Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Power over Ethernet wikipedia , lookup
Audio power wikipedia , lookup
Electrical substation wikipedia , lookup
Utility frequency wikipedia , lookup
Electrification wikipedia , lookup
Variable-frequency drive wikipedia , lookup
Buck converter wikipedia , lookup
Voltage optimisation wikipedia , lookup
Electric power system wikipedia , lookup
Opto-isolator wikipedia , lookup
History of electric power transmission wikipedia , lookup
Television standards conversion wikipedia , lookup
Power electronics wikipedia , lookup
Immunity-aware programming wikipedia , lookup
Time-to-digital converter wikipedia , lookup
Distribution management system wikipedia , lookup
Power engineering wikipedia , lookup
Magnetic-core memory wikipedia , lookup
Mains electricity wikipedia , lookup
Switched-mode power supply wikipedia , lookup
Adaptive System on a Chip (ASOC):
A Backbone for Power-Aware
Signal Processing Cores
Andrew Laffely, Jian Liang, Russ Tessier and Wayne Burleson
Electrical and Computer Engineering
University of Massachusetts Amherst
{burleson}@ecs.umass.edu
This material is based upon work supported by the National Science Foundation under Grant No. 9988238
and SRC Tasks 766 and 1075
Burleson, UMASS
1
Challenges in Media Processing
•
Increasingly complex, heterogeneous algorithms
•
•
•
•
Large data-sets, usually streaming
•
•
Variable run-times (e.g. data-dependent iterations)
Variable quality
Variable power consumption
Memory size, ports and latency issues
Advancing semiconductor technology (Moore’s Law)
•
•
•
•
Interconnect (on-chip and I/O)
Clocking
Power (consumption and distribution)
Design and Verification
Burleson/UMASS
2
aSoC: adaptive System on a Chip
•
Motion Estimation
and Compensation
DCT
Control Encrypt
VLE
FIR
Tiled SoC
architecture
Viterbi Memory
Burleson/UMASS
3
aSoC: adaptive System on a Chip
•
Motion Estimation
and Compensation
DCT
•
Tiled SoC architecture
Supports the use of
independently developed
heterogeneous cores
Pick and place cores which
best perform the given
application
• Increase performance
• Save power
• Cores may be any number
of tiles in size
•
Control Encrypt
FIR
VLE
Viterbi Memory
Burleson/UMASS
4
aSoC: adaptive System on a Chip
•
Motion Estimation
and Compensation
DCT
•
•
Control Encrypt
FIR
VLE
Tiled SoC architecture
Supports the use of
independently developed
heterogeneous cores
Connected with an
interconnect mesh
•
Restricted to near neighbor
communications
• Creates pipeline
• Decreases cycle time
Viterbi Memory
Burleson/UMASS
5
aSoC: adaptive System on a Chip
•
Motion Estimation
and Compensation
DCT
•
•
•
Control Encrypt
VLE
Tiled SoC architecture
Supports the use of
independently developed
heterogeneous cores
Connected with an optimized
fixed interconnect mesh
Using a communication interface
(CI) to manage data
•
•
FIR
Viterbi Memory
•
Burleson/UMASS
Network port (Coreport) for each
core, I/O queues,handshake
Each CI uses a memory and FSM
to repetitively process a
predefined (static) schedule of
communications
High-speed 5x5 bidirectional
crossbar
6
Communication Interface
Core
•
Core-ports
North
North
South
East
South
•
East
•
West
West
Inputs
Local Config.
Crossbar
Decoder
North to South & East
•
Outputs
Controller
Custom design to
maximize speed
and reduce power
Local
Frequency
& Voltage
•
•
Core-ports
Crossbar
Controller
Instruction
memory
Local frequency
and voltage supply
PC
Instruction Memory
Burleson/UMASS
7
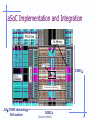
aSoC Implementation and Integration
2500 l
.18m TSMC technology
Full custom
3000 l
Burleson/UMASS
8
Research Thrusts
•
•
aSoC Infrastructure1,3
• Communication Interface
• Interconnect3
• Power Distribution
• Clock System
• Power Management
Design Technology
• Compiler1,3 (Partitioner,
Mapper, Placer, Scheduler)
• Simulator1
•
Cores
•
•
•
•
•
•
•
•
Motion estimation2,3
Discrete Cosine Transform2,3
AES Cryptography3
Huffman Coding
Adaptive Viterbi2,3
3D Graphics1,2,3
Smart Card2,3
MP3
ARM
DSP
• Cache2,3
• FPGA
• MAC
•
•
Burleson/UMASS
1
2
3
PhD Dissertation
Masters Thesis
Publications
9
Voltage Scaling Approach
•
Core-ports
•
•
Single buffer for each
stream to cross
clock/voltage barrier
between core and
interface
Reading/Writing
success rates indicate
core utilization
Input blocked: Core
too slow
• Output blocked:
Core too fast
•
•
Controller
•
Interprets core-port
success rates to adjust
local clock and voltage
Core
Buffer
Processing
Pipeline
Local Local
Vdd Clock
Input
Core-port
Output
Core-port
Clock
Blocked
Blocked
and
Supply
Controller
Interconnect
Burleson/UMASS
10
Vdd Selection Criteria
Normalized Core Critical Path Delay vs. Vdd
12
Normalized
Delay 10
1/8 Speed 8
6
1/4 Speed 4
1/2 Speed
•
•
•
As Vdd decreases delay increases
exponentially
Use curve to match available clock
frequencies to voltages
The voltage and frequency change
reduces power by 79%, 96%, and
98.7%
•
P = aC(Vdd)2f
2
Max Speed
0
0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
0.73 1.16
2
Voltage
Burleson/UMASS
11
Architecture Evaluation
(Motion Estimation)
•
Array-based
architecture
•
•
Memory
Pipelined ME
FIFOs
Parameterized
search window
size
•
•
•
Address
Generation
Unit
Full search
Choose 16x16 or
8x8 windows
Reduce power
Burleson/UMASS
Processing
Element
Array
12
Power Aware Core
•
Custom motion estimation core
•
Choose search method
•
Full search
•
•
Spiral search
•
•
960-600mW (bit width and pel sub-sampling)
76mW
Three step search
•
25mW
Data taken with SynopsysTM Power Compiler at the RTL level
Burleson/UMASS
13
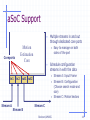
aSoC Support
•
Coreports
in1
Stream A
Motion
Estimation
Core
•
•
Easy to manage on both
sides of the port
Schedule configuration
streams in with the data
Stream A: Input Frame
• Stream B: Configuration
(Choose search mode and
size)
• Stream C: Motion Vectors
•
in2 out1 out2
Stream B
Multiple streams in and out
through dedicated core ports
Stream C
Burleson/UMASS
14
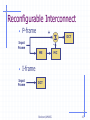
Reconfigurable Interconnect
•
P-frame
+
Input
Frame
DCT
ME
•
S
MC
I-frame
Input
Frame
DCT
Burleson/UMASS
15
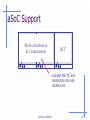
aSoC Support
Motion Estimation
& Compensation
DCT
•
Burleson/UMASS
Lumped ME, MC and
Summation into one
double core
16
aSoC Support: P-Frame
Motion Estimation
& Compensation
Input
Frame
(Stream A)
DCT
Difference
Frame
(Stream B)
Burleson/UMASS
17
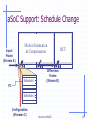
aSoC Support: Schedule Change
Input
Frame
(Stream A)
Motion Estimation
& Compensation
DCT
Difference
Frame
(Stream B)
Configuration Streams (C & D)
Burleson/UMASS
18
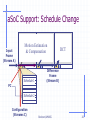
aSoC Support: Schedule Change
Input
Frame
(Stream A)
PC
Motion Estimation
& Compensation
Schedule 1
DCT
Difference
Frame
(Stream B)
Schedule 2
Configuration
(Streams C)
Burleson/UMASS
19
aSoC Support: Schedule Change
Input
Frame
(Stream A)
PC
Motion Estimation
& Compensation
Schedule 1
DCT
Difference
Frame
(Stream B)
Schedule 2
Configuration
(Streams C)
Burleson/UMASS
20
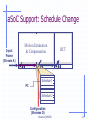
aSoC Support: Schedule Change
Input
Frame
(Stream A)
Motion Estimation
& Compensation
PC
DCT
Schedule 1
Schedule 2
Configuration
(Streams D)
Burleson/UMASS
21
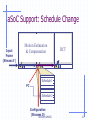
aSoC Support: Schedule Change
Input
Frame
(Stream A’)
Motion Estimation
& Compensation
PC
DCT
Schedule 1
Schedule 2
Configuration
(Streams D)
Burleson/UMASS
22
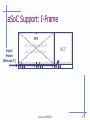
aSoC Support: I-Frame
OFF
Input
Frame
(Stream A’)
Motion Estimation
& Compensation
Burleson/UMASS
DCT
23
Operating Frequency?
•
Interconnect synchronized
•
•
Core frequencies depend on critical path
•
•
•
H-tree clock distribution
Tile provides clock reference
Coreport provides asynchronous boundary
Dynamic core configuration requires dynamic
clock configuration
•
•
aSoC clock reference provides multiples of
interconnect clock (… 4x, 2x, 1x, 0.5x, 0.25x, …)
Configured through the tile controller
Burleson/UMASS
24
Clock Distribution
Tile
• Tiled architecture extends life
of globally synchronous
systems
• Precise H-tree implementation
• Load is small and equal at each
branch
• Skew can be reduced by 70%
with advanced deskew circuits1
64 tile aSoC
70nm
100nm
130nm
180nm
Chip Area
(9.24mm)2
(13.3mm)2
(17.2mm)2
(23.8mm)2
Frequency
5 GHz
2 GHz
1 GHz
0.5 GHz
Power
126 mW
240 mW
445 mW
784 mW
Mean Skew
41 ps
50 ps
92 ps
70.6 ps
Percent Skew
21 %
10 %
9%
4%
S. Tan et al. “Clock Generation and Distribution for the First IA-64 Microprocessor”
IEEE JSSC, Nov. 2000
Burleson/UMASS
1
25
Mixed vs. Fixed Core Frequencies
Core: Mode
ME:
Full Search
ME:
Spiral
ME:
Three Step
Search
DCT
Interconnect
•
•
•
•
Optimal Independent
Frequencies
Frequency
Power
MHz
mW
105
973
Fixed Worst Case
105MHz
Power
mW
973
9.9
76
659
2.75
25
580
9.6
6.34
54
0.14
349
0.81
Cores not designed with clock gating
Core power from Synopsys RTL simulation
Interconnect from SPICE
Assumes 10 cycle schedule, 4 pixels/word
Burleson/UMASS
26
Current Density and Clocking
•
ME: Full
Search
Red: fixed worst case clocking
•
•
ME:
Spiral
Green: optimal independent
clocking
•
•
ME: Three
Step Search
Current
Short spikes of high current
Slow and low
Optimal clocking eliminates
current spikes (also improved
battery life)
DCT
Time
Process Start
Deadline
Burleson/UMASS
27
Power Distribution
• Heterogeneous power-aware
cores require multiple power
supply voltages
• Tile structure enables
uniform interwoven grid
• Larger grid for higher current
demands
Gnd
Vml
Vl
Vmh
• Reduced resistance
• Higher capacitance
Vh
64 tile aSoC
Vh
Vmh
Vml
Vl
Voltage
1.8V
1.16V
0.73V
0.6V
Current
per Core
110mA
25mA
13mA
7mA
Total Power
12.1 W
1.86 W
607 mW
269 mW
Burleson/UMASS
28
Advanced Signaling Techniques
(building on SRC-funded work)
Differential current sensing
Booster Insertion
Multi-level current signaling
Phase coding
Burleson/UMASS
29
Interconnect Characterization:
Comparing delay and power of signaling techniques for different
tile sizes at 250nm, 180nm, 130nm, 100n (available via web-based
tool Network on Chip Interconnect Calculator NOCIC)
Burleson/UMASS
30
Conclusions
•
Regular Tiled Architecture
•
•
•
•
Static scheduling
•
•
•
High-level global schedule of inter-core communication
Accomodates dynamic workloads with queues and local handshakes
Demonstration using Motion Estimation and DCT
•
•
Task-based parallelism using heterogeneous cores
Predictable interconnect
Regular core interface, Vdd and clock control, and configuration control
Variable search window and search algorithm provide power/quality tradeoff
Power savings using scalable approaches to dynamic clock and power
variation
•
•
Simple clock dividers leveraging existing clock distribution methods
Route multiple power supplies to allow rapid switching and avoid overhead of
on-chip power regulation
Burleson/UMASS
31
Ongoing Work
•
Satellite Set-top Box application
•
•
New and more complete wireless and multimedia systems
•
•
Jpeg2000, mpeg-4, 3d Graphics, …
ASOC parameter optimization
•
•
Developed at Hughes Networks using 7 distinct RISC cores. Compare ASOC with
in-house shared memory approach for interconnections.
Tile sizes, bus widths, clocks, VDDs
Coping with Core irregularity
•
Size, I/O positions, shapes, bus widths, communication interfaces
•
•
•
•
Interconnect circuit optimization (NoCIC)
Leakage Power issues
Reliability, Test, Fault-Tolerance and Security
Compilation: especially Partitioning, Mapping
•
Prototypes: .18u MOSIS of communication interface, ~25K transistors,
verification of interface logic and timing
ASOC in Education: Circuits, architecture and core design projects
•
Burleson/UMASS
32
Implications (perhaps controversial )
•
•
•
•
•
Multi-core architectures will be needed to maintain
Moore’s law (interconnect, memory, parallelism)
Task-based parallelism may be easier to program,
extract and implement than data parallelism (think
multi-core rather than instruction level parallelism)
Global coarse synchronization provides an approach to
hard-real time computing for dynamic workloads (ie
video coding).
Dynamic Power savings exploiting fine-grain workload
variations can be achieved through straightforward
clock and power scaling methods.
Interconnect standards will be specified by silicon
foundries similar to cell libraries and memories
Burleson/UMASS
33
Design Flow
http://vsp2.ecs.umass.edu/vspg/658/TA_Tools/design_flow.html
•
Architecture to Layout
Architecture: Block diagram of system and behavioral description
Logic: Gate level or schematic description
• Circuit: Transistor configurations and sizings
• Layout: Floorplanning, clock and power distribution
•
•
•
Tools
•
•
•
•
•
•
•
•
VerilogXL: behavioral representation
VTVT: standard cell library
Synopsys: standard cell gate level netlist generation
Silicon Ensemble: standard cell netlist to layout
Cadence LayoutPlus: schematic and layout design
NCSU CDK: design and extraction rules
Cadence Layout vs. Schematic: layout verification
HSPICE: circuit simulator
Burleson/UMASS
34