 4 disulfide bonds of RNase proteins - Pro3 was verified to be associated with ECP’s toxicity by biological experiments. FAVFAT • Revealing the desired features of target enzyme or protein by voting on three different property groups aligned by threeprofile alignment method. (accepted by BMC genomic 2010) • Three properties – Target (interested sequence) – Property A (related function sequences) – Property ~A (Non-function sequences) • Goal : – Identifying amino acid residues critical for Human Enterovirus 71. – Identifying function and species-associated sites for Influenza A virus Schematic diagram of the influenza virus replication cycle Our approach • 3D-QSAR (Pharmacophore) model design • Chemical compound inference • Drug synthesis and validation 59 2017/5/23 Structure of Neuraminidase protein Influenza A virus Resolution:2.5Å Sialic acid Active Site Pharmacophore Generation A series of inhibitors Comformations generation Pharmacophore ( Hypothesis ) 6 1 Drug Screening Synthetic compounds Natural compounds ~ 5,000,000 cpds Database ~ 90,000 cpds Build Feature Model OH F HY O S O OH OH N OH O O H2N O S HN O HN NH O NH2 HBA N O OH OH N OH O OH O HO O OH NH OH N H HN HN NH O NH O F F F NH2 RA HBA NH2 X’s Spatial Feature Training inhibitors for feature model of protein X X’s Spatial Feature Search X’s Spatial recognition Inhibitor candidates of Protein X Chemical Compound Inference Problem Fujiwara et al. proposed a sequential branch-and-bound algorithm to solve this problem. H. Fujiwara, J. Wang, L. Zhao, H. Nagamochi, and T. Akutsu, “Enumerating Treelike Chemical Graphs with Given Path Frequency”, J. Chem. Inf. Model., 2008, 48(7), pp. 1345-1357. The algorithm proposed by Fujiwara cannot deal with the ring structure of chemical compounds. Moreover, the computation time increase significantly when the number of atoms grows. In this study, we proposed a Balanced Multi-Process Parallel Algorithm for Chemical Compound Inference Problem. BMPBB-CCI • Balanced Multi-Process Branch-andBound Algorithm for Chemical Compound Inference Problem • The goal of BMPBB-CCI include –Reduce computation time via parallel computing –Take care of ring structure of CCI problem 64 2009.08.21 66 2017/5/23 未來的新方向 • Mata Genomics NGS analysis GPU solution • Cancer Genomics SNP, Indel, Translocation detection • Experiment Design Introduction (Penn State project) Here, we illustrate a scenario of microbial community profiling. Fig. 1. The scenario of collecting samples from a car and the sequencing process. Windshield Genomics Sources Why GPU? Massively Parallel Processor A quiet revolution and potential build-up – Calculation: 367 GFLOPS vs. 32 GFLOPS – Memory Bandwidth: 86.4 GB/s vs. 8.4 GB/s – Until last year, programmed through graphics API GFLOPS • G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce 6800 Ultra NV35 = GeForce FX 5950 Ultra NV30 = GeForce FX 5800 – 71 GPU in every PC and workstation – massive volume and potential impact © David Kirk/NVIDIA and Wen-mei W. Hwu, 2007 ECE 498AL1, University of Illinois, Urbana-Champaign 2017/5/23 GPU Genome Rearrangements and Evolutionary Trees ROBIN (Bioinformatics, 2005) SPRING (Nucleic Acids Research, 2006) Genome Rearrangements 區段互換的基因體重組 Human X Mouse X 4 6 1 7 2 3 5 8 4 6 7 1 2 3 5 8 4 1 2 3 5 6 7 8 1 2 3 4 5 6 7 8 三種常見人類致病性弧菌的演化關係 Chromosome 1 Chromosome 2 創傷 腸炎 霍亂 弧菌 弧菌 弧菌 創傷 腸炎 霍亂 弧菌 弧菌 弧菌 創傷 弧菌 - 39 69 創傷 弧菌 - 3 6 腸炎 弧菌 39 - 65 腸炎 弧菌 3 - 7 霍亂 弧菌 69 65 - 霍亂 弧菌 6 7 - 研究成果發表在 J. Computational Biology, (Vol. 12, pp. 102-112. , 2005) 用反向工程技術 做蘭花花型基因探勘 實驗工具 RNAi RNAi (RNA interference) dsRNA被細胞雙鏈RNA特異的核酸酶切 成21-23個鹼基對的短雙鏈RNA 稱為 siRNA(small interfering RNA) siRNA與細胞某些酶和 蛋白質形成複合體,稱 為RNA誘導沉默複合體 (RNA-induced silencing complex,RISC) RISC 可識別與siRNA有同源序列的mRNA 且在特異的位點將該mRNA切斷 開花功能探勘:蘭花基因工程 • 藉由載入與目標基因有同源序列的小片段雙股 RNA 誘發 RNAi 機制來達到抑目標基因表現的效果,做為探究基因 功能之新工具。 • 若載入的小片段雙股 RNA 與多條基因的片段有同源性, 則可以一次抑制多個基因的表現。 • 藉由分析蘭花基因序列,找出可以一次抑制多個基因表現 的可能雙股 RNA 序列。 • 使用挑選出的雙股 RNA 序列,在蘭花上進行 RNAi 實驗, 觀察產生變化之性徵,快速縮小與該性徵有關之可能基因 的範圍。 • 對已經篩選過的可能基因做第二次續列分析,重複 RANi 實驗,直到目標基因的個數減少至可以一一檢測的範圍。 According to similarity, find the center sequences and determine its own group • S1 is the center of a group G if S1 has no second neighbor (Sec_nei_num(S1) =0). S2 S3 G(S1) = {S1, S2, S3, S4 , S5} S1 S5 S4 • If exist subsequence F, and HD(F,S1)=5,then F is a Far_neighor (5) of S1. F S2 4 4 S5 S3 5 4 S1 4 S4 No.13 No.15 No.21 No.194 No.171 PR1 relative 7700 genes TF No.1 …. No.272 siRNA from TF No.21 PR1 No.21 No.13 No.130 No.152 ….… 146 ….… No.74 No.112 No.168 No.176 Level 1 Level 2 No.21 No.13 PR1 PR1 No.130 No.152 7700 genes TF No.1 …. No.272 siRNA from TF No.13 No.13 PR1 siRNA from TF No.21 siRNA from TF No.176 No.21 No.13 No.130 No.152 No.74 No.112 No.168 No.176 PR1 PR1 --- 120 100 120 120 80 100 100 60 80 80 40 60 60 20 40 40 0 20 20 0 0 感謝 • • • • • • • • • • • • 實驗室全體成員 林口長庚口腔癌閻紫宸、廖俊達醫師團隊 長庚醫技鄭恩加教授實驗室團隊 林口長庚婦癌賴瓊慧醫師團隊 交大生資盧錦隆教授實驗室團隊 長庚資工林俊淵教授實驗室團隊 清大統計所謝文萍教授 清大生科王雯靜教授實驗室團隊 清大生科張大慈教授實驗室團隊 元培醫技劉明麗博士 台大植微葉信宏教授實驗室團隊 動物研究所李仁權博士