Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Gene desert wikipedia , lookup
Ridge (biology) wikipedia , lookup
Genome evolution wikipedia , lookup
Promoter (genetics) wikipedia , lookup
Genomic imprinting wikipedia , lookup
Community fingerprinting wikipedia , lookup
Endogenous retrovirus wikipedia , lookup
Secreted frizzled-related protein 1 wikipedia , lookup
Gene expression wikipedia , lookup
Gene regulatory network wikipedia , lookup
Silencer (genetics) wikipedia , lookup
Artificial gene synthesis wikipedia , lookup
Expression vector wikipedia , lookup
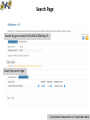
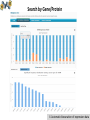
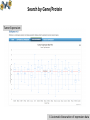
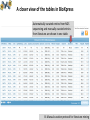
BioXpress: an integrated RNA-seqderived gene expression database for pan-cancer analysis Presented by Yang Pan Department of Biochemistry & Molecular Medicine The George Washington University Authors: Wan Q, Dingerdissen H, Fan Y, Gulzar N, Pan Y, Wu T-J, Yan C, Zhang H, Mazumder R. Database (2015). Contents • Motivation behind BioXpress • Automatic biocuration (data collection and unification pipeline) • Manual biocuration (literature mining protocol) • Pan-cancer analysis using BioXpress • Ongoing works and future plans CONTENT Biocuration of gene expression data • Several national and international projects are underway that aim to capture and analyze the expression profiles of thousands of tumors (ICGC, TCGA) and various tissues; there are already thousands of publications that describe over- and under-expression of specific genes in cancer. • An integrated view of the expression profiles of the human genes obtained from NGS technology such as RNA sequencing (RNA-seq) is important for pan-cancer analysis. • Better understand how data from publications from last several decades on cancer-related gene expression match with large-scale studies such as TCGA and ICGC I. Motivation behind BioXpress Data Sources I. Motivation behind BioXpress Automatic curation pipeline of BioXpress DEseq normalization II. Automatic biocuration of expression data Search Page Search by gene name/UniProtKB AC/RefSeq AC: Search by cancer type: II. Automatic biocuration of expression data Search by Gene/Protein II. Automatic biocuration of expression data Search by Gene/Protein Tumor Expression: II. Automatic biocuration of expression data Search by Gene/Protein Baseline expression: II. Automatic biocuration of expression data Search by Cancer Types II. Automatic biocuration of expression data -Cancer Gene Census (CGC) -Significant Mutated Genes (SMGs) -Loss of Functional sites caused by somatic mutation PubMed searching and reviewing -Manual -Semi-manual (NLP algorithms generates a list) Step3 Generating a prioritized gene list Step2 Step1 Manual curation protocol of BioXpress Mapping to unified cancer terms and inserting to database Details about Cancer Disease Ontology please refer to Lightning Talks by Dr. Raja Mazumder and our poster III. Manual curation protocol for literature mining Manual curation protocol General process: 1. Genes identified in our previous pan-cancer study were prioritized (Pan Y. et al. (2014) Nucleic Acids Res.) + proteins annotated by UniProtKB/Swiss-Prot as associated with cancer + Cancer Gene Census (http://www.sanger.ac.uk/genetics/CGP/Census/) were also targeted for manual curation. 2. Search PubMed/Google Scholar using the gene name (including synonyms) with accompanying text ‘cancer’ and ‘expression’. 3. Curator reviews title to shortlist articles which appear to contain gene expression information related to cancer and have full text available. 4. Abstracts are read to identify potential true positive articles. All such articles are downloaded and read to extract key information such as cancer type and expression information. 5. All cancer types are then mapped to Disease Ontology terms and added to the BioXpress database. III. Manual curation protocol for literature mining Manual curation protocol of BioXpress Current statistics: • 536 papers have been filtered to maintain only those focusing on human cancer after reading the ‘Abstract’ and ‘Introduction’. Among this subset, only papers including direct evidence reflecting gene expression differentiation between normal and cancer tissues were kept. • Filtering then continued with further inspection of the ‘Materials and Method’ and ‘Results’ sections of each paper. • Curators cross-check all manual curation processes. In total, 135 papers concerning 87 genes have been added to the BioXpress database through biocuration III. Manual curation protocol for literature mining A closer view of the tables in BioXpress Automatically-curated entries from NGS sequencing and manually-curated entries from literature are shown in one table. III. Manual curation protocol for literature mining Highlighting differentially expressed genes across all cancer types IV. Pan-cancer analysis based on BioXpress Highlighting differentially expressed genes based on number of patients IV. Pan-cancer analysis based on BioXpress Pan-cancer clustering of top 50 genes based on Differentially Expressed (A), Tumor (B), Baseline(C) IV. Pan-cancer analysis based on BioXpress Ongoing work and future plans • Linking to cancer-related mutation database (BioMuta 2.0, Database 2014). • Integrate with drug information (DrugVar, poster No.48) • As proteomic data become available for different cancer types through programs similar to the Clinical Proteomic Tumor Analysis Consortium (CPTAC) , we will map such data to the genes V. Ongoing works and future plans Acknowledgements • Funding: NCI and McCormick Genomic and Proteomic Center • High performance Integrated Virtual Environment (HIVE) team (GW + FDA/CBER; hive.biochemistry.gwu.edu) End