Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
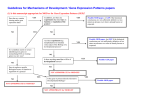
Learning from Positive and Unlabeled Examples Investigator: Bing Liu, Computer Science Prime Grant Support: National Science Foundation Problem Statement and Motivation Positive training data Unlabeled data • Given a set of positive examples P and a set of unlabeled examples U, we want to build a classifier. • The key feature of this problem is that we do not have labeled negative examples. This makes traditional classification learning algorithms not directly applicable. Learning algorithm •.The main motivation for studying this learning model is to solve many practical problems where it is needed. Labeling of negative examples can be very time consuming. Classifier Technical Approach We have proposed three approaches. • Two-step approach: The first step finds some reliable negative data from U. The second step uses an iterative algorithm based on naïve Bayesian classification and support vector machines (SVM) to build the final classifier. • Biased SVM: This method models the problem with a biased SVM formulation and solves it directly. A new evaluation method is also given, which allows us to tune biased SVM parameters. • Weighted logistic regression: The problem can be regarded as an one-side error problem and thus a weighted logistic regress method is proposed. Key Achievements and Future Goals • In (Liu et al. ICML-2002), it was shown theoretically that P and U provide sufficient information for learning, and the problem can be posed as a constrained optimization problem. • Some of our algorithms are reported in (Liu et al. ICML2002; Liu et al. ICDM-2003; Lee and Liu ICML-2003; Li and Liu IJCAI-2003). • Our future work will focus on two aspects: • Deal with the problem when P is very small • Apply it to the bio-informatics domain. There are many problems there requiring this type of learning. Gene Expression Programming for Data Mining and Knowledge Discovery Investigators: Peter Nelson, CS; Xin Li, CS; Chi Zhou, Motorola Inc. Prime Grant Support: Physical Realization Research Center of Motorola Labs Problem Statement and Motivation Genotype: sqrt.*.+.*.a.*.sqrt.a.b.c./.1.-.c.d Phenotype: Mathematical form: (a bc) a 1 cd Figure 1. Representations of solutions in GEP Technical Approach • Overview: improving the problem solving ability of the GEP algorithm by preserving and utilizing the selfemergence of structures during its evolutionary process • Constant Creation Methods for GEP: local optimization of constant coefficients given the evolved solution structures to speed up the learning process. • A new hierarchical genotype representation: natural hierarchy in forming the solution and more protective genetic operation for functional components • Dynamic substructure library: defining and reusing selfemergent substructures in the evolutionary process. • Real world data mining tasks: large data set, high dimensional feature set, non-linear form of hidden knowledge; in need of effective algorithms. • Gene Expression Programming (GEP): a new evolutionary computation technique for the creation of computer programs; capable of producing solutions of any possible form. • Research goal: applying and enhancing GEP algorithm to fulfill complex data mining tasks. Key Achievements and Future Goals • Have finished the initial implementation of the proposed approaches. • Preliminary testing has demonstrated the feasibility and effectiveness of the implemented methods: constant creation methods have achieved significant improvement in the fitness of the best solutions; dynamic substructure library helps identify meaningful building blocks to incrementally form the final solution following a faster fitness convergence curve. • Future work include investigation for parametric constants, exploration of higher level emergent structures, and comprehensive benchmark studies.