Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
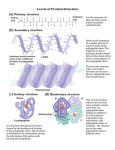
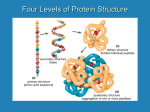
Exercise 14 Overview of Amino Acid and Protein Structure Proteins are the real workhorses of cells and living organisms. As a class, proteins are far and away the most abundant of the large (polymeric) organic molecules in cells. Proteins are the principle building blocks of cells and are especially versatile, performing thousands of distinct functions! We have already examined two very important classes of proteins: enzymes, which speed up chemical reactions in cells, and membrane transport proteins, which enable small, hydrophilic molecules to get across cell membranes. Other membrane proteins are used to mark cells so that the body knows what they are and can recognize similar or different cells. In addition, some proteins act as hormones, sending messages through the blood to specific target cells. In addition, many proteins perform two or more distinct functions. For example, the protein myosin functions as a motor protein that can move other materials around the cytoplasm of cells, as an enzyme (ATPase), and as a structural protein (thick filaments in muscle). So why are proteins more diverse than other macromolecules (e.g., nucleic acids and polysaccharides)? The diversity of proteins is due to their large number of chemically-distinct building blocks (e.g., 20 amino acids). By comparison, the nucleic acids DNA and RNA are each composed of only four different nucleotides. Moreover, the different sugars of polysaccharides and the nucleotides of nucleic acids are much more similar to each other than the different amino acids are to one another. I. The Structure of Amino Acids A. Each amino acid contains an amino group (NH2), a carboxylic acid group (COOH), a hydrogen (H) atom and a variable side chain (R group), which are each covalently bonded to a central (alpha) carbon. 1 B. When placed in aqueous solutions at pH 7 (~physiological pH), amino acids ionize and form zwitterions, e.g. the amino group is protonated and carries a positive charge, while the carboxyl group gives up its proton and carries a negative charge. After peptide bonding (see below), neither group can ionize. C. Amino acids are represented by either three-letter or single-letter codes. The name of each amino acid usually ends in “-ine.” D. Amino acids can be classified into five major groups based on the chemical properties of the side chains. The five groups are: 1. nonpolar side chains; 2. uncharged polar side chains; 3. acidic (negatively-charged) side chains; 4. basic (positively-charged) side chains; 5. special side chain structures. Note that amino acid side chains in groups 2-4 are hydrophilic. E. Structures of specific amino acid side chains in each category (see structures on next page): 1. Nonpolar (hydrophobic) side chains (8 amino acids): a. Many nonpolar amino acids have side chains that are composed of one or more hydrocarbon groups, e.g., -CH3, -CH2- or -CH-, or chains. b. Others have bulky, nonpolar rings in their side chains. 2. Uncharged polar side chains (4 amino acids): a. Three of these amino acids have a polar hydroxyl group (-OH) at the end of their side chains, which can participate in hydrogen bonds. b. The other two have polar nitrogen-bearing side chains, which can participate in hydrogen bonds. 3. Acidic (negative-charge) side chains (2 amino acids): a. the side chains of the acidic amino acids have terminal carboxyl groups that are negatively charged at physiological pH. 4. Basic (positive-charge) side chains (3 amino acids). a. the side chains of the basic amino acids all contain -NH groups in their side chains that are positively charged at physiological pH. 5. Special side chains (3 amino acids): a. Glycine is the smallest amino acid, with just a single H atom as its R group (which is usually considered nonpolar). b. Cysteine has a terminal sulfhydryl group (-SH), which can form covalent, disulfide bonds with another cysteine residue in the same or in a different polypeptide chain. c. Proline’s side chain forms a closed ring with its amino group, which usually introduces kinks into the peptide backbone. It is also considered a nonpolar side chain. 2 Figure from http://www.dur.ac.uk/stat.web/Bioinformatics/aminostructure2.JPG 3 Higher-Order Protein Structure A protein can function properly only if it is in its correct three-dimensional structure. The shape that a protein has under normal biological conditions (temperature, pH, etc.) is called its native conformation. The precise three-dimensional structure of a polypeptide chain is determined by its specific amino acid sequence (its primary structure, see below). Noncovalent interactions (the hydrophobic effect, hydrogen bonds and ionic interactions) are the primary mediators of the formation and maintenance of the threedimensional structures of proteins. Levels of Protein Structure Primary structure: the amino acid sequence of a polypeptide chain Secondary structure: local spatial arrangements of the backbone atoms of a polypeptide chain, disregarding the side chains Tertiary structure: the three-dimensional structure of a polypeptide chain (e.g., the arrangement of all the atoms, including the side chains) Quaternary structure: the number and spatial arrangement of subunits in a protein comprised of two or more polypeptide chains I. The Primary Structure of Polypeptides A. Definition: the identity and order of the amino acids (defined by the identity of the R groups) along a linear chain. B. The covalent linkage between two amino acids is called a peptide bond, which is formed by a condensation reaction between the carboxyl group of one amino acid and the amino group of the next; the amino group of one amino acid loses a H atom and the carboxyl group of the next amino acid loses its -OH group. Thus, the (carboxyl) carbon atom and the (amino) nitrogen atom, respectively, of the two amino acids now share electrons to make the peptide bond. C. A linear chain of several or more amino acids that are attached via peptide bonds is called a polypeptide. The largest known polypeptide chain contains over 25,000 amino acids and was named titan upon its discovery! Titan is present in your skeletal muscle cells. D. A polypeptide chain has a fixed polarity (e.g., the two ends of the chain are different), with a free amino group at one end (the N-terminus) and a free carboxyl group at the other end (the C-terminus). E. All polypeptide chains have an identical peptide backbone [e.g., -N-CC(carbonyl)-N- C-C(carbonyl)-etc. ]. F. The side chain of each amino acid protrudes out away from the peptide backbone. Since the peptide backbone is the same from one polypeptide chain to the next, the overall chemical properties of a polypeptide chain are dictated by its specific side chain chemistry. The linear sequence of the polypeptide refers to the number and order of the amino acids, each with its specific side chain. G. A polypeptide can also be thought of as a chain of rigid peptide bonds interspersed between flexible C-C(carbonyl) and N-C bonds, with R groups radiating out to the side. H. Polypeptide chains can fold up by bending the chain at the flexible bonds. 4 I. Note that the -N-H and -C=O (carbonyl) groups that comprise each peptide bond are both polar and can therefore participate in hydrogen bonds. II. Secondary Structure A. Definition: the local spatial arrangements of the backbone atoms of a polypeptide chains, disregarding the side chains. B. Secondary structures are created by the formation of hydrogen bonds between peptide bonds. C. Two common kinds of secondary structures: 1. (alpha)-helix: a. Formed when a contiguous region of a polypeptide chain turns regularly around itself to form a right-handed helix; the resulting structure is a compact, rigid cylinder. 2. (beta)-sheet: a. Forms when a polypeptide chain folds back and forth in such a way that different regions of the chain align side by side. Each region is a strand and a -sheet can consist of 2 to >12 strands. b. The polypeptide chain of each strand is not quite fully extended, which gives the sheets a “pleated” appearance. D. Summary notes on alpha-helices and beta-sheets 1. Both types of secondary structure provide rigidity to the polypeptide. For example, fibrous proteins are very strong and are ordered arrays of one or the other type of structure. a. Keratin (in hair and fingernails) and myosin (in muscle) consist of long, intertwined alpha-helices, which provide the proteins with mechanical strength. b. Silk is an especially strong fibrous protein that is composed of beta-sheets. 2. The core of globular proteins consists of one or the other or both types of secondary structure and provides the rigid scaffolding upon which the rest of the protein is built. III. Tertiary Structure A. Defined as the overall three-dimensional shape of a polypeptide chain. Describes the folding of the secondary structural elements and specifies the position of each atom in the polypeptide chain, including those of its side chains. B. The major determining force that defines the tertiary structure of a polypeptide chain is the hydrophobic effect, e.g., nonpolar amino acids form the core of the polypeptide and most hydrophilic amino acids are on the surface of the folded-up polypeptide. C. Noncovalent bonds (hydrogen and ionic) help stabilize tertiary structure, which can be “locked-in” by disulfide bonds, which are strong covalent bonds between two cysteine side chains. D. Many polypeptide chains are folded into sub-regions of three-dimensional structure, which often have specific functions related to their chemical and structural properties. These regions are called domains. Examples include the 5 DNA-binding domains of transcription factors, the catalytic domains of enzymes and the ligand-binding domains of cell surface receptors. IV. Quaternary Structure A. The number and spatial arrangement of subunits in proteins comprised of two or more polypeptide chains. B. The same forces that define and stabilize tertiary structures act to stably arrange subunits to form quaternary structure. C. Subunits can be identical (homomeric) or non-identical (heteromeric). D. Multi-subunit proteins (also known as oligomers) are very common. Range of possibilities exists in nature from simple homodimers to viral coats!! V. So, what do we mean by “protein?” A. The word protein (note spelling please) is used to refer to the fully assembled, functional product. 1. For some, the functional protein is a single polypeptide chain; therefore, this type of protein has no quaternary structure. 2. For many other proteins, two or more polypeptide chains have to come together to have a functional product (such as hemoglobin, which has four subunits). Thus, each polypeptide chain of these proteins has a tertiary structure and the sum total of the structure of all the subunits put together into a complex is the quaternary structure. B. Proteins usually assume one of two overall 3-D shapes: 1. Fibrous proteins: composed of regular, repeating secondary structures (e.g., intertwined alpha-helices in keratin and stacks of beta-sheets in silk) that assemble into long, elongate proteins. 2. Globular proteins: have an approximately rounded shape, and the arrangement of secondary structures in globular proteins is varied and irregular. a. The core of some globular proteins only contain alpha-helices. b. The core of some globular proteins only contain beta-sheets. c. Most globular proteins contain a combination of alpha-helices and betasheets. 3. The surface of globular proteins is irregular and chemically-complex, which will determine how the protein binds to other molecules and carries out its specific functions. Final Note: Note that sugars are covalently attached to many proteins made by living cells, so make sure to review the structure of sugars as well. 6 Macromolecules Polysaccharides, proteins and nucleic acids are all considered macromolecules. Although fatty acids can assemble into larger molecules by covalent attachment to other small molecules, these larger molecules (such as phospholipids) are not considered macromolecules since they are not polymers. A polymer is a large molecule consisting of many repeating identical or similar subunits. The individual subunits (building blocks) of polymers are called monomers. A macromolecule is a large polymer built up of organic monomers. There are three families of macromolecules: polysaccharides, proteins and nucleic acids. The monomeric subunits for each family are monosaccharides (simple sugars), amino acids and nucleotides, respectively. The Shared Features of Macromolecules Macromolecules form by the step-wise addition of similar monomeric subunits onto the end of a growing polymeric chain. Each monomeric subunit is covalently attached to the growing chain by a condensation reaction, in which one molecule of water is lost with the addition of each monomer to one end of the growing chain. This reaction requires an input of energy and a catalyst. Condensation reactions occur to form glycosidic bonds in polysaccharides, phosphodiester bonds in nucleic acids, and peptide bonds in proteins, respectively. Note that the polymeric chains of amino acids and nucleotides are always linear, whereas polymeric chains of monosaccharides can be branched as well as linear (remember the structure of glycogen). Polymers are broken down into their monomeric subunits by the reverse reaction, e.g. the simple addition of water (hydrolysis). This reverse reaction does not require energy but does usually require the assistance of a catalyst (an enzyme) to occur. The step-wise polymerization of monomeric subunits to form macromolecules is highly efficient, since the same reaction is performed over and over again by the same cellular machinery. Thus, it is easy to understand the selective advantages of the evolution of the polymerization processes. The monomeric subunits are not assembled at random. Rather, they are added in a particular order, thus defining the linear sequence of the polymer. The linear sequence is critical to the overall shape that the macromolecule assumes, and the shape of a macromolecule is a primary determinant of the specific function(s) it may have. Therefore, the mechanisms that specify polymer sequence are highly controlled! Macromolecules account for the great majority of the organic molecules in living organisms, as macromolecules mediate the most distinctive functions of cells. Note that of the macromolecules, proteins are far and away the most abundant. Proteins are the principle building blocks of cells and are especially versatile, performing thousands of distinct functions! 7 Blank Page 8 Exercise 14 Computer Modeling of 3-Dimensional Protein Structures In this lab, you will examine the 3-dimensional (3-D) structure of several different proteins, structure information for which is freely available over the Internet from the National Center for Biotechnology Information (NCBI) Web site at the National Institutes of Health. Below are instructions to do this in an Amherst College computer lab or on your own computer, starting from the NCBI Website. Note: our IT department has already downloaded the Cn3D application (see below) onto the hard drives of the Webster, Life Sciences and Lipton PCs, so you should be able to skip step 5 below when working on the College computers. 1. Go to the NCBI Website at http://www.ncbi.nlm.nih.gov/. 2. Select “Structure” in the Search box and type in the name of the protein (or an NCBI accession number) in the “for” box. Then click on ‘Go’ (or hit Enter). 3. Scroll through the list of hits and select one of interest by clicking on the blue PDB (Protein Data Base number) in the upper-left corner, above the structure thumbnail. 4. A new window will appear with more information about the structure, followed by a linear schematic of the molecule(s) that make up the structure. The latter area provides a lot of easily-discernible information, such as the number of different polypeptide chains in the structure. 5. If this is the first time using Cn3D, you will have to first download the application to your hard drive. Do so by clicking on the ‘Download Cn3D’ button on the left and follow the directions for the appropriate platform. 6. To examine a structure, return to the previous structure page (#4) and click on the ‘Structure View in Cn3D’ button. A new window will appear that asks you to Open or Save the file. Select Open. (Note: if you have not yet downloaded Cn3D, the Open button will not appear.) 7. If Cn3D does not automatically open on the College PCs, click on the ‘Start’ icon in the lower-left corner of your screen, then click on ‘All Programs.’ The Cn3D application is in the ‘NCBI’ folder (you may have to scroll down to find the ‘NCBI’ folder). 8. Once the file is open, a Structure window and a Sequence/Alignment Viewer will appear. The Sequence/Alignment window displays the amino acid sequence (in single letter code, see next page for chart). If you click on particular amino acids in this window, they will become highlighted in yellow and the position of same (also now yellow) amino acids along the peptide backbone of the 3-D structure will be highlighted in the structure window. You can close the sequence window to fill the screen with the structure. 1 9. By default, the figure that appears when one first opens the structure file is a worm model that highlights secondary structure and shows the folding of the alpha-carbon peptide backbone into regions of alpha-helices (green cylinders) and/or beta-sheets (flat yellow arrows), with arrows pointing towards the C-terminus of the polypeptide chain. The Single-Letter Amino Acid Code G A L M F W K Q E S Glycine Alanine Leucine Methionine Phenylalanine Tryptophan Lysine Glutamine Glutamic Acid Serine Gly Ala Leu Met Phe Trp Lys Gln Glu Ser P V I C Y H R N D T Proline Valine Isoleucine Cysteine Tyrosine Histidine Arginine Asparagine Aspartic Acid Threonine Pro Val Ile Cys Tyr His Arg Asn Asp Thr Some of the functions that allow you to move and manipulate the image are listed below. 1. To rotate the image in space, simply click on it with the mouse and move the mouse over the mouse pad. 2. To move the image up or down or right to left on the screen, press the Shift key as you click and drag with the mouse. 3. To magnify the central part of the screen, press the z key. Press the x key to zoom out. 4. To change the color scheme of the model, go up to Style menu button, move down to the Coloring Shortcuts arrow and over to the color scheme of interest. Let the mouse go and the model will change after a second or two. For example, if you select Molecule, each different molecule in your complex will become a different color. This is one way that you can determine how many polypeptide chains are in your protein, since each polypeptide chain is one molecule and will be a different color. 5. Use the Style menu and the Rendering Shortcuts to change to Space Fill. Then use the Style Coloring Shortcuts to color by Element. This now more closely resembles a molecular model of an entire protein including the amino acid side chains. Some element colors are as follows: carbon = black, oxygen = red, nitrogen = blue, sulfur = yellow. Hydrogen atoms are usually not represented, as they are below the limit of resolution of many structures. 6. You can confirm the number of polypeptide chains by labeling the ends of each chain (e.g., the N- and the C-termini). To do this, select Edit Global Style under the Style menu button. A new pop-up window will now appear. Select the Label tab, and click on the box that says Termini in the Protein Backbone column. Click the Apply button and the Done button. Each 2 polypeptide chain will now have its N- and C-terminus labeled. A, B, D, etc., refers to the individual polypeptide chains. Annotating structures in Cn3D Highlight (in yellow) the amino acid residue(s) that you wish to label by double-clicking on the wire backbone or by single clicking on (or dragging and highlighting) the amino acid letter(s) in the Sequence Viewer window. Select “Annotate” in the ‘Style’ drop down menu. Click on “New” in the “User Annotations” window. Type in some identifying name and short description of what you are about to label in the ‘Edit Annotation’ window, then click on ‘Edit Style’ Select ‘Labels’ then enter the number one in the ‘Spacing’ box under ‘Protein backbone’; make sure the ‘Contrast with background’ box is checked. Click ‘Done’ in this window then ‘OK’ in the ‘Edit Annotation’ window. The amino acid(s) should now be labeled with their 3-letter abbreviation and position along the polypeptide chain (from the amino terminus). Note that you can hide the labels by clicking on ‘Turn Off’ in the ‘User Annotation’ window. This window also enables you to edit the labels as you see fit. When you are satisfied, click ‘Done.’ Taking screenshots on a PC Arrange window dimensions to maximize the size of the image Press ‘Ctrl-Alt-Print Screen’ buttons simultaneously to copy screen Paste screenshot (which is on the Clipboard) into a Word or Power Point file Taking screenshots on a Mac Screenshots are easy by simultaneously pressing Apple (command)-shift-4. The mouse cursor then changes into a cross in a shaded circle. Move the cursor to the part of the screen you wish to capture, then click and drag to select and highlight this area. To put the image on the Clipboard, hold down the Control button when you release the mouse. Then, simply paste the image in whatever file you wish. If you wish to try another modeling software package, visualizing structures with Jmol is now even easier! After using the NCBI Search box and the PDB number to get to the Structure Summary page, click on the PDB ID link to the right of the structure snapshot. This will take you to the Protein Data Bank Web site. Click on the ‘View in Jmol’ button in the box to the right – hopefully the Jmol applet will load and run on your desktop. Many of the same manipulations you can do in Cn3D are easily performed by simply clicking on the circles/squares below the image that appears in the next window. 3 Assignment Nine protein structures have been selected for study. They are listed below, and each structure is followed by its Protein Data Bank (PDB) number. 1. 2. 3. 4. 5. 6. 7. 8. 9. Human adult hemoglobin (2H35) Ras, bound to GTP (1LF0) Alcohol dehydrogenase (2JHG) cAMP-binding protein (CAP), bound to cAMP and DNA (1O3T) Glutaminyl-tRNA synthetase (bound to tRNA, ATP and glutamine) (1ZJW) Potassium channel (2WLM) IGFII-Fab complex (3KR3) Centromeric nucleosome (3AN2) Human growth hormone, bound to extracellular part of prolactin receptor (1BP3) Take a few minutes to open up and look at the above protein structures. Then, sign up for and answer ONE of the following sets of questions, working with one-two other people to do so. Note: a link for on-line help with Cn3D is on page 8. 1. Hemoglobin is a complex of globin polypeptides and heme groups (non-amino acid-based, small organic structures). How many globin polypeptide chains make up a hemoglobin protein? What types of secondary structure(s) are present in the globin polypeptides? Where are the heme groups and how are they held in place by the globin polypeptide chains (e.g., how do various chemical groups orient themselves in both)? What is at the center of each heme group and what chemical interactions hold it in place? Where, specifically, is oxygen bound in the complex? A mutation that causes sickle cell disease results in the glutamic acid at amino acid residue #6 in the two beta-globin chains of a hemoglobin molecule being replaced by a valine. Find and highlight the location of glu6 in both chains. Explain how this amino acid substitution causes the hemoglobin molecules to clump together to cause sickle cell disease. 4 2. Ras is a small protein that conveys signals from one part of the cytoplasm to another. In its active form, Ras complexes with a molecule of GTP (a nucleotide). What types of secondary structures does the Ras protein have? Find the GTP molecule nestled within the polypeptide chain. If you look very carefully at the GTP molecule, you will see that it is actually a chemically-modified version of GTP. How does this synthesized molecule differ from GTP itself? Find out more about the cyclical activation/inactivation cycle of Ras. Now, explain why Ras was likely complexed with this modified version of GTP prior to X-ray crystallography. 3. Alcohol dehydrogenase is an enzyme that strips electrons away from its substrate and transfers them to the electron carrier NAD+ (a dinucleotide). How many polypeptide chains are in this enzyme? How many domains does each polypeptide chain have? Where is the active site of each polypeptide chain with respect to the domains? Find and understand the structure and function of the small NAD+ molecule in each active site of this enzyme. What else is present in the active sites of this enzyme? 4. The CAP protein is a transcription factor that binds to DNA and turns genes on or off. How many polypeptide chains does this protein have and how do they complex together? [You should refer to secondary structures and the orientation of hydrophilic and hydrophobic side chains at the interface of the two subunits to answer this question.] In its active form, each polypeptide of CAP is bound to a molecule of cyclic AMP (a modified nucleotide). Find and understand the structure and function of the cAMP molecule nestled within each polypeptide chain. Use the labeling feature to label the 5' and 3' ends of the DNA strands and the N- and Ctermini of the polypeptide chains. How does this protein complex bind to DNA (e.g., which part of the protein contains the DNA binding domains)? Note: ‘Ball and stick’ or ‘Spacefill’ provide great views of the protein-DNA interaction. Closer inspection of the Sequence Viewer will reveal that CAP is a homodimer (e.g, composed of two identical subunits). What interesting attribute of the DNA sequence that is bound by CAP is consistent with the binding of two identical polypeptide subunits? 5 5. The function of the aminoacyl tRNA synthetases is crucial for the faithful production of polypeptide chains with correct amino acid sequences. One end of a synthetase specifically recognizes the anticodon of a particular tRNA molecule, which enables the enzyme to use its active site to charge (with the assistance of an ATP molecule) the correct amino acid to the 3' end of the tRNA molecule. Examine the glutaminyl-tRNA synthetase to identify and understand how all of the above structural moieties interact. Note: a table of the codon sequences (from which one can determine the anticodon sequences of glutamine (gln) tRNA molecules) can be found at http://www.biologycorner.com/bio4/notes/codon.html. 6. Charged ions can only cross the hydrophobic core of lipid bilayers of cell membranes with the assistance of carrier or channel proteins. Describe how the four polypeptide chains of a bacterial potassium channel (PDB #2WLM) assemble to create a narrow, aqueous route of passage for potassium ions. Include a discussion of how the domains of the polypeptide chains (and the amino acids that comprise them) arrange themselves in the lipid bilayer. 7. An immunoglobulin molecule (antibody) is comprised of two heavy chains, each of which is complexed at one end with a light chain. This complex of a single light chain and the corresponding end of the heavy chain is the part of the antibody molecule that binds to the specific antigen that elicited the production of that antibody. Each of these two regions can also be isolated away from the other by enzymatic digestion to form two Fab fragments. Go to the Wikipedia site at http://en.wikipedia.org/wiki/Antibody for diagrams of the various subregions of an antibody molecule. Use the 3KR3 structure of a Fab fragment bound to insulin-like growth factor (IGF-II) to understand how antibody molecules specifically bind to their corresponding antigens. Note the disulfide bridges that stabilize the structure of both the immunoglobulin molecule and IGF-II. 8. If one straightened out any single human DNA molecule, it would be many times longer than the width of a cell nucleus. Considering that there are 46 such DNA molecules in each one of our diploid cells, organizing the DNA so that it can be efficiently expressed, reproduced and divided into two daughter cells during cell division is a complicated task for the cell. Histones are a conserved set of proteins that help package DNA into chromosomes, which are composed of bead-like subunits called nucleosomes (see pp. 187189 in your Life text). Use PDB structure #3AN2 to better understand the structure of a nucleosome, by answering the following questions (and any others that you can think of). How many histone polypeptide chains are present in one nucleosome? Label the ends of the polypeptide chains to see how the different histone molecules interact with one another. What types of secondary structure are there in a histone molecule? How does this type of secondary structure facilitate close binding interactions with the DNA molecules (e.g., what is the orientation of the histone polypeptides relative to the two short DNA molecules in this complex)? 6 Follow the steps below to identify which amino acid side chains interact with the DNA stands. Hold the mouse button down and rotate the structure so that a region of the protein that is in close proximity to the DNA is in the center of the field of view. Use the View menu and Zoom In to get a closer view. If the structure gets off-center, you can hold the shift key down and drag the structure with mouse while holding button down. You can turn on the side chains to see which ones may be interacting with the DNA. Use the Style:Rendering Shortcuts:Toggle Sidechains to turn on the amino acid side chains. Use Style: Edit Global Style to display the Global Style menu and change the rendering of the Protein side chains to Tubes to make them easier to see. Highlight the amino acids that appear to extend into a major or minor groove of the DNA by double clicking on the side chain in the structure viewer. Notice that the residues highlighted in the structure are also highlighted in the Sequence/Alignment Viewer window. Use the table on page 2 to find the names of the amino acids. You can add text (e.g., label the individual amino acids) by using the Annotate feature under the Style menu button (see Cn3D’s on-line help* for assistance). What are the names of the amino acids that most often appear to interact with the DNA? Explain how the chemical properties of these side chains make sense with respect to interacting with a DNA molecule. 9. PDB# 1BP3 is a human growth hormone-prolactin receptor complex. Open up the 1BP3 Structure Summary via the NCBI Structure database. Which molecule is growth hormone and which is the receptor? What type(s) of secondary structure does each polypeptide chain have? The 3-dimensional structure of secreted proteins and the extracellular domains of transmembrane proteins are usually stabilized by covalent disulfide bridges between cysteine residues. Where are the disulfide bridges in this complex? A zinc ion stabilizes the binding of growth hormone to its receptor. Follow the steps below to identify which amino acid side chains interact with the zinc ion to hold it in place (e.g., “coordinate” it). Hint: there are four amino acids that coordinate the zinc ion. Hold the mouse button down and rotate the structure so that the zinc ion is visible. Use the View menu and Zoom In to get a closer view of the region surrounding the zinc ion. If the zinc ion gets off-center you can hold the shift key down and drag the structure with mouse while holding button down. You can turn on the side chains to see which ones are coordinating the zinc ion. Use the Style:Rendering Shortcuts:Toggle Sidechains to turn on the amino acid side chains. Use Style: Edit Global Style to display the Global Style menu and change the rendering of the Protein side chains to Tubes to make them easier to see. 7 Highlight the amino acids that are making contact with the zinc by double clicking on the residues in the structure viewer. Notice that the residues highlighted in the structure are also highlighted in the Sequence/Alignment Viewer window. Use the table on page 2 to find the names of the amino acids. You can add text (e.g., label the individual amino acids) by using the Annotate feature under the Style menu button (see Cn3D’s on-line help* for assistance). What are the identities of the four amino acids that coordinate the zinc ion and where are they along the two different polypeptide chains? Explain how the chemical properties of the coordinating side chains make sense with respect to interacting with a zinc ion. On-Line Help with Cn3D Go to http://www.ncbi.nlm.nih.gov/Structure/CN3D/cn3dtut.shtml The "Commands' link under 'Help' in the Cn3D upper menu bar also provides a lot of helpful information (such as what the color coding is for a particular Coloring Style). * Instructions for annotating and saving images are accessible from the sixth bulleted item down the list of tutorial topics. When annotating an image, make sure that you change the spacing along the Protein backbone to 1, so that the selected residues are labeled (with their three letter code and position along the polypeptide chain for amino acids). Note that you can also annotate nucleotides if DNA or RNA is part of your structure. It is often helpful to change the background to white, to more easily see the labels once they are added. Do so by selecting Edit Global Style under Style, then clicking on the Background box in the lower right corner to change the color. You may also have to rotate the image around to get the optimal visualization of your labels. 8 Guidelines for Protein Structure Oral Reports Each pair of participants should prepare a short talk (~5 minutes) that incorporates structure analyses and answers for the question number that you selected. You are encouraged to use textbooks and on-line search engines and databases to find out more about the protein(s) you are studying. One very helpful site is Proteopedia - one can use the Browse panel in the middle of the page to search for the structures of interest using the PDB numbers on p. 4 above. Proteopedia link = http://proteopedia.org/wiki/index.php/Main_Page Note that right-clicking on the rotating Jmol image to the right of the screen that comes up after the PDB search for many structures opens a Menu window with a host of options. Right clicking on the image to the left allows you to save it, etc. The oral report should include two or more visuals, such as Power Point slides with text and captured Cn3D images or images from other on-line protein imaging sites. To capture an image in an active window of Cn3D using a PC, simultaneously press the Ctrl-Alt-Print Screen buttons. You can then paste (Ctrl-V) this screen shot directly into a Power Point slide (although you may need to re-size it after pasting it). To capture an image using a Mac, go to Applications, then Utilities and open Grab. Under Capture on the Menu bar, select Window and follow the directions in the new dialogue box that opens. See below for Mac to PC conversions. The FirstGlance in Jmol site (http://molvis.sdsc.edu/fgij/) allows one to perform many of the same manipulations as in Cn3D, again by typing the PDB number in the search box. FirstGlance has the added bonus of a pop-up window that appears in the lower-left panel, which describes what it is you are actually doing when you select one of the commands in the upper-left panel. To get the same information in Cn3D, you have to go up to Help on the Menu bar and select Commands, then the Structure Windows Menu link, and then keep clicking on links to get where you want to go. However, note that many of the manipulations in FirstGlance and Cn3D use the same color coding, etc. Go to the Polyview-3D site (http://polyview.cchmc.org/polyview3d.html) to construct protein structures that will rotate directly in your Power Point show! Detailed guidelines for how to do this are on the next page. There is also a link to an on-line Tutorial in the upper left of the Menu bar on the Polyview-3D home page. In your presentation, you may alternatively insert a link to the Proteopedia Web site to show a rotating image. Save your Power Point presentation to the ‘2012 Protein Structure Talks’ folder on the ‘sumgen’ H: storage drive (and also to a thumb drive, if you want to bring it home with you). Using a Mac to prepare a Power Point show with images that will show on the classroom PC Follow the instructions below to embed a Cn3D image in a Power Point show in a way that the classroom PC can find the image just as well as your Mac. When you have an image you like in Cn3D, under "FILE" select "Export PNG" Give the image a name and destination as you normally would for saving a file Within your ppt slide under "INSERT" select "Picture" and then find your file Make sure your ppt file runs well on a campus PC 9 Obtaining an animated image for your Power Point show Go to the Polyview 3-D Web site at http://polyview.cchmc.org/polyview3d.html and enter the PDB number of the structure of interest into the PDB ID box. Select considered as ‘Biological unit (PISA)’ in the next box to the right. In the rows that follow (e.g., Overall Structure View, Chain Color and Rendering, etc.), click on the + icon and select any options that you want in your structure. When the image is designed the way you want, select ‘Animation’ for ‘Type of request’ under’ Quick links’ to the left. Click ‘Submit’ and prepare to wait! Work on something else, as it may take up to an hour for the animated image to come back. When the image is completed, a new Polyview 3-D browser window will open with the image rotating in space. To save a copy for insertion into a Power Point file, right click on the rotating image and select ‘Save Image As…’, giving your file some distinctive name! Then, go to the Power Point slide that you want to insert the image into, and under ‘Insert’ select ‘Picture’ and click over to the saved image. Note that the pasted image will be static until Slide Show is selected. (Mac Users: it is a little more complicated to do this, but hopefully possible; contact Prof. Emerson if you run into trouble.) Below the animated image in the Polyview window are two sets of numbered boxes. Click on any of these boxes to examine (left set) and then download (right box, with the same, corresponding number as the left box) static images from different vantage points of the rotating structure. For more details, go to the Polyview tutorial at http://polyview.cchmc.org/tutor/tutor_intro.html Read below if you would like to now save your Polyview image on their Web site: Images are saved into the Gallery, which provides access to deposited images from POLYVIEW-2D (and MM) and POLYVIEW-3D (static and animations). To deposit an image into the Gallery in the first place, click on the Gallery link at the top of the Polyview results page. To find your saved image, you must now visit the Gallery, which you access from the home page of POLYVIEW-3D (the Gallery link is in the top menu). Here’s the direct link just in case the above does not work: http://polyview.cchmc.org/gallery.html . Once in the Gallery, simply find and click on the thumbnail for your image. The new page will show you exactly the same output you got after submitting a regular request to POLYVIEW-3D. In addition, you may add your own commentaries/annotation. The URL shown in the address line of the browser is the permanent link to your image. Just bookmark it to return any time later. 10 Comment Sheet for Protein Structure Oral Report Student Names:________________________________________________________ Question #___________ ______ Presentation was clear and of the appropriate length (~4-5 minutes) ______ Sufficient background on protein provided (e.g., location and function in organism, etc.) ______ Questions in lab manual were answered ______ One or more 3-D models presented and described (e.g., what the different colors represented, important parts labeled, etc,) ______ Slides were of good quality (e.g., readable, informative but not too dense) 11 Blank Page 12