Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Protein moonlighting wikipedia , lookup
Ancestral sequence reconstruction wikipedia , lookup
Multi-state modeling of biomolecules wikipedia , lookup
List of types of proteins wikipedia , lookup
Western blot wikipedia , lookup
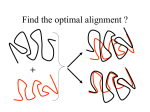
Implicit solvation wikipedia , lookup
Two-hybrid screening wikipedia , lookup
Protein adsorption wikipedia , lookup
Biochemistry wikipedia , lookup
Protein–protein interaction wikipedia , lookup
Proteolysis wikipedia , lookup
Protein domain wikipedia , lookup
Metalloprotein wikipedia , lookup
Intrinsically disordered proteins wikipedia , lookup
Nuclear magnetic resonance spectroscopy of proteins wikipedia , lookup
Protein structure prediction wikipedia , lookup
Seminar in structural bioinformatics Pairwise Structural Alignment Presented by: Dana Tsukerman 1 Outline • Definitions. • What is structural alignment? • Why structural alignment? structural alignment vs. sequence alignment • Problem definition • Background preparing the ground for the algorithm. • The algorithm 2 Outline - cont. • Implementation of the algorithm and an example of using a real software, based on the algorithm that will be presented. • Method results. • Method discussion • Method summary. • Extensions and additional features - a look ahead. • Lecture summary. 3 Definitions • Sequence alignment (remainder from last lecture), unambiguously distinguishes only between protein pairs of similar structure and nonsimilar structures when the pairwise sequence identity is high. • Structure alignment - the precise arrangement of the amino acid side chains in the three dimensional structure of the protein that dictates its function. 4 Quick rehearsal - Basic terms • Primary structure refers to the order (and sequence) of amino acids along one chain. • Some regions form regular local structure (folding patterns): • • • • Alpha helices Beta strands Collectively called secondary structure elements (SSEs). Regions connecting SSEs are loops. • Secondary structure is the description of the type and locations of the SSEs. • Tertiary structure is the 3-D coordinates of the atoms in a chain. • Quaternary structure describes the spatial packing of several folded chains (not all proteins have a quaternary structure). 5 Quick rehearsal - Basic terms regular hydrogen bond patterns of backbone atoms 6 3D observation of proteins Turn or coil Alpha-helix Beta-sheet Loop and Turn 7 3D observation of proteins “If one looks at the collection of protein structures, one is reminded of the works of an Origami artist: Certain basic folding patterns are used over and over again and cleverly modified by minor adaptations to generate a wide variety of different protein structures. Where one such folding units is insufficient to generate the required complexity, multiple domains can be combined, such as in the camel or giraffe structure on this picture.” 8 Comparison in 3D • Starting from an example: A B A B C E back D C E D 9 Comparison in 3D • Rotation and translation coordinates - 6 degrees of freedom. • The method is independent of the amino acid sequence. What does it mean? This method is insensitive to insertions, deletions and displacements of equivalents substructures betweens the molecules being compared. • Proteins with similar sequences adopt very similar structures. 10 Why 3D comparison? 11 Why 3D comparison? Wait a minute isn’t sequence comparison enough? 12 Why 3D comparison? • Structures are more conserved than sequences. • Detection of distant evolutionary relationships. • Structural alignment can imply a functional similarity that isn’t detectable from a sequence alignment. • The protein docking problem. • Structure based drug design. • Applications and implications to the protein folding problem. 13 Why 3D comparison? Cont. • For homologous proteins, this provides the “gold standard” for sequence alignment. • For nonhomologous proteins, it allows us to identify common substructures of interest. • Allows us to classify proteins into clusters, based on structural similarity. • Design and engineering of synthetic proteins. 14 Problem Definition • Input: 3-D coordinate data of the structures to be compared. • Output: regions of structural similarity (more than one, if exists), that lead to the “best” alignment. Most atoms • NP-Hard. matched with the What’s “best”? lowest RMSD 15 Our goal Find out the correspondence between the structures transformation T 16 Preparing the ground • Transformation: definition. • How can we evaluate the match we found? RMSD: rehearsal from the opening lecture. • Other methods besides the one we will discuss: and why our method is better. • Progression rule: definition. • PDB: functionality rehearsal. • Geometric Hashing: introduction. 17 3-D Transformation • Rotation - the movement of a body in such a way that any given point of that body remains at a constant distance from some other fixed point. Will be denoted by R. • Translation - the transformation of moving every point by a fixed distance in the same direction (addition of a constant vector to every point). Will be denoted by T. x Rx T x 3 • What is preserved under translation and rotation? relative distances within an object (e.g. Shapes) • In total, the 3-D transformation has 6 degrees of freedom: 3 for rotation and 3 for translation. 18 RMSD - rehearsal • A tool we use to evaluate the correspondence we found. • RMSD - Root Mean Square Deviation || x y || i RMSD(n; x, y ) 2 i i Where, n • n = number of atoms • x, y = the proteins we want to compare (structures) • We want to find 3-D transformation T*, such that the RMSD will be minimal, i.e.: RMSD(n; T *( x), y ) min T 2 || T *( x ) y || i i i n • We know how to do that in O(n). 19 RMSD - Example X (x , x , x ) 1 i 1 i1 1 i2 1 i3 i j X (x , x , x ) 2 j 2 j1 2 j2 2 j3 20 Other methods for structural alignment • Dynamic programming - building a score matrix, with a score for each pair of residues. (n5 ) or (n 4 ) • Other improvements of that method. • Simplify the problem by moving from 3D space to 2D space sacrificing the optimum result for the speed. • Comparing secondary structure elements (SSE) • Our method allows access to problems that couldn’t be approached previously by sequenceorder-dependent structural comparison methods, like the docking problem. 21 Progression rule • Rule definition: for elements i and k from one sequence and elements j and l from the other sequence, if element i is matched to element j and element k is matched to element l, and if k is to the right of i in the first sequence, the l must also be to the right of j in the second sequence. • For example, the structures we saw at the beginning couldn’t be found similar by a progression rule based method (sequence dependent). Example 22 PDB - Protein Data Bank http://www.rcsb.org/pdb/index.html • International structure database. • Archive of experimentally determined 3-D structures of biological macromolecules, together with extensive annotation. • Established at Brookhaven National Laboratories in 1971. in the beginning it held 7 structures. • In 2003, 4,831 structures were deposited to the PDB archive. • January 2004 snapshot: 23,792 released atomic coordinate entries. 23 Geometric hashing • Introduced for model-based object recognition in computer vision. • Goal: identify and locate in an image all the instances of models which appear in the system’s database. • Represents the objects to be compared in a translational and rotational invariant fashion. • On which the first step of the algorithm presented today is based. 24 Geometric hashing - cont. • We search for a way to represent object in a way we will be able to move them, and the representation won’t change. HOW? Building triangles! for n nodes: n3 triangles! The triangle’s sides length doesn’t change when we move it or rotate it, and thus invariant! 25 now please pay attention… 26 The algorithm – major steps 1. Find (relatively small) subsets of the structures that form an initial match; 2. Find clusters in initial matches that represent similar transformations; 3. Extend the clusters to contain additional matching pairs of residues. 27 Motivation remainder 28 Step 1 - Finding seed matches • Goal: search through the structures to find candidate initial matches. • Those will be referred as seed matches. • Most difficult and time consuming step. • Extensive search of the structures. • How to represent? • Remember what we talked about in geometric hashing? 29 Finding seed matches - cont. • Seed match - list of matching pairs of atoms. • Pair - correspondence between atoms from different structures. • Assumption: the structures to be compared are described by sets of interest points and their 3-D coordinates (for example: Cα atoms). • Model & Target. 30 Finding seed matches - cont. • Redefinition of the problem: is there a rotated and translated subset of the interest points of the target which matches those of the model? • Two phases: preprocessing recognition 31 Preprocessing - intro. • Goal: represent the information about the atoms of the model molecule in a rotation and translation invariant manner. • Off-line. Why? • This information will be later used in the recognition phase. • 3 non-collinear atoms specify a unique orthonormal reference frame (unique coordinate system). This will be a full reference frame. 32 Preprocessing - intro. • We won’t use a full reference frame: only 2 atoms (not unique). Those 2 atoms will be called reference set. • Each atom b in the molecule is represented by the triplet of distances of the sides of the triangle formed between b and the atoms of the reference set. Reference set: (c,a) b c a 33 Reference frames - clarification Note: the example is in the 2-D case (basic ideas the same as the 3-D case) Same shape, different reference frames 34 Preprocessing How to store the information efficiently? 35 Preprocessing • Hash table: representation of each model atom triplets of distances (from the atom to reference pair) the corresponding reference pair and the atom which obtained this key. • Note: • each atom has a redundant representation in all possible reference sets. • Many triangles can occupy the same hash table entry. 36 Preprocessing Complexity Discussion • The complexity is highly dependent on the invariants we use for hashing. • Complexity: O(n3) • n is the # of atoms in the model. But… We can do better! we will later see an optimization that will reduce the complexity to O(n2). 37 Preprocessing example Note: the example is in the 2-D case (basic ideas the same as the 3-D case) • Reference frame here is a pair of coordinates. • For instance, in cell (3, 2) we find point #2, in both reference frames, and so we store those reference frames in the hash table H(3, 2). 38 Recognition - intro. • Goal: discover candidate matching substructures in the target and model molecules. • Reference set - pair of atoms. • Each such matching substructure is based on a certain reference set, which appears both in the model and target molecules. 39 Recognition algorithm • For each reference set of the target: • Hold a vote counter for each reference set appearing in the hash table. • any ideas what will it hold? • Of course, it will hold the current number of matching atoms, and the list of matching pairs. • We will call this list the vote list. • In the beginning: the list is initialized with null. • Pick a target atom (take predefined threshold distance into consideration). 40 Recognition - cont. • Use the 3 sides of the triangle formed to compute their hash table key. • Access the hash table in this key • Extract all the model triangles in this entry. • For each triangle: • Vote_counter++; • Vote_list.add(current_triangle); • Go back to picking another atom, until we considered all of them. 41 Recognition - cont. • Check the vote counters of all the entries and consider the ones with a large # of votes. • Verification. • Choose another reference set in the target molecule and go back to the beginning. • Complexity: O(n3*k) • k indicates the # of triangles in each hash table entry. • Can be of order O(n2) after optimizing preprocessing. 42 Recognition example Note: the example is in the 2-D case (basic ideas the same as the 3-D case) For instance, let’s look on point #f, it’s coordinates are (0, 4) and so this is the key to H. H(0,4) contains the reference frame (1,3), thus it’s counter will be increased (a vote for the base pairs in H) and the pair (7, f) will be added to the matched list. Why (7, f)? 43 Step 2 - Clustering • Goal: clustering the seed matches that represent almost identical transformations. • Why clustering? Many of the seed matches obtained in step 1 represent the same transformation (but contain different pairs of matching atoms). • We use the lists of matching atoms to compute the 3-D rotation and translation, which gives us the minimal least squares distance between the target and the model. 44 Clustering - cont. • The computed 3-D transformation has 6 parameters (3 for rotation (angles) and 3 for translation (distances)). • Join similar transformations into new groups. • What's similar? • Small 6-D distance between the parameter vectors of the transformations. • Clustering algorithm (iterative): • At the beginning, each seed match forms a group represented by 6 parameters of it’s transformation. 45 Clustering - cont. • The pair of groups having the minimal distance between their transformations is chosen and a new group is formed by merging these two groups. • Who will be the parameters of the new group? • A threshold is defined to determine an end to the algorithm. • What do we have so far? • # of groups, each represents one transformation obtained by averaging the individual transformations that were joined to the group. 46 Clustering - cont. • The seed match of a group is obtained by choosing matching pairs from the original seed matches that composed the group. • But, we don’t take the union of all pairs! • Improve accuracy by choosing pairs that appear in at least certain percentage of the seed matches. • The new correspondence lists are considered more reliable than in step 1. • Complexity: o(m 2 ) m = # of seed matches to be clustered. 47 Step 3 - Extending • Goal: extend the correspondence lists from step 2 to contain additional matching pairs. • Remember! the transformation representing each group was computed by taking the average of the initial transformation. • How can we find more matches? • Compute again a transformation which gives the minimal least squares distance between the matched pairs. • The pairs that survive the second transformation are candidate additional matches. 48 Extending - intro. • N it :# of iterations to extend each seed match (small constant). • ε - maximum allowed distance. • At iteration i we extend the match to contain pairs of atoms that lie at a i maximum distance of N it 49 Extending - algorithm • For iteration i: • Find the transformation of the current match using least squares procedure. • Transform the target according to this transformation. • Remove pairs from the current match that lie in a distance larger than i N it • Extend the match by heuristic matching algorithm (given a threshold value). 50 Extending - cont. • After N it iterations, repeat the first 3 steps to refine the last matching. • Complexity: as the heuristic matching algorithm ( O ( n) or O(n3 ) ) • Output: the best extended matches. • A remainder: What is “best”? • # of matching pairs • Minimal RMSD between the matching atoms. 51 Preprocessing Optimization • We can do better (complexity wise)! • Assumption: there is spatial proximity between the atoms of the relevant matching substructures. • Conclusion: the triangles we will consider are those composed of three atoms whose atom-to-atom distances are below certain threshold. 52 Preprocessing Optimization complexity discussion • Maximum allowed distance between the atoms of the reference set: r1 = 5Å ( 1Å = 1010 m ) • Maximum allowed distance between a third point and the atoms of a reference set: r2 = 20Å • Theoretically, the complexity is now o ( n ) 2 • Practically, o( n ) • Example: 138 residues r1 r1 r2 13,359 triangles 53 Implementation - Examples http://bioinfo3d.cs.tau.ac.il/ c_alpha_match/prog.html 6LYZ vs. 2LZM Result 1 54 Implementation - Examples 1pmy vs. 1pza 1pmy vs. 1aaj 55 “Rasmol” example 56 Results of the algorithm • 3-D comparison method that isn’t constrained by linear order of the amino acid chain. • Self comparison - outputs the best match besides the trivial one. Could not be obtained in a sequence-dependent method. • Successful on a wide range of protein comparison problems. 57 Method discussion - cont. • 2 factors in structural comparison (might be conflicting): • Sequential order conservation. • Geometric pattern conservation. • Most of known methods: strict constraint has been placed on the search - sequential order conservation. • Much easier (structural alignment is NP-Hard). • Linear order conservation isn’t necessarily undesirable • Comparing proteins whose evolutionary relatedness is certain • But neither desirable • If the exact evolutionary relationship between the structures is unknown • Possible generic mutations could have occurred 58 Method discussion • Sequence independent: • Help find common 3-D folding units • Dealing with the question of convergence to a similar structure or divergence from a common ancestor. • Classical example: TIM barrel proteins. • Demonstrates that a strictly linear match is not the best geometrical match between two barrel structures. 59 Method summary • Based on the geometric hashing paradigm. • Pure 3-D approach (sequence-independent). • No a-priori knowledge of the motifs nor an initial alignment are required. • Not sensitive to insertions, deletions, gaps or displacements of equivalent substructures between the molecules being compared. • Efficient and fully automated. • Seconds for typical pairwise comparisons. • Successful on a wide range of protein comparison problems. 60 Method summary - cont. • In most of the examples, the best match corresponds to a linear alignment match. • Provides a way to compare proteins without the bias of other methods (sequence dependent). • Capable of discovering partial structural similarities. • Sole criterion: geometry! • Complexity: O(n3) 61 Extensions and additional features - a look ahead • The method can be extended to allow simultaneous and efficient comparison of a target structure with a data base of many model structure. • Protein and amino acid properties can be exploited in the definition of the reference frame and thus taken into consideration in the algorithm. • Different choices of interest points. • Strategies to reduce the # of triangles. • Assigning weights to the matches according to certain factors (recognition phase change). • Extending and adapting the technique to be used in the docking problem. 62 Lecture summary • 3D observation of proteins. • Why structural alignment? • Studies of catalogued motifs can aid in understanding the evolutionary relationship between the proteins. • The method presented allows addressing the question of # of protein structural classes found in nature. • In particular, the availability of such a library is expected to aid in the investigation of the protein folding problem. • Sequence alignment vs. structure alignment. • Geometric hashing and it’s use in the algorithm. • The algorithm and it’s implementation. • Extensions and additional features - a look ahead. 63 64 That’s it… 65