Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Point mutation wikipedia , lookup
Gene expression wikipedia , lookup
G protein–coupled receptor wikipedia , lookup
Biochemistry wikipedia , lookup
Western blot wikipedia , lookup
Interactome wikipedia , lookup
Ancestral sequence reconstruction wikipedia , lookup
Metalloprotein wikipedia , lookup
Two-hybrid screening wikipedia , lookup
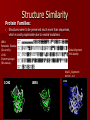
Protein Structure Nimrod Rubinstein Bioinformatics Seminar Protein Synthesis 1. 2. 3. 4. Attachment of correct amino acids (AAs) to their corresponding tRNAs. Initiation: forming the initiation complex. Elongation: sequentially forming peptide bonds. Termination: synthesis is terminated and the polypeptide is released. From Sequence to Structure Structure Hierarchies: Primary structure: the sequence of AAs covalently bound along the backbone of the polypeptide chain. Gly Ala Cys O ψ N ф Cα C Cα N ф ψ N C O -1800 ≤ ф ≤ 1800 -1800 ≤ ψ ≤ C ф Cα ψ O From Sequence to Structure Structure Hierarchies: Secondary structure: local conformation of some part of the polypeptide. β Sheet α Helix Anti Parallel Parallel From Sequence to Structure Structure Hierarchies: Tertiary structure: the overall 3-dimensional arrangement of all the atoms in the protein. From Sequence to Structure Structure Hierarchies: Quaternary structure: some proteins contain two or more separate polypeptide chains, which may be identical or different. Globular Fibrous From Sequence to Structure Additional Parameters: Surface accessibility: The surface area of the molecule that is exposed to the solvent, derived from the complete structure. •VDW surface: the surface area of an atom. •Connolly surface: the interface between the molecule and the solvent sphere (conventionally with r = 1.4Å) . •Solvent accessible surface: the path of the center of the solvent sphere rolled ov the VDW surface. •Relative accessibility = (SAS)/(maxSAS) •maxSAS = SAS(Gly-X-Gly) From Sequence to Structure Additional Parameters: Coordination number: •The number of structure stabilizing contacts each residue in the structure makes. •Computation: encapsulating an AA with a sphere, centered at the residue’s center of mass, and counting the number of residues falling inside this sphere. •Usually done with different cutoff radii. From Sequence to Structure Protein Folding: The Levinthal paradox: [Levinthal C.; J. Chym. Phys. (1968)] Assume a protein is comprised of 100 AAs. Assume each AA’s backbone can take up 10 different conformations, defined by ф and ψ values. Altogether we get: 10100 conformations. If each conformation were sampled in the shortest possible time (time of a molecular vibration ~ 10-13 s) it would take an astronomical amount of time (~1077 years) to sample all possible conformations, in order to find the Native State. NPC even in the 2D case Luckily, nature works out with these sorts of numbers and the correct conformation of a protein is reached within seconds. From Sequence to Structure Folding Models: The Backbone-Centric view: •Sequence order dependent interactions (фψ - propensities and Hbonds), produce local secondary structure elements (SSEs). •Local SSEs later overgo longerrange interactions to form supersecondary structures. •Supersecondary structures of ever-increasing complexity thus grow, ultimately into the native conformation. From Sequence to Structure Folding Models: The Sidechain-Centric view: •Hydrophobic sidechain interactions are the strongest for AAs in a water solution. •A few key hydrophobic residues are responsible for a “hydrophobic collapse” to the “molten globule” state. Molten globule states •The “molten globule” might not include SSEs, yet about this structure the remainder of the polypeptide chain condenses. •The conformation space is viewed as “funnel shaped”. From Sequence to Structure Folding Models: The Sidechain-Centric view - Larger proteins: •Intermediate states exist, which are highly populated. •These states may assist in finding the Native Structure or may serve as traps that inhibit the folding process. •Structurally aligning intermediate states against the SCOP found the corresponding Native Structures to have the highest scores. •But, many features were missing: • Well defined SSEs. • A well formed hydrophobic core. • High RMSDs (7-10Å). [Dobson C. M.; TRENDS in Biochemical Sciences; Jan 2005] From Sequence to Structure Folding Models: Post-translational Vs. Co-translational Anfinsen’s experiments: •Exposure of a purified RNase-A enzyme to a concentrated urea solution in the presence of a reducing agent denaturizes the folded conformation resulting in a complete loss of catalytic activity. •Removal of the urea and reducing agent causes the enzyme to accurately refold to its native structure and restore its catalytic activity. [Anfinsen C. et al.; PNAS (1961)] •Denaturation-Renaturation experiments are biased. •An AA is added to the polypeptide chain in: 10-2 s. •The rate at which an SSE is formed is: 10-7 – 10-4 s. Determining the Structure Crystallization: • Assembling a solution of protein molecules into a periodic lattice. X-Ray Diffraction: • • • The crystal is bombarded with X-ray beams. The collision of the beams with the electrons creates a diffraction pattern. The diffraction pattern is transformed into an electron density map of the protein from which the 3D locations of the atoms can be deduced. F F Determining the Structure Nucleotide Magnetic Resonance: • • • • • • A solution of the protein is placed in a magnetic field. spins align parallel or anti-parallel to the field. RF pulses of electromagnetic energy shifts spins from their alignment. Upon radiation termination spins re-align while emitting the energy they absorbed. The emission spectrum contains information about the identity of the nuclei and their immediate environment. The result is an ensemble of models rather than a single structure. Structure Similarity Protein Families: • Structures seem to be preserved much more than sequences, which is easily explainable due to neutral mutations. 1BRU: Pancreatic Elastase (Sus scorfa). Global Alignment: 39% identity 1CHG: Chymotrysinogen (Bos taurus). Rigid Cα Alignment: RMSD 1.26Å 1CHG 1BRU 1CHG 1BRU Structure Similarity Protein Families: • • • Structures seems to be preserved much more than sequences, which is easily explainable due to neutral mutations. Structural Biologists claim that there are a limited number of ways in which protein domains fold. There may be as few as ~2000 different folds (differing by their backbone topology). Nearly a 1000 different folds have already been resolved. http://scop.mrc-lmb.cam.ac.uk/scop/ Structure Prediction Homology (Comparative) Modeling: Guideline: At least 30% sequence identity is needed between probe and template. 1. Template Assignment: creating a robust probe- 2. Model Construction: 3. template alignment (PWA/MSA). a. Generation of coordinates for conserved segments: b. Generation of coordinates for variable segments: c. Generation of coordinates for sidechain atoms: superimposing/averaging/restrain based. DB scanning/Ab Initio/restrain based. superimposing/rotamer libraries/restrain based. Model Evaluation: a. b. Assessment of to the ability to functionally identify the active site of the model. Assessment of physico-chemical or structural environment based on statistical analyses of DBs for characteristics such as: Intramolecular packing. Bond geometry. Solvent accessibility. bFGF [Peitsch et al. (1999)] Structure Prediction Threading (Sequence-Structure Alignment): Identifying evolutionary unrelated proteins that have converged to similar folds. • Scoring Scheme: describes the propensity of each AA for its structural/physicochemical environment: SS type, solvent accessibility, coordination number, etc… • Profile construction: encoding the template’s AAs structural features to a 1D profile and predicting such a profile for the probe. • Threading Algorithm: Aligning the 1D profiles of the template and the probe using DP and the defined scoring scheme. template probe [Bryant, Lawrence; Proteins (1993)] But: No adjustments to the template profile can be made thus substantial rearrangements are ignored Structure Prediction Ab Initio Techniques: Simulating the folding process Simplifying the energy landscape: • Reducing the number of degrees of freedom: • • • Sampling the conformation space: • • • • Representing a group of atoms by a single atom. Reducing the number of atom interactions. Monte Carlo sampling. Genetic Algorithm. Simulated Annealing. Hierarchical folding simulation. Blind Prediction Critical Assessment of Protein Structure Prediction – CASP Goal: “ to obtain an in-depth and objective assessment of our current abilities and inabilities in the area of protein structure prediction”. Groups use their tools to model proteins with pre-published structures. The predictions are thus evaluated against the subsequently determined structures. CASP6 (2004) shows limited improvements compared to CASP5 (2003).