Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Spatial anti-aliasing wikipedia , lookup
Apple II graphics wikipedia , lookup
Solid modeling wikipedia , lookup
Tektronix 4010 wikipedia , lookup
Free and open-source graphics device driver wikipedia , lookup
InfiniteReality wikipedia , lookup
Framebuffer wikipedia , lookup
Waveform graphics wikipedia , lookup
Graphics processing unit wikipedia , lookup
Stream processing wikipedia , lookup
General-purpose computing on graphics processing units wikipedia , lookup
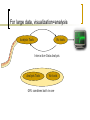
Data Visualization And Mining
Using The GPU
Sudipto Guha (Univ. of Pennsylvania)
Shankar Krishnan (AT&T Labs - Research)
Suresh Venkatasubramanian (AT&T Labs - Research)
What you will see in this tutorial…
The GPU is fast
The GPU is programmable
The GPU can be used for interactive visualization
How do we abstract the GPU ? What is an efficient GPU
program
How various data mining primitives are implemented
Using the GPU for non-standard data visualization
What you will NOT see…
Detailed programming tricks
Hacks to improve performance
Mechanics of GPU programming
BUT…
we will show you where to find all of this.
Plethora of resources now available on the web, as well as
code, toolkits, examples, and more…
Schedule
1st Hour
1:30pm –
1:50pm –
2nd Hour
2:30pm –
2:50pm –
3:20pm –
3rd Hour
3:30pm –
4:00pm –
4:20pm –
1:50pm: Introduction to GPUs (Shankar)
2:30pm: Examples of GPUs in Data Analysis (Shankar)
2:50pm: Stream Algorithms on the GPU (Sudipto)
3:20pm: Data mining primitives (Sudipto)
3:30pm: Questions and Short break
4:00pm: GPU Case Studies (Shankar)
4:20pm: High-level software support (Shankar)
4:30pm: Wrap-up and Questions
Animusic Demo (courtesy ATI)
But I don’t do graphics ! Why
should I care about the GPU ?
Two Converging Trends in
Computing …
The accelerated development of graphics cards
developing faster than CPUs
GPUs are cheap and ubiquitous
Increasing need for streaming computations
original motivation from dealing with large data sets
also interesting for multimedia applications, image
processing, visualization etc.
What is a Stream?
An ordered list of data items
Each data item has the same type
like a tuple or record
Length of stream is potentially very large
Examples
data records in database applications
vertex information in computer graphics
points, lines etc. in computational geometry
Streaming Model
Input presented as a sequence
Algorithm works in passes
allowed one sequential scan over input
not permitted to move backwards mid-scan
Workspace
typically o(n)
arbitrary computation allowed
Algorithm efficiency
size of workspace and computation time
Streaming: Data driven to
Performance driven
Primary motivation is computing over transient data (data
driven)
data over a network, sensor data, router data etc.
Computing over large, disk-resident data which are expensive
to access (data and performance driven)
To improve algorithm performance
How does streaming help performance?
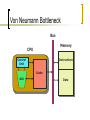
Von Neumann Bottleneck
Bus
Memory
CPU
Control
Unit
Instructions
Cache
ALU
Data
Von Neumann Bottleneck
Memory bottleneck
CPU processing faster than memory bandwidth
discrepancy getting worse
large caches and sophisticated prefetching strategies
alleviate bottleneck to some extent
caches occupy large portions of real estate in modern ship
design
Trends In Hardware
L3 Cache Array
Cache Real Estate
Die photograph
of the Intel/HP
IA-64 processor
(Itanium2 chip)
L3 Cache
Array
L3 Cache
Array
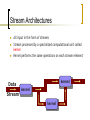
Stream Architectures
All input in the form of streams
Stream processed by a specialized computational unit called
kernel
Kernel performs the same operations on each stream element
Data
Stream
kernel
kernel
kernel
Stream Architectures
Items processed in a FIFO fashion
Reduced memory latency and cache requirements
Simplified control flow
Data-level parallelism
Greater computational efficiency
Examples
CHEOPS [Rixner et. al. ’98] and Imagine [Kapasi et. al.
’02]
high performance media applications
GPU: A Streaming Pipelined
Architecture
Inputs presented in streaming fashion
processed data items pass to next phase and does not
return
Data-level parallelism
Limited local storage
data items essentially carry their own state
Pipelining: each item processed identically
Not quite general purpose yet, but getting there
GPU Performance
From ‘Stream Programming Environments’ – Hanrahan, 2004.
The Graphics Pipeline
Modeling
Transformations
Illumination
(Shading)
Viewing Transformation
Input:
Geometric model:
Description of all object, surface and light source
geometry and transformations
Lighting model:
Computational description of object and light
properties, interaction (reflection, scattering etc.)
Synthetic viewpoint (or Camera location):
Eye position and viewing frustum
Clipping
Raster viewport:
Pixel grid on to which image is mapped
Projection
(to Screen Space)
Scan Conversion
(Rasterization)
Output:
Visibility / Display
Colors/Intensities suitable for display
(For example, 24-bit RGB value at each pixel)
The Graphics Pipeline
Modeling
Transformations
Illumination
(Shading)
Viewing Transformation
Clipping
Primitives are processed in a series of
stages
Each stage forwards its result on to the
next stage
The pipeline can be implemented in
different ways
Optimizations & additional programmability
are available at some stages
Projection
(to Screen Space)
Scan Conversion
(Rasterization)
Visibility / Display
Slide Courtesy: Durand and Cutler
Modeling Transformations
Modeling
Transformations
Illumination
(Shading)
Viewing Transformation
3D models defined in their own
coordinate system (object space)
Modeling transforms orient the models
within a common coordinate frame
(world space)
Clipping
Projection
(to Screen Space)
Scan Conversion
(Rasterization)
Visibility / Display
Object space
World space
Slide Courtesy: Durand and Cutler
Illumination (Shading) (Lighting)
Modeling
Transformations
Illumination
(Shading)
Viewing Transformation
Vertices lit (shaded) according to material
properties, surface properties (normal) and
light sources
Local lighting model
(Diffuse, Ambient, Phong, etc.)
Clipping
Projection
(to Screen Space)
Scan Conversion
(Rasterization)
Visibility / Display
Slide Courtesy: Durand and Cutler
Viewing Transformation
Modeling
Transformations
Illumination
(Shading)
Maps world space to eye space
Viewing position is transformed to
origin & direction is oriented along
some axis (usually z)
Viewing Transformation
Eye space
Clipping
Projection
(to Screen Space)
Scan Conversion
(Rasterization)
Visibility / Display
World space
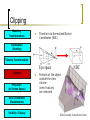
Clipping
Modeling
Transformations
Transform to Normalized Device
Coordinates (NDC)
Illumination
(Shading)
Viewing Transformation
Eye space
Clipping
Projection
(to Screen Space)
NDC
Portions of the object
outside the view
volume
(view frustum)
are removed
Scan Conversion
(Rasterization)
Visibility / Display
Slide Courtesy: Durand and Cutler
Projection
Modeling
Transformations
The objects are projected to the 2D
image place (screen space)
Illumination
(Shading)
Viewing Transformation
NDC
Screen Space
Clipping
Projection
(to Screen Space)
Scan Conversion
(Rasterization)
Visibility / Display
Slide Courtesy: Durand and Cutler
Scan Conversion (Rasterization)
Modeling
Transformations
Illumination
(Shading)
Rasterizes objects into pixels
Interpolate values as we go (color,
depth, etc.)
Viewing Transformation
Clipping
Projection
(to Screen Space)
Scan Conversion
(Rasterization)
Visibility / Display
Slide Courtesy: Durand and Cutler
Visibility / Display
Modeling
Transformations
Each pixel remembers the closest
object (depth buffer)
Almost every step in the graphics
pipeline involves a change of
coordinate system. Transformations
are central to understanding 3D
computer graphics.
Illumination
(Shading)
Viewing Transformation
Clipping
Projection
(to Screen Space)
Scan Conversion
(Rasterization)
Visibility / Display
Slide Courtesy: Durand and Cutler
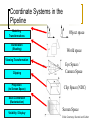
Coordinate Systems in the
Pipeline
Modeling
Transformations
Illumination
(Shading)
Object space
World space
Viewing Transformation
Clipping
Projection
(to Screen Space)
Eye Space /
Camera Space
Clip Space (NDC)
Scan Conversion
(Rasterization)
Screen Space
Visibility / Display
Slide Courtesy: Durand and Cutler
Programmable Graphics Pipeline
3D API:
OpenGL or
Direct3D
3D API
Commands
3D
Application
Or Game
Vertex
Index
Stream
Primitive
Assembly
Pre-transformed
Fragments
Pre-transformed
Vertices
Programmable
Vertex
Processor
Programmable
Fragment
Processor
Transformed
Fragments
GPU
Front End
Pixel
Pixel
Location
Updates
Stream
Rasterization
Frame
Raster
and
Buffer
Operations
Interpolation
Assembled
Primitives
Transformed
Vertices
GPU
Command &
Data Stream
CPU-GPU Boundary
Courtesy: Cg Book [Fernando and Kilgard]
Increase in Expressive Power
1996
simple if-then tests via depth and stencil testing.
1998
More complex arithmetic and lookup operations
2001
Limited programmability in pipeline via specialized
assembly constructs
2002
Full programmability, but only straight line programs
2004
True conditionals and loops
2006(?)
General purpose streaming processor ?
Recall
Hanrahan, 2004.
GPU = Fast co-processor ?
GPU speed increasing at cubed-Moore’s Law.
This is a consequence of the data-parallel streaming aspects of
the GPU.
GPUs are cheap ! Put enough together, and you can get a supercomputer.
So can we use the GPU for
general-purpose computing ?
NYT May 26, 2003: TECHNOLOGY; From PlayStation
to Supercomputer for $50,000:
National Center for Supercomputing Applications at
University of Illinois at Urbana-Champaign builds
supercomputer using 70 individual Sony Playstation 2
machines; project required no hardware engineering
other than mounting Playstations in a rack and
connecting them with high-speed network switch
In Summary
GPU is fast
The trends, compared to CPU, is already better
But is it being used in non-graphics applications?
Wealth of applications
Data Analysis
Motion Planning
Particle Systems
Voronoi Diagrams
Geometric Optimization
Physical Simulation
Linear Solvers
Force-field simulation
Molecular Dynamics Graph Drawing
Database queries
Sorting and Searching
Range queries
Audio, Video and Image processing
… and graphics too !!
Computation & Visualization
The success stories involving the GPU revolve around the
merger of computation and visualization
Linear system solvers used for real-time physical simulation
Voronoi diagrams allow us to perform shape analysis
n-body computations form the basis for graph drawing and
molecular modelling.
For large data, visualization=analysis
Analysis Tools
Viz tools
Interactive Data Analysis
Analysis Tools
Viz tools
GPU combines both in one
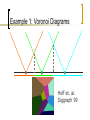
Example 1: Voronoi Diagrams
Hoff et. al.
Siggraph 99
Example 2: Change Detection
using Histograms
Other examples
Physical system simulation:
Fluid flow visualization for graphics and scientific
computing
One of the most well-studied and successful uses of the
GPU.
Image processing and analysis
A very hot area of research in the GPU world
Numerous packages (openvidia, apple dev kit) for
processing images on the GPU
Cameras mounted on robots with real-time scene
processing
Other examples
SCOUT: GPU-based system for expressing general data
visualization queries
provides a high level data processing language
Data processed thru ‘programs’; user can interact with
output data
SCOUT demonstrates
effectiveness of GPU for data visualization
need for general GPU primitives for processing data.
But the computation and visualization is decoupled.
Also are many more examples !!
Central Theme of This Tutorial
GPU is fast, and viz is built-in
GPU can be programmed at high level
Some of the most challenging aspects of computation and
visualization of large data
interactivity
dynamic data
GPU enables both
An Extended Example
Reverse Nearest Neighbours
An instance consists of clients and servers
Each server “serves” those clients that it is closest to.
What is the load on a server ? It is the number of clients that
consider this server to be their nearest neighbour (among all
servers)
Hence, the term “reverse nearest neighbour”: for each
server, find its reverse nearest neighbours.
Note: both servers and clients can move or be inserted or
deleted.
What do we know ?
First proposed by Korn and Muthukrishnan (2000)
1-D, static
Easy if servers are fixed (compute Voronoi diagram of
servers, and locate clients in the diagram)
In general, hard to do with moving clients and servers in two
dimensions.
Algorithmic strategy
For each of N clients
iterate over each of M servers, find closest one
For each of M servers
iterate over each of N clients that consider it closest,
and count them.
apparent “complexity” is M * N
……Or is it ?
Looking more closely…
For each of N clients
iterate over each of M servers, find closest one
For each of M servers
iterate over each of N clients that consider it closest,
and count them.
Each of these loops can be performed in parallel
Looking more closely…
For each of N clients
iterate over each of M servers, find closest one
For each of M servers
iterate over each of N clients that consider it closest,
and count them.
Complexity is N + M
Demo
Demo: Change distance function
RNN as special case of EM
In expectation-maximization, in each iteration
first determine which points are to be associated with
which cluster centers (the “nearest neighbour” step)
Then compute a new cluster center based on the points
in a cluster (the “counting” step)
We can implement expectation-maximization on the GPU !
More later
What does this example show us?
GPU is fast
GPU is programmable
GPU can deal with dynamic data
GPU can be used for interactive visualization
However, care is needed to get the best performance
Coming up next …
How do we abstract the GPU?
What is an efficient GPU program
How various data mining primitives are implemented
Using the GPU for non-standard data visualization
PART II. Stream algorithms using
the GPU
Programmable Graphics Pipeline
3D API:
OpenGL or
Direct3D
3D API
Commands
3D
Application
Or Game
Vertex
Index
Stream
Primitive
Assembly
Pre-transformed
Fragments
Pre-transformed
Vertices
Programmable
Vertex
Processor
Programmable
Fragment
Processor
Transformed
Fragments
GPU
Front End
Pixel
Pixel
Location
Updates
Stream
Rasterization
Frame
Raster
and
Buffer
Operations
Interpolation
Assembled
Primitives
Transformed
Vertices
GPU
Command &
Data Stream
CPU-GPU Boundary
Courtesy: Cg Book [Fernando and Kilgard]
Think parallel
First cut: Each Pixel is a processor.
Not really – multiple pipes
Each of the pipes perform bits of the whole
The mapping is not necessarily known
Can even be load dependent
But the drivers think that way.
Order of completion is not guaranteed
i.e. cannot say that the computation proceeds along “scan”
lines
Restricted interaction between pixels
We cannot write and read the same location
Think simple
SIMD machine
Single instruction
Same program is applied at every pixel
Recall data parallelism
Program size is bounded
The ability to keep state is limited
Cost is in changing state: a pass-based model
Cannot read and write from same memory location in a
single pass
Think streams
Works as transducers or kernels : Algorithms that take an
input, consume it and output a transform before looking at
the next input.
Can set up networks
Example: Dense Matrix
Multiplication
Larsen/McAllester (2002), Hall, Carr & Hart (2003)
Given matrices X, Y, compute Z=XY
For s=1 to n
For t=1 to n
Zst=0
For m:=1 to n Do
Zst ← Zst+XsmYmt
EndFor
EndFor
EndFor
Data Structures
For s=1 to n
For t=1 to n
Zst=0
For m:=1 to n Do
Zst ← Zst+XsmYmt
EndFor
EndFor
EndFor
Data Structures: Arrays X,Y,Z
How are arrays implemented in GPUs ?
As texture memory (Used for shading
and bump maps)
Fast texture lookups built into pipeline.
Textures are primary storage mechanism
for general purpose programming
Control Flow
For s=1 to n
For t=1 to n
Zst=0
For m:=1 to n
Zst ← Zst+XsmYmt
EndFor
EndFor
EndFor
For s=1 to n
For t=1 to n
Zst ← 0
For m=1 to n
For s=1 to n
For t=1 to n
Zst ← Zst+XsmYmt
EndFor
EndFor
Endfor
From Loops to Pixels
For m=1 to n
For s=1 to n
For t=1 to n
Zst ← Zst+XsmYmt
EndFor
EndFor
Endfor
For m=1 to n
For pixel (s,t)
Zst ← Zst+XsmYmt
EndFor
Endfor
Operations for all pixels are performed in “parallel”
Is that it ? SIMD …
For m=1 to n
For s=1 to n
For t=1 to n
R1.r ← lookup(s,m,X)
R2.r ← lookup(m,t,Y)
R3.r ← lookup(s,t,Z)
buffer ← R3.r + R1.r * R2.r
EndFor
EndFor
Save buffer into Z
Each pixel (x,y) gets the parameter m:
Endfor
R1.r ← lookup(myxcoord,m,X)
R2.r ← lookup(m,myycoord,Y)
R3.r ← lookup(myxcoord,mycoord,Z)
mybuffer ← R3.r + R1.r * R2.r
Analysing theoretically
O(n) passes to multiply two n X n matrices. Uses O(n2) size
textures.
Your favourite parallel algorithm for matrix multiplication can be
mapped onto GPU
How about Strassen ?
Number of passes is the same
Total work decreases
Can reduce the # to O(n0.9) using special packing ideas
[GKV04]
In practice…
Simpler implementations win out
The fastest GPU implementation uses n matrix—vector
operations, and packs data into 4-vectors.
It is better than naïve code using three For loops, but not
better than using optimized CPU code, e.g., in linear algebra
packages.
Trendlines show that the running time of GPU code grows
linearly.
Packing and additions, e.g. in Strassen type algorithms are
problematic due to data movement, cache effects.
Summing up
SIMD machine
Pass based computation
Pipelined operation
Cost is in changing state
Total work
Revisiting RNN
Recall the two implementations
M*N distances need to be evaluated
First idea:
M+N passes using M+N processors in parallel
N
Second idea:
M x N grid to compute the distances
1 pass
Find Min in 1 pass ?
How to aggregate ?
M
GPU hardware modelling
The GPU is a parallel processor, where each pixel can be
considered to be a single processor (almost)
The GPU is a streaming processor, where each pixel
processes a stream of data
We can build high-level algorithms (EM) from low level
primitives (distance calculations, counting)
Operation costs
When evaluating the cost of an operation on the GPU,
standard operation counts are not applicable
The basic unit of cost is the “rendering pass”, consisting
of a stream of data being processed by a single program
Virtual parallelism of GPU means that we “pretend” that
all streams can be processed simultaneously
Assign a cost of 1 to a pass: this is analogous to external
memory models where each disk access is 1 unit
Many caveats
An extreme example
One pass median finding
Well studied problem in streaming with log n pass lower bound.
Consider repeating the data O(log n) times to get a sequence of size
O(n log n)
At any point the algorithm has an UB and an LB.
1.
2.
3.
4.
The algorithm reads the next n numbers and picks a random
element u between the LB and UB.
The algorithm uses the next n numbers and finds the rank of u.
Now it sets LB=u or UB=u depending on counts.
Repeat !
Quickfind!
Why does the example not generalize?
Read is not the same as Write.
Total work vs number of passes.
PART II.5. Data Mining Primitives
I: Clustering
Problem definition: Given N points find K points c i to
optimize
min
2
min
dist
i ( x j , ci )
j
Hall & Hart ’03: K+N pass KMEANS algorithm
What we will see:
Log N passes per iteration
EM and “soft assignments”
K-Means 2D version
Basic Algorithm: Recall Voronoi scenario
Why GPU ?
Motion/updates ! When does the cross over happen ?
K-Means in GPU
In each pass, given a set of K colors we can assign a “color”
to each point and keep track of “mass” and “mean” of each
color.
Issues:
Higher D
Extension to more general algorithms
The RNN type approach
N
K*N distances, 1 pass
Compute min, logarithmic passes
Aggregate, logarithmic passes
Normalize and compute new centers
High D ? Replace 1 by O(D)
K
EM ? Instead of Min (which is 0/1) compute “shares”
Same complexity!
Demo: Expectation Maximization
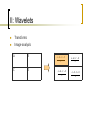
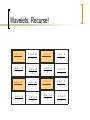
II: Wavelets
Transforms
Image analysis
A
B
C
D
A B C D
2
A B C D
2
A B C D
2
A B C D
2
Wavelets: Recurse!
A B C D
2
A B C D
2
A B C D
2
A B C D
2
A B C D
2
A B C D
2
A B C D
2
A B C D
2
A B C D
2
A B C D
2
A B C D
2
A B C D
2
A B C D
2
A B C D
2
A B C D
2
A B C D
2
DWT Demo
Wang, Wong, Heng & Leung
http://www.cse.cuhk.edu.hk/~ttwong/demo/dwtgpu/dwtgpu.html
DWT Demo
Wang, Wong, Heng & Leung
http://www.cse.cuhk.edu.hk/~ttwong/demo/dwtgpu/dwtgpu.html
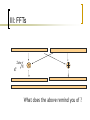
III: FFTs
e
2in
N
What does the above remind you of ?
FFT Demo
Moreland and Angel
http://www.cs.unm.edu/~kmorel/documents/fftgpu/
III: Sorting Networks!
Can be used for quantiles, computing histograms
GPUSort: [Govindaraju etal 2005]
Basically “network computations”
Each pixel performs some local piece only.
In summary
The big idea
Think parallel.
Think simple.
Think streams.
SIMD
Pass based computing
Tradeoff of pass versus total cost
“Ordered” access
Next up
We saw “number crunching algorithms”.
What are the applications in mining which are
“combinatorial” in nature and yet visual ?
And of courses, resources and howtos.
Part III: Other GPU Case Studies
and High-level Software Support
for the GPU
What have we seen so far
Computation on the GPU
How to program
Cost model
What is cheap and expensive
Number based problems, e.g.,
nearest neighbor (Voronoi), clustering, wavelets, sorting
What you will see …
Examples with different kinds of input data
1.
Computation of Depth Contours
2.
Graph Drawing
Languages and tools to program the GPU
Final wrap-up
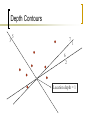
Depth Contours
Depth Contours
3
5
7
1
6
2
Location depth = 1
Depth Contours
k-contour: set of all
points having location
depth ≥ k
Every n-point set has an
n/3-contour
The Tukey median is the
deepest contour.
We wish to compute the set of all depth contours
Motivation
Special case of general non-parametric data analysis tool
“visualize the location, spread, correlation, skewness, and tails of the data”
[Tukey et al 1999]
Hypothesis testing, robust statistics
Point-Hyperplane Duality
Mapping from R2 R2
Points get mapped to lines and vice-versa
(a,b) y = -ax + b
y = ax + b (a,b)
Incidence properties are preserved
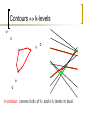
Contours k-levels
k-contour: convex hulls of k- and n-k levels in dual.
Main Algorithm
Draw primal line for each dual pixel that lies on a dual line
Record only (at each primal pixel) the line whose dual pixel has least depth
Recall nearest neighbor (Voronoi), clustering – we are using the geometry heavily
Demo: Depth Contours
Dynamic Depth Contours
Smooth, but random movement of points
Compute incremental depth changes using duals
Worst-case quadratic updates might be performed
In practice, small number of updates
Can achieve real-time speeds for first time
Dynamic Depth Contours
Graph Drawing
Graph Drawing
Graph
Set of vertices
Boolean relation between pairs of vertices defines edges
Given a graph, layout the vertices and edges in a plane based
on some aesthetics
Abstract Graph
Example
9 vertices, 12 edges
Edges
v1: v2, v4
v2: v1, v3, v5
v3: v2, v6
v4: v1, v5, v7
v5: v2, v4, v6, v8
v6: v3, v5, v9
v7: v4, v8
v8: v5, v7, v9
v9: v6, v8
After Graph Layout
grid3.graph
v7
v4
v1
v8
v5
v2
v9
v6
v3
Can visualize the relationships much better
Force-Directed Layouts
Start with random initial placement of vertices
Define an energy field on the plane using forces between vertices
(both attractive and repulsive)
Fattractive(v i )
c. (v j v i ) .(v j v i )
( v i ,v j )E
1
1
Freplusive(v i ) .
.(v i v j )
2
j i c
(v i v j )
Evolve the system based on the energy field
Local energy minimization defines the layout
Essentially solving a N-body problem
GPU Algorithm
Naïve approach
At each iteration
Compute pairwise repulsive forces
Compute attractive forces between edges
Force on each vertex is sum of individual forces
Resultant force defines vertex displacement
Displace vertices and iterate
Complexity – O(n) per iteration
Bottleneck – summing individual forces
Optimized approach
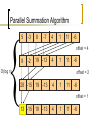
Use logarithmic parallel summation algorithm
Complexity – O(log n) per iteration
Parallel Summation Algorithm
5
9
-3
8
-7
4
1
11
-6
offset = 4
-2
19 -13
4
1
11
O(log n)
28 -15 19 -13
13 -15 19 -13
-6
offset = 2
4
1
11
-6
offset = 1
4
1
11
-6
Demo: Graph Drawing
Software tools
GPGPU Languages
Why do we want them?
Make programming GPUs easier!
Don’t need to know OpenGL, DirectX, or ATI/NV
extensions
Simplify common operations
Focus on the algorithm, not on the implementation
Sh
University of Waterloo
http://libsh.sourceforge.net
Brook
Stanford University
http://brook.sourceforge.net
Brook
Brook: Streams
streams
collection of records requiring similar computation
particle positions, voxels, FEM cell, …
float3 positions<200>;
float3 velocityfield<100,100,100>;
similar to arrays, but…
index operations disallowed: position[i]
read/write stream operators
streamRead (positions, p_ptr);
streamWrite (velocityfield, v_ptr);
encourage data parallelism
Slide Courtesy: Ian Buck
Brook: Kernels
kernels
functions applied to streams
similar to for_all construct
kernel void foo (float a<>, float b<>,
out float result<>) {
result = a + b;
}
float a<100>;
float b<100>;
float c<100>;
foo(a,b,c);
for (i=0; i<100; i++)
c[i] = a[i]+b[i];
Slide Courtesy: Ian Buck
Brook: Kernels
kernels
functions applied to streams
similar to for_all construct
kernel void foo (float a<>, float b<>,
out float result<>) {
result = a + b;
}
no dependencies between stream elements
encourage high arithmetic intensity
Slide Courtesy: Ian Buck
Brook: Reductions
reductions
compute single value from a stream
reduce void sum (float a<>,
reduce float r<>)
r += a;
}
float a<100>;
float r;
sum(a,r);
r = a[0];
for (int i=1; i<100; i++)
r += a[i];
Slide Courtesy: Ian Buck
Brook: Reductions
reductions
associative operations only
(a+b)+c = a+(b+c)
Order independence
sum, multiply, max, min, OR, AND, XOR
matrix multiply
Slide Courtesy: Ian Buck
Brook: Reductions
multi-dimension reductions
stream “shape” differences resolved by reduce function
reduce void sum (float a<>,
reduce float r<>)
r += a;
}
float a<20>;
float r<5>;
sum(a,r);
for (int i=0; i<5; i++)
r[i] = a[i*4];
for (int j=1; j<4; j++)
r[i] += a[i*4 + j];
Slide Courtesy: Ian Buck
Brook: Matrix Vector Multiply
kernel void mul (float a<>, float b<>,
out float result<>)
{ result = a*b; }
reduce void sum (float a<>,
reduce float result<>)
{ result += a; }
float
float
float
float
matrix<20,10>;
vector<10, 1>;
tempmv<20,10>;
result<20, 1>;
mul(matrix,vector,tempmv);
sum(tempmv,result);
M
V
V
V
=
T
Slide Courtesy: Ian Buck
Brook: matrix vector multiply
kernel void mul (float a<>, float b<>,
out float result<>)
{ result = a*b; }
reduce void sum (float a<>,
reduce float result<>)
{
result += a; }
float
float
float
float
matrix<20,10>;
vector<10, 1>;
tempmv<20,10>;
result<20, 1>;
mul(matrix,vector,tempmv);
sum(tempmv,result);
T
sum
R
Slide Courtesy: Ian Buck
Demo: Matrix Vector Multiplication
Demo:
Bitonic Sort and Binary Search
Debugging Tools
Debugger Features
Per-pixel register watch
Including interpolants, outputs, etc.
Breakpoints
Fragment program interpreter
Single step forwards or backwards
Execute modified code on the fly
Slide Courtesy: Tim Purcell
Shadesmith
http://graphics.stanford.edu/projects/shadesmith
Debugger in the spirit of imdebug
Simply add a debug statement when binding shaders
Display window with scale, bias, component masking
Advanced features
Can watch any shader register contents without recompile
Shader single stepping (forward and backward), breakpointing
Shader source edit and reload without recompile
Slide Courtesy: Tim Purcell
Demo: Shadesmith
GPGPU.org
Your first stop for GPGPU information!
News: www.GPGPU.org
Discussion: www.GPGPU.org/forums
Developer resources, sample code, tutorials:
www.GPGPU.org/developer
And for open source GPGPU software:
http://gpgpu.sourceforge.net/
Summing up
What we saw in this tutorial …
GPU is fast outperforming the CPU
Shown to be effective in a variety of applications
High memory bandwidth
Parallel processing capabilities
Interactive visualization applications
Data mining, simulations, streaming operations
Spatial database operations
High-level programming and debugging support
Limitation of the GPU
Not designed as a general-purpose processor
meant to extract maximum performance for highly
parallel tasks of computer graphics
Will not be suited for all applications
Bad for “pointer chasing” tasks
word processing
No bit shifts or bit-wise logical operations
Cryptography
No double precision arithmetic yet
Large scale scientific applications
Unusual programming model
Conclusions: Looking forward
Increased performance
More features
double precision arithmetic
Bit-wise operations
Random bits
Increased programmability and generality
strike the right balance between generality and
performance
Other data-parallel processors will emerge
Cell processor by IBM, Sony, Toshiba
Better suited to general-purpose stream computing
Questions?
Slides can be downloaded soon from
http://www.research.att.com/areas/visualization/gpgpu.html