Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Artificial gene synthesis wikipedia , lookup
Self-assembling peptide wikipedia , lookup
Citric acid cycle wikipedia , lookup
Protein (nutrient) wikipedia , lookup
Peptide synthesis wikipedia , lookup
Circular dichroism wikipedia , lookup
Deoxyribozyme wikipedia , lookup
Bottromycin wikipedia , lookup
Metalloprotein wikipedia , lookup
Fatty acid synthesis wikipedia , lookup
Protein adsorption wikipedia , lookup
Cell-penetrating peptide wikipedia , lookup
Genetic code wikipedia , lookup
List of types of proteins wikipedia , lookup
Amino acid synthesis wikipedia , lookup
Expanded genetic code wikipedia , lookup
Proteolysis wikipedia , lookup
Protein structure prediction wikipedia , lookup
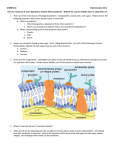
Lecture 3: Biological Molecules Background Integral themes in biological systems exemplified by macromolecules: 1. There is a natural structural hierarchy of structural level in biological organization. 2. Due to the interactions among subunits at lower organizational levels, new properties emerge as you move up the structural hierarchy. 3. Form fits function. Polymers—large molecules consisting of many identical or similar subunits connected together A. Macromolecules are polymers. Terms: Polymer—large molecules consisting of many identical or similar subunits connected together Monomer—subunit or building block of a polymer Macromolecule—large organic polymer 1. Four classes of macromolecules in living organisms a. Carbohydrates b. Lipids c. Proteins d. Nucleic acids 2. Small set of monomers is the basis for an immense variety of polymers a. All macromolecules are constructed by 40-50 different monomers b. Diversity results from the unique combination of these subunits How are macromolecules formed? Terms: Polymerization—chemical reactions that link two or more small molecules to form larger molecules with repeating structural units Condensation Reaction—polymerization reaction which form covalent links producing net removal of a water molecule for each covalent bond formed Hydrolysis—reaction that breaks covalent bonds between monomers by the addition of a water molecule Condensation Reaction 1. 2. 3. 4. During the reaction, one monomer loses a hydroxyl ion (OH-) and the other loses a hydrogen ion (H+). Water production is indirect (process will be discussed during metabolism lecture). Process requires energy. Process requires biological catalysts or enzymes. Hydrolysis 1. Hydrogen from water bonds to one monomer, hydroxyl to the adjacent monomer. Carbohydrates Carbohydrates—organic molecules made of sugars and their polymers 1. Monosaccharides—monomer building block of carbohydrates 2. Polymers are made by condensation reactions 3. Carbohydrates are classified by the number of simple sugars they contain Monosaccharides Monosaccharides are simple sugars in which C, H, and O occur in the ratio of 1:2:1 (CH2O). 1. Major nutrient source for cells; glucose is the most common 2. Photosynthetic organisms produce glucose from CO2, H2O and sunlight 3. Energy is stored in sugar’s chemical bonds and this energy is harvested by cellular respiration 4. Other organic molecules are made from the carbon skeletons of sugars 5. Sugars are the monomer used to make di- and polysaccharides Characteristics of sugars 1. An –OH is attached to each carbon except one, which double bonded to an oxygen a. Aldehyde--double bonded oxygen is on the terminal carbon (e.g., glucose) b. Ketone-- double bonded oxygen is within the carbon skeleton (e.g., fructose) 2. Carbon skeleton varies in size from three to seven carbons. Classification # of Carbons Example Triose 3 Glyceraldehyde Pentose 5 Ribose Hexose 6 Glucose 3. 4. Sugars have asymmetric carbons which allow the formation of enantiomers (e.g., glucose and galactose). a. Small differences in spatial arrangement between isomers affect molecular shape which confers distinctive biochemical properties. In aqueous solutions, many monosaccharides form ring structures. The ring structure is favored in chemical equilibrium. Disaccharides Disaccharides are double sugars that consist of two sugars joined by a glycosidic linkage. Glycosidic linkage—covalent bond formed by a condensation reaction between two sugar monomers (e.g., maltose). Disaccharide Monomers Maltose Glucose + Glucose Used in beer fermentation Lactose Glucose + Galactose Present in milk Sucrose Glucose + Fructose Table sugar Polysaccharides Polysaccharides are macromolecules that are polymers of a few hundred or thousand monosaccharides. 1. Formed by enzyme mediated condensation reactions 2. Important biologically a. Energy storage—starch and glycogen b. Structural support—cellulose and chitin Storage polysaccharides 1. Starch—glucose polymer; storage polysaccharide in plants a. Helical glucose polymer with 1-4 linkages b. Storage granules in plants called plastids c. Simplest form: amylose (unbranched) d. Amylopectin—branched polymer e. Grains and potatoes are a common source 2. Glycogen—glucose polymer; storage polysaccharide in animals a. Large glucose polymer ( 1-4 and 4-6 linkages) with a higher degree of branching than amylopectin b. Stored in muscle and liver Structural Polysaccharides 1. Cellulose—linear unbranched polymer of glucose ( 1-4 and 4-6 linkages) a. Structural component of plant cell walls b. Differs from starch based on the nature of its glycosidic linkages ( vs. ) c. Differences in glycosidic linkage result in unique three-dimensional shapes and physical properties d. Hydrogen bonding between cellulose molecules forms bundles called microfibrils that reinforce the cell wall e. Can not be digested by animals; no enzyme to digest the 1-4 linkage 2. Chitin—structural polysaccharide that is a polymer of an amino sugar a. Exoskeleton of arthropods b. Cell walls of some fungi c. Nitrogen containing group replaces –OH on carbon 2 Lipids Lipids are a diverse group of water insoluble organic compounds. They dissolve in nonpolar solvents. Important groups include fats, phospholipids and steroids. Fats Fats are macromolecules constructed from glycerol (a three carbon alcohol) and fatty acid (carboxylic acid). Glycerol (structure) Fatty acid (structure) 1. Composed of a carboxyl group on one end and an attached hydrocarbon chain (“tail”) 2. Carboxyl functional group (“head”) has properties of an acid 3. Hydrocarbon tail usually consists of an even number of carbons (16-18 are common) 4. Nonpolar C-H bonds make the molecule hydrophobic and not water soluble 5. Ester bond—bond formed between the –OH group on glycerol and the carboxyl group 6. Each of glycerol’s three OH’s can form ester bonds 7. Triaclyglycerol—a fat composed of three fatty acids bonded to one glycerol by ester linkages 8. Characteristics: a. Insoluble in water b. Variation is due to the fatty acid composition c. Fatty acids in a fat may be the same or vary d. Fatty acid vary in length e. Fatty acids may vary in the number and position of double bonds Saturated Fat Unsaturated Fat No double bonds in the fatty acid tail Has double bonds (one or more) Carbons in skeleton are bonded with Carbon double bond does not allow close maximum number of H’s packing at room temperature Solid at room temperature Liquid at room temperature Butter, lard, grease Olive, corn or peanut oil 9. Functions: a. Energy storage (C-H bond is energy rich) b. Take up less space than carbo’s; therefore more compact reservoir for energy storage c. Insulation d. Cushioning Phospholipds Phosholipids contain glycerol, two fatty acids and a phosphate group and usually a small chemical group attached to the phosphate group. 1. Third glycerol carbon is attached to a negatively charged phosphate group 2. There is usually a small (usually charged or polar) molecule attached to the phosphate group 3. Phospholipids can be quite diverse based on the nature of the fatty acids and phosphate attachements 4. Contain both a hydrophobic and hydrophilic group which affects its interaction with water 5. Form micelles—tails away from water, heads towards 6. Major component of cell membranes; bilayer with head towards aqueous environments and tails held together by interactions between tails Steroids Lipids have four fused rings of carbon with various functional groups attached. Cholesterol is a common steroid. It is a precursor for other steroids including sex hormones and bile acids. Proteins Polypeptide chain—polymers of amino acids arranged in particular linear sequences and linked by peptide bonds. Proteins are macromolecules that consist of one or more polypeptide chain organized in threedimensional space. 1. Proteins makeup 50% of cellular dry weight 2. Functions: a. Structural support b. Storage c. Transport (e.g., hemoglobin) d. Signaling (e.g., neurotransmitters) e. Signal transduction (e.g., receptors) f. Movement (e.g., contractile proteins) g. Defense (e.g., antibodies) h. Catalysis of biochemical reactions 3. Vary extensively in structure 4. Comprised of 20 amino acids Amino Acids Proteins are made up of amino acids. Amino acids (most) consist of an asymmetric carbon, called the alpha carbon, which is covalently bonded to: 1. 2. 3. 4. Hydrogen atom Carboxyl group Amino group Variable R group—this is specific to each amino acid and confers that amino acid’s unique properties At biologically relevant pH’s, both the amino and carboxyl group are ionized. Amino acids can exist in three ionic states. The state is determined by the pH of the solution. 1. Cation (-NH3+) 2. Zwitterion (-NH3+, COO-) 3. Anion (COO-) Amino acids can be grouped by the properties of their side chains. 1. Nonpolar side groups (hydrophobic); less soluble in water 2. Polar side groups (hydrophilic); soluble in water a. Uncharged polar b. Charged polar (i) Acidic side groups; Dissociated carboxyl group gives this group a negative charge (ii) Basic side groups; amino group with an extra proton gives this group a positive charge Polypeptide chains are polymers formed from amino acids monomers by peptide bonds. Peptide bond—covalent bond formed by a condensation reaction that links the carboxyl group of one amino acid to the amino group of another 1. 2. 3. 4. Polarity—peptides have ends: a. N-terminus—amino group end b. C-terminus—carboxyl group end Backbone—repeating sequence of N-C-C-N-C-C-N Length—from a few monomers to thoussands Unique linear sequences Conformation of a protein confers function Protein conformation is the three-dimension shape of a protein. Native conformation is the functional conformation found under normal physioogical conditions. 1. Occurs spontaneously, usually due to hydrophobic interactions 2. Enables recognition and bonding between proteins and other molecules 3. Stabilized by chemical bonding and weak interactions between neighboring parts of the protein molecule 4. Conferred by the linear organization of the amino acids Levels of protein structure 1. 2. 3. 4. Primary Secondary Tertiary Quaternary (two or more polypeptide chains) Primary Primary structure is the unique sequence of amino acids. 1. Determined by genes 2. Slight change in primary sequence alters protein conformation and function 3. Sequencing a. Developed by Sanger (i) Complete digest to determine relative proportion of aa’s (ii) partial digest and overlap mapping to determine sequence Secondary Secondary structure is the regular coiling and folding of a peptide backbone. Types: 1. Alpha helix 2. Beta pleated sheet Tertiary Tertiary structure is the three-dimensional shape of a protein. Results from folding of R groups and their interactions with the aqueous environment. Covalent and weak interactions contribute to tertiary structure. Weak interactions: a. Hydrogen bonding between polar side groups b. Ionic bonds between charged side chains c. Hydrophobic interactions between nonpolar side chains in a proteins interior Covalent linkage: a. Disulfide bridges; strong bond that reinforces conformation Quaternary structure Interaction between and among several polypeptide chains Nucleic Acids Genes, an organism’s heritable units, are comprised of nucleic acids. Types of nucleic acids: 1. Deoxyribonucleic acid (DNA) a. Makes up genes that indirectly direct protein synthesis b. Contain information for its own replication c. Contains coded information that programs all cell activity d. Replicated and passed to next generation e. In eukarotic cells, it is found primarily in the nucleus 2. Ribonucleic acid (RNA) a. Functions in the synthesis of proteins coded for by DNA b. Messenger RNA (mRNA) carries encoded genetic message from the nucleus to the cytoplasm c. Information flow: DNA RNA Protein d. Sequence: (i) In the nucleus, genetic message is transcribed from DNA into RNA (ii) RNA moves into the cytoplasm (iii) Genetic message is translated into a protein Nucleic acids are polymers of nucleotides linked together by condensation reactions. Nucleotide—building block of nucleic acids; comprised of a five-carbon sugar covalently bonded to a phosphate group and a nitrogenous base. 1. 2. 3. Pentose--5-carbon sugar a. Two types: (i) Ribose—found in RNA (ii) Deoxyribose—found in DNA; lacks -OH group on carbon 2 Phosphate—attached to carbon 5 of the sugar Nitrogenous base; two families: a. b. Pyrimidine—six member ring comprised of carbon and nitrogen (i) Cytosine (C) (ii) Thymine (T); only found in DNA (iii) Uracil (U); only found in RNA Purine—five member ring fused to a six member ring (i) Adenine (A) (ii) Guanine (G) Functions of nucleotides: 1. Monomer for nucleic acids 2. Energy transfer (e.g., ATP) 3. Electron receptors in enzyme controlled redox reactions (e.g., NADPH) Nucleic acids 1. Formed by phosphodiester linkages; bond between the phosphate of one nucleotide and the sugar of another 2. Backbone consists of repeating pattern of sugar-phosphate-sugar-phosphate 3. Varying nitorgenous bases are attached to the backbone 4. Genes are represented by linear sequence of nitrogenous bases which in turn is the unique code for linear sequence of amino acids in a protein. Inheritance is based on the replication of the DNA double helix 1. DNA consists of two nucleotide chains wound in a double 2. Sugar-phosphate backbone is on the outside of the helix 3. The polynucleotidee strands of DNA are held together by hydrogen bonding between paired nucleotide bases and by van der Wall attraction between stacked bases 4. Base pairing rules: a. A always with T b. G always with C c. In RNA, A always with U 5. The two strands are complementary and can serve as templates for new complementary strands 6. Most DNA molecules are long (often thousands or millions of bases)