Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Join-pattern wikipedia , lookup
Supercomputer wikipedia , lookup
Algorithmic skeleton wikipedia , lookup
Parallel computing wikipedia , lookup
Stream processing wikipedia , lookup
Application Interface Specification wikipedia , lookup
Supercomputer architecture wikipedia , lookup
Multi-core processor wikipedia , lookup
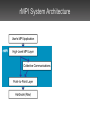
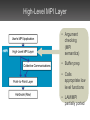
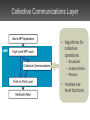
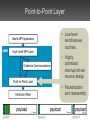
Message Passing On TightlyInterconnected Multi-Core Processors James Psota and Anant Agarwal MIT CSAIL Technology Scaling Enables MultiCores cluster multi-core Multi-cores offer a novel environment for parallel computing Traditional Communication On Multi-Processors Interconnects Shared Memory – Ethernet TCP/IP – Myrinet – Scalable Coherent Interconnect (SCI) – Shared caches or memory – Remote DMA (RDMA) Beowulf Cluster AMD Dual-Core Opteron On-Chip Networks Enable Fast Communication • Some multi-cores offer… – tightly integrated on-chip networks – direct access to hardware resources (no OS layers) – fast interrupts MIT Raw Processor used for experimentation and validation Parallel Programming is Hard • Must orchestrate of computation and communication • Extra resources present both opportunity and challenge • Trivial to deadlock • Constraints on message sizes • No operating system support rMPI’s Approach Goals – robust, deadlock-free, scalable programming interface – easy to program through high-level routines Challenge – exploit hardware resources for efficient communication – don’t sacrifice performance Outline • • • • • Introduction Background Design Results Related Work The Raw Multi-Core Processor • 16 identical tiles – processing core – network routers • 4 register-mapped on-chip networks • Direct access to hardware resources • Hardware fabricated in ASIC process Raw Processor Raw’s General Dynamic Network • Handles run-time events – interrupts, dynamic messages • Network guarantees atomic, in-order messages • Dimension-ordered wormhole routed • Maximum message length: 31 words • Blocking sends/receives • Minimal network buffering MPI: Portable Message Passing API • Gives programmers high-level abstractions for parallel programming – send/receive, scatter/gather, reductions, etc. • MPI is a standard, not an implementation – many implementations for many HW platforms – over 200 API functions • MPI applications portable across MPIcompliant systems • Can impose high overhead MPI Semantics: Cooperative Communication process 0 send(dest=1, tag=17) • Data exchanged cooperatively via explicit send and receive • Receiving process’s memory only modified with its explicit participation • Combines communication and synchronization send(dest=1, tag=42) private address tag=17 space tag=42 process 1 recv(src=0, tag=42) recv(src=0, tag=17) temp interrupt communication channel private address space Outline • • • • • Introduction Background Design Results Related Work rMPI System Architecture High-Level MPI Layer • Argument checking (MPI semantics) • Buffer prep • Calls appropriate low level functions • LAM/MPI partially ported Collective Communications Layer • Algorithms for collective operations – Broadcast – Scatter/Gather – Reduce • Invokes low level functions Point-to-Point Layer • Low-level send/receive routines • Highly optimized interrupt-driven receive design • Packetization and reassembly Outline • • • • • Introduction Background Design Results Related Work rMPI Evaluation • How much overhead does high-level interface impose? – compare against hand-coded GDN • Does it scale? – with problem size and number of processors? – compare against hand-coded GDN – compare against commercial MPI implementation on cluster End-to-End Latency Overhead vs. Hand-Coded (1) • Experiment measures latency for: – sender: load message from memory – sender: break up and send message – receiver: receive message – receiver: store message to memory End-to-End Latency Overhead vs. HandCoded (2) 1 word: 481% 1000 words: 33% packet management complexity overflows cache Performance Scaling: Jacobi 16x16 input matrix 2048 x 2048 input matrix Performance Scaling: Jacobi, 16 processors sequential version cache capacity overflow Overhead: Jacobi, rMPI vs. HandCoded many small messages memory access synchronization 16 tiles: 5% overhead Matrix Multiplication: rMPI vs. LAM/MPI many smaller messages; smaller message length has less effect on LAM Trapezoidal Integration: rMPI vs. LAM/MPI Pi Estimation: rMPI vs. LAM/MPI Related Work • Low-latency communication networks – iWarp, Alewife, INMOS • Multi-core processors – VIRAM, Wavescalar, TRIPS, POWER 4, Pentium D • Alternatives to programming Raw – scalar operand network, CFlow, rawcc • MPI implementations – OpenMPI, LAM/MPI, MPICH Summary • rMPI provides easy yet powerful programming model for multi-cores • Scales better than commercial MPI implementation • Low overhead over hand-coded applications Thanks! For more information, see Master’s Thesis: http://cag.lcs.mit.edu/~jim/publications/ms.pdf rMPI messages broken into packets rMPI sender process 1 • GDN messages have a max length of 31 words • Receiver buffers 21 and demultiplexes • rMPI packet format for interrupt 65 [payload] word MPI message packets from rMPI different sources receiver process • Messages received upon interrupt, and buffered until user-level receive 23 1 rMPI sender process 2 rMPI: enabling MPI programs on Raw rMPI… • is compatible with current MPI software • gives programmers already familiar with MPI an easy interface to program Raw • gives programmers fine-grain control over their programs when trusting automatic parallelization tools are not adequate • gives users a robust, deadlock-free, and highperformance programming model with which to program Raw ► easily write programs on Raw without overly sacrificing performance Packet boundary bookkeeping • Receiver must handle packet interleaving across multiple interrupt handler invocations Receive-side packet management • Global data structures accessed by interrupt handler and MPI Receive threads • Data structure design minimizes pointer chasing for fast lookups • No memcpy for receivebefore-send case User-thread CFG for receiving Interrupt handler CFG • logic supports MPI semantics and packet construction Future work: improving performance • Comparison of rMPI to standard cluster running off-the-shelf MPI library • Improve system performance – further minimize MPI overhead – spatially-aware collective communication algorithms – further Raw-specific optimizations • Investigate new APIs better suited for TPAs Future work: HW extensions • Simple hardware tweaks may significantly improve performance – larger input/output FIFOs – simple switch logic/demultiplexing to handle packetization could drastically simplify software logic – larger header words (64 bit?) would allow for much larger (atomic) packets • (also, current header only scales to 32 x 32 tile fabrics) Conclusions • MPI standard was designed for “standard” parallel machines, not for tiled architectures – MPI may no longer make sense for tiled designs • Simple hardware could significantly reduce packet management overhead increase rMPI performance