Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Application of Improved Grammatical Evolution to
Santa Fe Trail Problems
Takuya Kuroda, Hiroto Iwasawa, Tewodros Awgichew, and Eisuke Kita
Graduate School of Information Science, Nagoya University, Nagoya 464-8601, Japan
Abstract. Grammatical Evolution (GE) is one of the evolutionary algorithms,
which can deal with the rules with tree structure by one-dimensional chromosome. Syntax rules are defined in Backus Naur Form (BNF) to translate binary
number (genotype) to function or program (phenotype). In this study, three algorithms are introduced for improving the convergence speed. First, an original
GE are compared with Genetic Programming (GP) in the function identification
problem. Next, the improved GE algorithms are applied to Santa Fe Trail problem. The results show that the improved schemes are effective for improving the
convergence speed.
Keywords: Grammatical Evolution, Backus Naur Form, Santa Fe Trail.
1 Introduction
Evolutionary algorithms are techniques implementing mechanisms inspired by biological evolution such as reproduction, mutation, recombination, natural selection and survival of the fittest. They are classified into Genetic Algorithms (GA)[1,2], Evolutionary
Programming (EP)[3], Genetic Programming (GP)[4,5] and so on.
In the GA, a population of chromosomes of candidate solutions to an optimization
problem evolves toward better solutions by using the selection, crossover and mutation
operations. Genetic Programming (GP) is an evolutionary algorithm-based methodology to find computer programs that perform a user-defined task. GP evolves computer
programs represented in memory as tree structures. Simulated Annealing Programming
(SAP) is also designed to find the programs, which comes from Simulated Annealing
(SA).
Banzhaf has presented the GP in which programs are represented in one-dimensional
chromosome[6]. A one-dimensional chromosome is translated to program according to the template defined in advance. In this case, the programs are often invalid
in the syntax. On the contrary, Whigham has presented grammatically-based genetic
programming[7]. Like as Banzhaf, the template is used for translating chromosome to
program. Since the chromosome is defined in tree structure, like GP, many complicated
genetic operators are necessary. Ryan et. al. have presented Grammatical Evolution
(GE)[8,9,10], in which the difficulty of the Banzhaf algorithm is improved by the syntax definition of grammatically-based genetic programming.
The aim of this study is to introduce three schemes for improving the convergence
performance of GE. First, the original GE and GP are compared in function identification problem. After that, three schemes are discussed in the Santa Fe trail problem,
F. Peper et al. (Eds.): IWNC 2009, PICT 2, pp. 218–225, 2010.
c Springer 2010
Application of Improved Grammatical Evolution to Santa Fe Trail Problems
219
whose object is to find programs to control the artificial ants collecting foods in the
region.
The remaining of this paper is as follows. The algorithm of the original GE is shown
in section 2 and the results in the function identification problem are discussed in section 3. Three schemes for improving original algorithm are explained in section 4. The
schemes are compared with the original GE in Santa Fe Trail Problem in section 5. The
results are summarized again in section 6.
2 Original Grammatical Evolution
The algorithm of original Grammatical Evolution (GE) is as follows.
1. Define a syntax in BNF, which translates genotype (binary number) to phenotype
(function or program).
2. Generate randomly initial individuals to construct an initial population.
3. Translate chromosome to function according to the BNF syntax.
4. Estimate fitness of chromosome.
5. Use genetic operators to generate new individuals.
6. Terminate the process if the criterion is satisfied.
7. Go to step 3.
The translation from genotype to phenotype is as follows.
1. Translate a binary number to a decimal number for every n-bits.
2. Define a leftmost decimal as β, a leftmost nonterminal symbol as α, and the number
of candidate rules for α as nα .
3. Calculate the remainder γ = β%nα .
4. Select γ-th rule of the candidate rules for α.
5. If nonterminal symbols exist, go to step 2.
In the genetic programming (GP), the programs often grow rapidly in size over time
(bloat). For overcoming the difficulty, the maximum size of the programs is restricted
in advance. The similar idea is applied to the GE. The maximum size of the programs
is restricted to Lmax .
3 Function Identification Problem
3.1 Problem Settings
The function identification problem is defined as
Find a function f¯
when discrete data {(x1 , y1 ), (x2 , y2 ), · · · , (xn , yn )} is given.
where the parameter n denotes the total number of the discrete data. When an exact
function f is given, the discrete data are referred to as yi = f (xi ).
We will consider that the exact function f is given as
f (x) = x4 + x3 + x2 + x.
(1)
The discrete data are generated by estimating equation (1) at x = −1, −0.9, −0.8,
· · · , 0.9, 1.
220
T. Kuroda et al.
Table 1. BNF Syntax for Function Identification Problem
(A) <expr> ::=
|
(B)
<op> ::=
|
|
|
(C)
<x> ::=
<expr><expr><op>
<x>
+
*
/
x
(A0)
(A1)
(B0)
(B1)
(B2)
(B3)
(C0)
3.2 Syntax and Parameters
The fitness is defined as the mean least square error of f and f¯ as
21
1 [f (xi ) − f¯(xi )]2 .
f itness = 21 i=1
(2)
where f and f¯ denote the exact function and the function predicted in GE, respectively.
A GE syntax in BNF is shown in Table 1. The start symbol is <expr>.
The parameters for GE and GP are shown in Table 2 and 3, respectively. Tournament
selection, one-elitist strategy and one-point crossover are employed for both GE and
GP. The mutation operator is applied for GE alone.
The fitness values are estimated as the value averaged over 50 runs.
3.3 Result
The convergence history of the best fitness value is shown in Fig.1. The abscissa and the
ordinate denote the number of generation and fitness value, respectively. The
Table 2. GE Parameters
Generation
1000
Population size
100
Chromosome
100
Tournament size
5
Crossover rate
0.5
Mutation rate
0.1
Translation bit-size
4bit
Maximum size Lmax = 100
Table 3. GP Parameters
Generation 1000
Population size 100
Crossover rate 0.9
Application of Improved Grammatical Evolution to Santa Fe Trail Problems
221
Fig. 1. Result of Function Identification Problem
convergence speed of GE is slower than that of GP. Finally, GE can find a better solution than GP.
4 Improved Schemes of Grammatical Evolution
4.1 Difficulties of Original GE
Rule Selection. We will consider a leftmost decimal as β, a leftmost nonterminal symbol as α, and the number of candidate rules for α as nα . Since a rule is selected by the
remainder γ = β%nα , the rule selection is very sensitive to β. Even when the value of
β alters by only one, the selected rule is changed. This may disturb the development of
the better scheme in the population. The following scheme 1 is designed for overcoming
this difficulty.
Selection Probability of Rules. The original GE selects rules according to the remainder and therefore, the selection probability for all candidate rules is identical. For
example, in Table 1, the rule <expr> is translated to <expr><expr><op> (A0) or
<x> (A1). The selection probability of the rule (A0) is identical to that of the rule (A1).
However, biased selection probability may be better in some problems for improving
the convergence speed.
The rules are classified into the recursive (non-terminal) and terminal rules. For example, in Table 1, the rule (A) is recursive rule and the others are terminal rules. The
iterative use of recursive rule makes the phenotype (function or program) longer and
more complicated. On the other hand, the terminal rule terminates the development of
the phenotype. Since the roles of the recursive and the terminal rules are different, it is
appropriate that the different selection probability is taken for each rule. The following
scheme 2 and 3 are designed to control the selection probability of the recursive and the
terminal rules, respectively.
222
T. Kuroda et al.
4.2 Improvement of GE
Scheme 1. In the original GE, the rules are selected by the remainder. The scheme
1 adopts the special roulette selection, instead of the remainder selection. The roulette
selection is popular selection algorithm in GA. In the scheme 1, the roulette selection
probability for all candidates rules is identical. The use of the roulette selection can
encourage the development of the better schema.
We will consider a leftmost decimal as β, a leftmost nonterminal symbol as α, and
the number of candidate rules for α as nα . The algorithm is as follows.
1. Calculate the parameter sα = β/nα .
2. Generate a uniform random number p (0 < p ≤ β).
3. If (k−1)sα < p ≤ ksα , select k-th rule from the candidate rules for α (1 ≤ k ≤ n).
Scheme 2. The selection probability of the recursive rule is controlled according to
the length of the generated program. The maximum length of the programs is specified
in advance. If the length of the programs is shorter than the maximum length Lmax , the
selection probability is increased. If not so, the probability is decreased.
The selection probability of the recursive rule i is calculated as
Pir = 1 −
L
Lmax
(3)
where L and Lmax denote the length and the maximum length of the programs.
Scheme 3. Occurrence numbers of the terminal rules in all individuals are estimated.
The selection probability PiN of the terminal rule i is calculated as
Ni
PiN = N N
j=1
Nj
(4)
where Ni and N N denote the occurrence number of the terminal rule i and the total
occurrence number of all terminal rules, respectively.
5 Santa Fe Trail Problem
5.1 Problem Setting
The object of Santa Fe trail problem is to automatically find the program to control
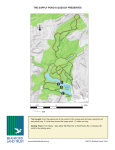
artificial ants which efficiently collect foods in the region[4,5]. In this study, the region
is 32 × 32-grid region in which there are 89 foods (Fig.2). The ant behavior is defined
as follows.
1.
2.
3.
4.
5.
6.
Ants start from upper-left cell.
Ants move one cell, turn to left or turn to right at every time-steps.
Ants move in vertical and horizontal directions alone.
Ants cannot get across the walls.
Ants have sensor to find food.
Ants have life energy which is expended one unit every time step.
Application of Improved Grammatical Evolution to Santa Fe Trail Problems
223
Fig. 2. Santa Fe Trail Problem
Table 4. BNF Syntax for Santa Fe Trail Problem
(A)
<code> ::=
|
(B)
<expr> ::=
|
(C) <if_statement> ::=
(D)
<op> ::=
|
|
<code><expr>
(A0)
<expr>
(A1)
<if_statement>
(B0)
<op>
(B1)
if_food_ahead{<op>}else{<op>} (C0)
right
(D0)
left
(D1)
forward
(D2)
5.2 Syntax and Parameters
A syntax in BNF is shown in Table 4. The expression “right”, “left” and
“forward” denote facing to the right, facing to the left and moving forward, respectively. The expression “if_food_ahead{<op1>}else{<op2>}” denotes that the
first argument <op1> is performed if a food exists in the front cell of the ant and the
second argument <op2> is performed if a food does not exist. The start symbol is
<code>.
The fitness is defined as follows.
F itness = 89 − Fo
(5)
where the parameter Fo is the total number of foods which the ant collects.
The simulation algorithm is as follows.
1.
2.
3.
4.
5.
Specify an initial ant energy as 400 and the number of collected foods as 0; Fo = 0.
Move the ant and decrement the ant energy.
If a food exists, take the food and Fo = Fo + 1.
If the energy is equal to 0, estimate the fitness from equation (5).
Go to step 2.
224
T. Kuroda et al.
The parameters are specified to same values as the previous example (Table 2). Tournament selection, one-elitist strategy and one-point crossover are employed. The fitness
values are the value averaged over 50 runs.
5.3 Result
The history of the best individual fitness is shown in Fig.3. The abscissa and the ordinate
denote the generation and the average fitness, respectively.
The comparison of the original GE and scheme 1 shows that the use of scheme 1
improves the convergence speed. However, the use of the scheme 1+2 becomes the
convergence speed worse. The scheme 3 does not affect the performance of the algorithm. Therefore, we can conclude that only the scheme 1 is effective for improving the
search performance of this problem.
Fig. 3. Convergence History of Best Individual Fitness
6 Conclusion
This paper described some improvement of the grammatical evolution. First we explained the grammatical evolution simply and introduced three improvement schemes;
scheme 1, scheme 2 and scheme 3.
In the first example, the original GE and the original GP were compared in the function identification problem. The results have shown that the convergence speed of GE
was slower than that of GP and that GE could find better solution than the GP.
In the second example, three schemes were compared in Santa Fe trail problem. The
results showed that the scheme 1 was very effective. The scheme 1 uses roulette selection, instead of remainder selection, in order to encourage the development of the better
scheme in the chromosome. The above result indicates the effectiveness of roulette selection for the problem to be solved. On the other hand, the scheme 2 and 3 were not
effective. The scheme 2 and 3 give the biased selection probability for the candidates of
recursive and terminal rules, respectively. In the BNF syntax of Santa Fe trail problem,
there are only two or three candidates for each rule. Therefore, the biased probability
may be similar to the uniform probability. However, we have to discuss their effectiveness in more detailed.
Application of Improved Grammatical Evolution to Santa Fe Trail Problems
225
References
1. Holland, J.H.: Adaptation in Natural and Artificial Systems, 1st edn. The University of
Michigan Press, Ann Arbor (1975)
2. Goldberg, D.E.: Genetic Algorithms in Search, Optimization and Machine Learning, 1st edn.
Addison Wesley, Reading (1989)
3. Fogel, D.B., Atmar, J.W.: Proc. 1st annual Conference on Evolutionary Programming. Evolutionary Programming Society (1992)
4. Koza, J.R. (ed.): Genwetic Programming II. The MIT Press, Cambridge (1994)
5. Koza, J.R., Bennett III, F.H., Andre, D., Keane, M.A. (eds.): Genewtic Programming III.
Morgan Kaufmann Pub., San Francisco (1999)
6. Banzhaf, W.: Genotype-phenotype-mapping and neutral variation – A case study in genetic programming. In: Davidor, Y., Schwefel, H.P., Männer, R. (eds.) PPSN 1994. LNCS,
vol. 866, pp. 322–332. Springer, Heidelberg (1994)
7. Whigham, P.A.: Grammatically-based genetic programming. In: Rosca, J.P. (ed.) Proceedings of the Workshop on Genetic Programming: From Theory to Real-World Applications,
pp. 33–41 (1995)
8. Ryan, C., Collins, J.J., O’Neill, M.: Grammatical evolution: Evolving programs for an arbiturary language. In: Banzhaf, W., Poli, R., Schoenauer, M., Fogarty, T.C. (eds.) EuroGP
1998. LNCS, vol. 1391, pp. 83–95. Springer, Heidelberg (1998)
9. Ryan, C., O’Neill, M.: Grammatical Evolution: Evolutionary Automatic Programming in an
Arbitrary Language. Springer, Heidelberg (2003)
10. Brabazon, A., O’Neill, M.: Biologically Inspired Algorithms for Financial Modelling.
Springer, Heidelberg (2006)