Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Hardy–Weinberg principle wikipedia , lookup
DNA paternity testing wikipedia , lookup
SNP genotyping wikipedia , lookup
Molecular Inversion Probe wikipedia , lookup
Pharmacogenomics wikipedia , lookup
Dominance (genetics) wikipedia , lookup
Microevolution wikipedia , lookup
Population genetics wikipedia , lookup
Genealogical DNA test wikipedia , lookup
Human genetic variation wikipedia , lookup
Behavioural genetics wikipedia , lookup
Genome (book) wikipedia , lookup
Heritability of IQ wikipedia , lookup
Genetic testing wikipedia , lookup
Ingredients for a successful
genome-wide association
studies: A statistical view
Scott Weiss and Christoph Lange
Channing Laboratory
Pulmonary and Critical Care Medicine
Brigham and Women’s Hospital
Boston, Massachusetts
Department of Biostatistics
Harvard School of Public Health
Boston, Massachusetts
Overview:
• What are genome-wide association studies?
• What are the statistical requirements for a successful
genome-wide association study?
• Sufficient sample sizes
• LD coverage
• Genotype quality
• Design of genome-wide association studies /
Handling of the multiple testing problem
The human genome
• 22 chromosomes
• many possible genes
• ~30,000-50,000 genes
• ~8,000,000 SNPs
How can we find disease
genes?
The human genome
How can we find disease genes?
Genotyping all loci is not possible
(not yet! )
=>
Utilization of 2 concepts:
1.) Linkage disequilibrium (LD):
Correlation of alleles at two loci
2.) Genetic association: a particular
form of a DNA polymorphism
occurs more frequently in subjects
with a phenotype of interest
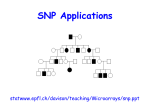
Genetic Association
Disease
Phenotype
Test for association
between phenotype
and marker locus
LD /
correlation
Marker
DSL: disease
susceptibility
locus
Test for genetic
association between
the phenotype and
the DSL
Genome-wide association study
Definition: Association analysis performed with a panel
of polymorphic markers adequately spaced to capture
most of the linkage disequilibrium information in the
entire genome in the study population.
Usually: 100,000 SNPs and more
Human
Genome
? => Test for association
Disease
Phenotype
What are the statistical requirements for a successful
genome-wide association study?
• Sufficient sample sizes
• LD coverage
• Genotyping quality
• Design of genome-wide association studies /
Handling of the multiple testing problem
Sample size requirements:
Disease
Phenotype
Test for association
between phenotype
and marker locus
LD /
correlation
Marker
DSL: disease
susceptibility
locus
Test for genetic
association between
the phenotype and
the DSL
Sufficient statistical
power is needed to
detect the association
Example for required sample sizes
Required sample sizes to achieve 80% power in a
case/control study for a significance level of 10-7
Allele freq
Odds ratio
1.25
1.5
1.75
0.1
8,859
2,608
1,350
0.2
5,283
1,616
869
0.3
4,281
1,342
727
0.4
3,886
1,301
750
What are the statistical requirements for a
successful genome-wide association study?
• Sufficient sample sizes
• LD coverage
• Genotyping quality
• Design of genome-wide association studies /
Handling of the multiple testing problem
Linkage disequilibrium (LD):
Disease
Phenotype
Test for association
between phenotype
and marker locus
LD /
correlation
Marker
DSL: disease
susceptibility
locus
Test for genetic
association between
the phenotype and
the DSL
The set of markers
has to contain a
marker that is
“sufficiently”
correlated with the
DSL so that the
genetic association at
the DSL is also
visible that the
Measures of genetic correlation between
markers
Name
Lewontin’s D’
Hill&Weir
(1994)
Levin (1953)
Yule’s Q
(1900)
Measure
Formula
D’
DAB / Dmax
R2 or Δ2
DAB2 /{pApB(1-pA)(1-pB)}
δ
DAB/{pB pab}
Q,y
DAB/{pAA pBB+ pAb paB}
The interpretation of r^2
r2 N is the “effective sample size”
If a marker M and causal gene G are in LD, then a study with
N cases and controls which measures M (but not G) will
have the same power to detect an association as a study
with r2 N cases and controls that directly measured G
Goal: The markers that are genotyped should be selected so
that they have high r^2-values (preferable at least 80%)
with the marker that are not genotyped
A good SNPs selection will be key for the success of GWAs
SNP Selection for GWA Studies
• Really a challenge for industry development, not an
investigator’s laboratory
• However, need to select a panel with adequate LD
coverage for study population
• Assessment of Illumina Sentrix HumanHap300 BeadChip
(R. Lazarus)
– Studied LD coverage of ENCODE regions: Ten 500 kb regions
that were completely sequenced in HapMap in 60 CEPH parents
– Assessed LD coverage of 6226 common ENCODE regions SNPs
(MAF > 0.1)
– Found maximum r2 of each ENCODE SNP with a SNP on
HumanHap300 Panel
Genotyping quality (QC):
Disease
Phenotype
Test for association
between phenotype
and marker locus
Test for genetic
association between
the phenotype and
the DSL
LD /
correlation
Marker
DSL: disease
susceptibility
locus
The genotype quality
has to be sufficient to
so that the genetic
association at the
DSL is also visible
that the marker locus
that are in LD with the
DSL.
For example, the dependence of the
power of a GWA on the call rate
Scenario:
•
•
•
•
Case/control study: 1,500 cases & controls
Odds-ratio: 1.5
Overall significance level: 5%
Adjustment for multiple comparisons:
Bonferroni 5%/500,000 = 10-7
=>
Power as a function of allele frequency and call rates
Power levels and avg number of false positives:
Avg call rate by genotype: 100%, 100%,100%
Allele freq
Power
Avg # false positives
0.10
27 %
0.16
0.20
71 %
0.28
0.30
91 %
0.26
0.40
93 %
0.18
Power levels and avg number of false positives:
Avg call rate by genotype: 99%, 99%, 99%
Allele freq
Power
Avg # false positives
0.10
25 %
902.36
0.20
67 %
900.07
0.30
82 %
907.72
0.40
89 %
908.12
Power levels and avg number of false positives:
Avg call rate by genotype: 98%, 98%, 98%
Allele freq
Power
Avg # false positives
0.10
24 %
2211.46
0.20
64 %
2205.91
0.30
81 %
2204.21
0.40
88 %
2197.55
Power levels and avg number of false positives:
Avg call rate by genotype: 99%, 95%, 99%
Allele freq
Power
Avg # false positives
0.10
26 %
3835.94
0.20
67 %
3845.24
0.30
84 %
3840.75
0.40
88 %
3836.39
For example, the dependence of the
power of a GWA on the call rate
Conclusion:
• Call rate has moderate effect on power (for
nearly perfect call rates)
• Call rate has large effect on number of false
positives (for nearly perfect call rates)
Situation even worse for multi-stage designs!
Genotyping quality (QC):
Disease
Phenotype
Test for association
between phenotype
and marker locus
Test for genetic
association between
the phenotype and
the DSL
LD /
correlation
Marker
DSL: disease
susceptibility
locus
The genotype quality
has to be sufficient so
that false positive rate
does not dilute the
“real” signals
Design of genome-wide association
studies/Handling of the multiple
testing problem:
“Using the same data set for screening and
testing”: An approach for family-based designs
• Balance false-negatives with false-positives
• We don’t want to test all SNPs
– “You break it, you buy it”
– Genomic screening and testing using the same
data set
• Test the “promising” SNPs
• Ignore the “less-promising” SNPs
PBAT
• PBAT* screening approach
– Family-based studies, quantitative traits
– Address multiple-comparisons
– Screen and test using the same dataset
*Van Steen K, McQueen MB, Herbert A et al. (2005). Genomic screening
and replication using the same data set in family-based association
testing. Nat Genet 37:683-691.
PBAT: Screening Step
• 1. Screen
– Use ‘between-family’ information E(X|S) to estimate
the strength of the genetic association
– Based on the estimate ab, calculate conditional power
for
– Select top N SNPs on the basis of power
E[Y] aw (X E[X | S]) ab (E[X | S])
PBAT: Testing Step
• 2. Test
– Use ‘within-family’ information
• FBAT statistic (independent of ‘between-family’ info)
– Adjust for N tests (not 500K!)
E[Y] aw (X E[X | S]) ab (E[X | S])
The 3 steps of the screening technique
(Nature Genetics (2005)):
Step
1:Step
Replace
X by
2: Select
Step
3: Replace
E(X)
E(X)
and
estimate
combination
with
by
X and
compute
power/effect
size for
maximal
power
FBAT
test statistic
SNP2 and Trait
Trait
15%
E(X1|P)
SNP 1
89%
E(X2|P)
SNP 2
35%
E(X3|P)
SNP 3
23%
E(X4|P)
SNP 4
85%
15%
E(X5|P)
SNP 5
E(X6|P)
SNP 6
This p-value does not
need to be adjusted
for multiple
comparisons!!!
P-value for FBAT statistic: 0.5%
PBAT Software implementation
–
–
–
–
family-based studies
quantitative traits & dichotomous traits
Single marker, haplotype, multi-marker
Time-to-onset, multivariate data, time-series data
– Professional version distributed by Golden Helix…
Golden Helix Software for
Illumina Whole Genome Analysis
• Golden Helix is Harvard’s PBAT commercialization partner
– Easy-to-use, user-friendly graphical interface
– Professional PBAT training and consulting
– Rapid customer support
• “Accelerating the Quest for Significance”
–
–
–
–
Powerful methods for both family and unrelated individuals
Run on hundreds of processors with distributed computing
Illumina data import directly supported
“I was able to do in 3 days what it has taken our lab 2 years to try
and do with [other] collaborations.” – Golden Helix customer
www.goldenhelix.com