Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Koinophilia wikipedia , lookup
Therapeutic gene modulation wikipedia , lookup
Gene therapy of the human retina wikipedia , lookup
History of genetic engineering wikipedia , lookup
Genetic drift wikipedia , lookup
Gene expression profiling wikipedia , lookup
Nutriepigenomics wikipedia , lookup
Genetic engineering wikipedia , lookup
Public health genomics wikipedia , lookup
Site-specific recombinase technology wikipedia , lookup
Smith–Waterman algorithm wikipedia , lookup
Human genetic variation wikipedia , lookup
Designer baby wikipedia , lookup
Artificial gene synthesis wikipedia , lookup
Genome (book) wikipedia , lookup
Population genetics wikipedia , lookup
A Novel Algorithm of Gene Expression Programming Based on Simulated Annealing
605
A Novel Algorithm of Gene Expression Programming Based on
Simulated Annealing
CAI Zhihua, JIANG Siwei, Zhu Li , GUO Yuanyuan
(School of Computer , China University of Geosciences, Wuhan 430074, China)
Abstract: In order to solve the prediction problems of non-linear, this paper presents a hybrid parallel Gene Expression
Programming algorithm, which is based on Simulated Annealing. The combination of Simulated Annealing and genetic
mechanism enriches the search manner, and the multi-population parallel strategy optimizes the performance of algorithm.
A coarse-grained parallel computing on finite number of CPUs is implemented in MPI. Experiments on data set of GDP
in some period show that the new algorithm has better goodness of fitness, higher prediction accuracy and better
extensibility than basic GEP and traditional GP.
Key words: gene expression programming; simulated annealing; multi population strategy; MPI
1
Introduction
Gene Expression Programming(GEP), invented by Cândida Ferreira [1], is a novel genetic algorithm in
which the individuals are encoded as symbolic strings of fixed length (genotype) and then expressed as
expression trees (phenotype)with different sizes and shapes. It combines the characteristics of GA and GP, and
overcomes some drawbacks of them.
According to our previous experiments [2], using basic GEP for economic prediction can have good results.
However, similar to other basic evolutionary algorithms, the performance is vulnerable to the population size.
Using a smaller population size will also lower the diversity of the population while lowering the competitive
pressure of individuals, thus will reduce the search space and impair the performance. And adopting a larger
population size will require a long execution time, thus affect the efficiency of the algorithm. Some other factors
may also affect the performance, such as the value of genetic operators.
In this work, a hybrid parallel approach is developed, introducing the idea of Simulated Annealing(SA)and
multi-population strategy to GEP, to enrich search manners and improve the performance of the algorithm.
Comparison in china national GDP test, the new hybrid parallel approach outperforms traditional GP and simple
GEP, having better goodness of fit and higher prediction accuracy.
This paper is organized as follows. Section 2 introduces the backgrounds of GEP、SA and some related works
done by other people. In Section 3, it describes our new algorithm in detail and analyzes the performance of the
new algorithm. In Section 4, it applies the new algorithm to a data set of GDP data and compares the performance
of different algorithms. The conclusion is presented in Section 5.
2 Backgrounds
2.1
Gene Expression Programming
In GEP, the chromosome consists of a linear, symbolic string of fixed length composed of one or more genes.
Each gene is composed of a head and a tail. The head contains symbols that represent functions and terminals,
whereas the tail contains only terminals. Suppose the chosen length of the head is h, the length of the tail t can be
calculated by the equation:
t h (n 1) 1
(1)
606
Progress in Intelligence Computation & Applications
Where n is the number of arguments of the function with more arguments, e.g. if the function is addition or
division, n equals to 2; if the function is circular function, n equals to 1.
GEP is different from GA s and GP mainly in the format of phenotype representation and some specific
genetic operators used. Here is an example to illustrate how to build an expression tree(ET)from a linear
symbolic string of fixed length. Suppose the set of functions F= {+, -, ×, /, L, ~, S}, and the set of terminals
T={a, b, c, d, e,?}, Where ‘S’ represents the sin function, ‘~ ‘ represents the power of 10, ‘L’ represents the
logarithm function and ‘?’ represents the additional domain which can adopt random values. Consider the
following chromosome with length 23(the tail is shown in bold)
:
Since the chosen h equals to 11, the length of the tail t =11*(2-1)+1=12. Read the symbols from left to right and
an expression tree can be obtained as illustrated in Fig.1. The start of the gene corresponds to the root node of the
ET, and every node with its function symbol appearing in the head has the same number of branches(terminals
has no branch). In the example, the root is “S” with one branch, for the sin function has just one argument, and
the plus function has two arguments.
S
+
*
~
?
b
L
?
-0.646535
0.976867
a
Fig.1
Expression of a GEP gene(genotype)as an expression tree(phenotype)
Notice that read the symbols in ET from top to bottom, from left to right and the linear string can be obtained. So
it provides a convenient way to code and decode between genes(genotype)and expression trees(phenotype).
This kind of head-tail structure can ensure the validity of ET and the fixed-length chromosomes also
effectively control the problem of bloating which is a serious flaw for traditional GP. It also separates the
genotype with the phenotype. The genetic operations are done on the linear strings and trees with different sizes
and shapes represent the search space, which basically outperforms the performance of GAs.
2.2
Simulated Annealing and Boltzmann machine
Simulated Annealing searches the optima in a serial manner, starting from one point in the search space and
then searching its neighborhoods. Due to its Monte Carlo nature it has a certain probability of avoiding local
optima and actually reaching a global optimum.
The steps of using Boltzmann machine in SA are described as follows:
(1)Randomly chose a parent model E0, produce a offspring model E by some operations. Calculate the value
ΔE= E-E0. In hybrid algorithms that combine GA s and SA, the offspring model is produced by genetic
operations.
(2)if ΔE>0, accept E as a new model; otherwise if exp(ΔE/T)>t, accept E as a new model, where t is a
random generated values limited in the interval [-1,1], T is the simulated temperature.
The Boltzmann rule accept the worse individuals with certain probabilities while accepting the better
A Novel Algorithm of Gene Expression Programming Based on Simulated Annealing
607
individuals, thus retain the diversity of the population and avoid some certain better individuals being largely
copied to occupy the whole population. With the decrease of the temperature T, the probability of accepting worse
individuals decreases and the algorithm can eventually reach a global optimum.
2.3 Related works
Though GEP outperforms GP in our previous experiments, the problem of premature convergence that
commonly occurs in genetic algorithms is also met in the application. Whitley [3] presented that the key solution is
to balance the enhancement of selection pressure and the retaining of the diversity of the population. Some
researches have combined the idea of Simulated Annealing with genetic algorithms to improve the performance.
Wang Xue-mei [4] proposed to use the average fitness metric to adopt a reborn factor to increase the diversity of
the whole population. Wang Ling [5] used the complementary aspects of the structure and behavior of GA and SA
to develop a class of global hybrid strategy with parallel searching and probabilistic jumping abilities by
combining the mechanisms and operators of the two kinds of algorithms.
In our previous researches combining SA and GEP, the experimental results show that GEPSA outperforms
basic GEP. In general, there are several advantages of GEPSA compared with basic GEP. Firstly, it inherits the
merit of reducing selection pressure and increasing the diversity of the population from SA by using the
Boltzmann machine. Second, by combing the elitism strategy, it also ensures that the best individuals be preserved.
Meanwhile, it accelerates the speed of finding the optima.
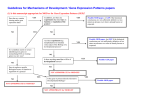
3 Hybrid parallel GEPSA (HPGEPSA)
Here we present a novel algorithm called HPGEPSA that combines the ideas of GEPSA and parallelism, and
then it is implemented on the platform of MPI software.
Initialize population 1, set
parameter of Cool Schedule
Initialize population N, set
parameter of Cool Schedule
...
Evaluate fitness
Evaluate fitness
Iterate or
Terminate
Yes
End
Iterate or
Terminate
Yes
no
no
Genetic Operators
Genetic operators
F(new)>F(old)
F(new)>F(old)
no
yes
Offspring replace
parent
no
yes
Accept offspring under
Boltzman machine
...
Offspring replace
parent
Accept offspring under
Boltzman machine
Generate new population
Generate new population
Decrease Temperature
Decrease Temperature
Find best and worst individuals
...
Find best and worst individuals
...
Find the best of all populations, and replace the worst individual of every populations
Fig.2
The flow chart of HPGEPSA
608
3.1
Progress in Intelligence Computation & Applications
The flow chart of the algorithm
The HPGEPSA algorithm which is cooperate with a numbers of CPU is implemented as follows:
3.2
Genetic operators
Many specific genetic operators are designed in GEP, such as mutation, transposition(IS transposition, RIS
transposition, Gene transposition)and recombination(one-point recombination, two-point recombination, Gene
recombination), to produce offspring population.
However, the performance is sensitive to the setting of parameters and using too many operators may affect
the performance of the algorithm. So there are just three genetic operators in HPGEPSA, described as follows:
(1)crossover. The chromosome consists of more than one gene. One-point crossover is executed in every
gene, thus multi-point crossover is executed in the chromosome.
(2)mutation. The symbols in the head can be changed to other symbols either in the function set or in the
terminal set, whereas the symbols in the tail can only be changed to other symbols in the terminal set. The new
chromosome is also valid due to the characteristic of coding method in GEP.
(3)mutation of additional domain. The values in the additional domain can be changed to other randomly
generated values limited in the interval [-10, 10].
3.3
Fitness function
Different fitness functions can be chosen depending on the real-world problems. In our experiment, we use
that one presented in literature [1]:
Ct
C (i , j ) T j
j 1
Tj
Ft ( M
*100.0) ,
(2)
where M is the range of selection, C i , j is the value returned by the individual program i for fitness case j (out of
Ct fitness cases) and
T j is the target value for fitness case j. Then f max = Ct*M. Consider a problem with 15
cases(i.e. the value of Ct is 15), if the adopted value of M equals to 100, then f max =1500.
3.4
Performance of HPGEPSA
This algorithm is implemented on the platform of software MPI. It’s compiled by Microsoft Visual C++ and
the executable file is then put under the same directory in every processor. Compared with basic GEP, HPGEPSA
has such advantages as follows:
(1)In basic GEP, many computer resource is consumed in the translation process between linear strings and
expression trees. In order to maintain a good performance, the size of population cannot be very large. But in
HPGEPSA, the hardware resource of computing processors can afford the incrementing population size. And the
time for communication which only functions after a Metropolis process is finished can be ignored comparing
with the comparatively huge computational time. Thus, the new algorithm has the merit to effectively utilize the
resources of the processors and has the ability to extend and speed up.
(2)In basic GEP, choosing larger parameters may focus on a global search, whereas smaller parameters may
focus on a local search. So it must find equilibrium between global search and local search in basic GEP. However,
in the parallel new algorithm, different subpopulations have different control parameters and thus search in
different search spaces. The coevolution of multi-populations can decrease the dependency on parameters and
have more symmetrical search ability.
(3)A mechanism of successive computation is designed in HPGEPSA. The number of genes, the length of the
head and the individuals of the population are preserved in disks after iterating certain steps of Metropolis process.
A Novel Algorithm of Gene Expression Programming Based on Simulated Annealing
609
Next time, the algorithm can start from the information in the disks. By preserving information of better
populations, it can avoid the waste of computer resource and increase the probability of finding the best
individual.
4 Application in economic prediction
In this section, we investigate the feasibility of applying HPGEPSA on a real-world data set and compare the
performance of HPGEPSA with traditional GP and basic GEP. The data set comes form paper [6], which describes
the GEP of China in some period. The second column(K)in table 1 and table 2 describes the sum of net value of
fixed assets and the average balance of floating assets in the corresponding year. The third column(L)describes
the number of employed person, including all kind of workers and peasants. The fourth column(calculation result
of GDP)describes the actual statistical data of GDP in the same year.
The aim is to obtain a prediction function for GDP with K and L being the parameters: GDP =μ (K, L). 15
cases from the year 1980 to 1994 in table 1 are used as training data to build the prediction model, while 2 cases
from 1995 to 1996 in table 2 are used as test data.
The performances of predicted models evolved by different algorithms on the training data are illustrated in
table 1. And the performances of the predicted models tested on the test cases are illustrated in table 2.
Table1
Training cases of prediction model and predicted results
Calculation result of GDP
Statistical data of
employed
Year
Capital , K
(109
(109
GDP
relative error of GDP (%)
yuan)
person , L
yuan)
GP
(104)
(109 yuan)
GP
GEP
HPGEPSA
GEP
HPGEPSA
1980
461.67
394.79
103.52
100.56
103.521
103.533
2.86
0.001
0.013
1981
176.32
413.02
107.69
111.29
107.696
107.686
3.09
0.006
0.004
1982
499.13
420.50
114.10
120.02
114.687
113.136
5.19
0.514
0.845
1983
527.22
435.60
123.40
133.63
123.374
124.535
8.29
0.021
0.920
1984
561.02
447.50
147.47
147.95
142.777
147.590
0.32
3.182
0.081
1985
632.11
455.90
175.71
171.68
173.509
173.796
2.29
1.253
1.089
1986
710.51
466.94
194.67
199.85
193.524
194.564
2.66
0.589
0.054
1987
780.12
470.93
220.00
222.45
217.766
219.497
1.14
1.015
0.229
1988
895.66
465.15
259.64
252.39
260.763
259.779
2.79
0.433
0.054
1989
988.65
469.79
283.34
282.81
287.707
283.588
0.19
1.541
0.088
1990
1075.37
470.07
310.15
308.42
310.990
314.967
0.56
0.271
1.553
1991
1184.58
479.67
342.75
349.05
346.464
342.482
1.84
1.084
0.078
1992
1344.14
485.70
411.24
403.05
410.710
410.646
1.99
0.129
0.144
1993
1688.02
503.10
536.10
529.49
531.169
526.649
1.23
0.920
1.763
1994
2221.42
513.00
725.14
714.81
728.118
724.751
1.42
0.411
0.054
Table 2
Test cases of prediction model and predicted results
Calculation result of GDP
employed person , Statistical data of GDP
Year
(109
Capital , K
L
(109 yuan)
(104 )
(109 yuan)
1995
2843.48
515.30
920.11
921.64
1996
3364.34
512.00
1102.10
1083.91
GP
relative error of GDP (%)
yuan)
GEP
HPGEPSA
GP
GEP
HPGEPSA
922.012
920.265
0.17
0.207
0.017
1107.010
1097.430
1.65
0.446
0.424
610
Progress in Intelligence Computation & Applications
The function evolved by GP is:GDP=exp ( ln (K)-576.032/L)-ln (K+L)
The function evolved by basic GEP is:
GDP tan(sin(sin( L)/ cos( K ))) sin(tan( L))*9.16 log(abs(tan(L)))
K *log(log(abs(sqrt(6.44 L) L K )))/ 6.32 log(14.46*sqrt( L) sin( K ))/sin(log( K L))
tan(log( L 5.08)* L3 / 9.58);
The function evolved by HPGEPSA is:
GDP 7.86 5.6*tan(cos( L L3)) 0.3316* K log(abs(tan( K )* L2 ))
6.58/ log(abs( L /( K tan(tan(4.42 K ))))) tan(tan( L tan(sqrt( L)) /(12.44 L)))
tan( L tan( L) / K )*2.3622
The calculation result of GDP by GEP and HPGEPSA is calculated with the predicted model, and that by GP
is obtained from [6]. The relative error of GDP is calculated by the statistical data and the calculation result of
GDP. The figures shown in bold indicate that HPGEPSA and basic GEP have better results than GP in the
corresponding year.
From Table 1, we can see that the largest relative errors of GP, basic GEP and HPGEPSA are 8.29%, 3.182%
and 1.763% respectively. Meanwhile, among the 15 training samples, the result of basic GEP has smaller relative
errors than the one of GP on 13 samples, and the result of HPGEPSA has smaller relative errors than the one of
basic GEP on 9 samples. It’s obvious that concerning the goodness of fit, basic GEP outperforms GP and
HPGEPSA outperforms basic GEP.
From table 2, we can see that HPGEPSA has the highest prediction results and a more sensible relative error
of GDP.
5 Conclusion
GEP combines the advantages of GA s and GP, and overcomes some drawbacks of these two. The specific
method of combining linear strings of fixed length with tree structures provides a novel idea to implementing
genetic algorithms.
In this paper, by introducing multi-population strategy and the idea of simulated annealing to basic GEP, we
present a novel hybrid parallel algorithm, HPGEPSA, which can effectively decrease the selection pressure in
GEP and increase the diversity of the population. Comparing with basic GEP, the new algorithm has the advantage
of avoiding premature convergence and jumping out of the suboptimal solutions. The experimental result on data
set of GDP in some period shows that HPGEPSA has better goodness of fit, higher prediction accuracy and better
extensibility than basic GEP and traditional GP.
References
[1] Ferreira, C. Gene Expression Programming: A New Adaptive Algorithm for Solving Problems . Complex Systems, 2001,13 (2):
87~129
[2] Li Qu, CAI Zhihua, Zhu Li, Zhao Yunsheng. Application of Gene Expression Programming in Predicting the Amount of Gas
Emitted from Coal Face . Journal Of Basic Science And Engineering. 2004 ,2 (1):49~54
[3] Whitley D. The GENITOR algorithm and selection pressure: Why rank based allocation reproduction trials is best. In: Schaffer
J,ed. Proceedings of the 3rd International Conference on Genetic Algorithm. Los Altos: Morgan Kaufmann Publishers, 1989.
[4] Wang Xuemei, Wang Yihe. The Combination Of Simulated Annealing And Genetic Algorithm. Chinese Journal Of Computers,
1997,20 (4) : 381~ 384
[5] Wang Ling , Zheng Dazhong. Unified framework for neighbor search algorithms and hybrid optimization strategies .Tsinghua
university (sci. & tech).2000, 40( 9): 125~128.
[6] DI Weimin , WANG Meijie. Study on prediction method for related relation based on genetic programming .HENNAN science,
2004, 22(1):92~95