Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Expectation–maximization algorithm wikipedia , lookup
Bias of an estimator wikipedia , lookup
Data assimilation wikipedia , lookup
Interaction (statistics) wikipedia , lookup
Time series wikipedia , lookup
Regression toward the mean wikipedia , lookup
Choice modelling wikipedia , lookup
Instrumental variables estimation wikipedia , lookup
Linear regression wikipedia , lookup
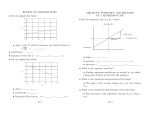
Econometrics--Econ 388 Spring 2008, Richard Butler Final Exam your name_________________________________________________ Section Problem Points Possible I 1-20 3 points each II 21 22 23 24 25 26 10 points 10 points 5 points 5 points 10 points 10 points III 27 28 29 30 points 30 points 30 points 1 I. Define or explain the following terms: 1. inverse of a matrix-- 2. show that N N i 1 i 1 ( yi y )( xi x ) ( yi y ) xi 3. standardized score (or Z-score)-- 4. slope coefficient in a simple regression model- 5. type I vs. type II errors - 6. law of large numbers- 7. cointegration of two time series, wt and vt-- 8. dummy variable trap- 9. LaGrange-Multiplier test- 10. method of moment estimators – 2 11. maximum likelihood estimation criterion - 12. logistic regression model - 13. “boundedness” problem in the linear probability model - 14. structural vs. reduced form equations - 15. Breusch-Pagan test- 16. dynamically complete models- 17. weak dependence (in time series) - 18. Durbin-Watson test - 19.omitted variable bias - 20. prediction variance for yT (value of yt next year) when the true model is yt xt t when the usual assumptions hold-3 II. Some Concepts 21. Probability Theory: Suppose that a fair coin is relabeled so that heads are 1, and tails are 2, and that the fair coin is tossed twice. The outcome of the first toss is i (so i=1 or 2) and the outcome of the second toss is j (so j=1 or 2). From these experimental outcomes construct the following two random variables: X=i+j Y= |i-j| a) Construct the joint distribution of random variables X and Y. b) What is the conditional distribution of X given Y=0? What is the conditional distribution of of X given that Y=1? c) Are X and Y independent? 4 22. Write STATA programs (or SAS) to make the following tests or estimate the following models requested below, assuming that the sample variables A and B are endogeneous, and that the exogeneous variables are C, D, E, and F. a. Ai 0 1Bi 2Ci 3 Di i side of the equation. Do a Hausman test for endogeneity of B on the right hand b. For the same model as in (a), write out the STATA code to test for overidentifying restrictions on the “extra” identifying variables, E and F. c. For the same model as in (a), write out the STATA code to estimate the model in (a) by two stage least squares. 5 23. For the simpliest regression (one slope variable, no intercept in the model), we have yi xi i , and the following picture for our particular sample, where length of the y-vector is 50 as indicated, and the length of the x vector is 10. If the angle between the x vector and the y-vector is 45 degrees, than a) what is the OLS estimate, ˆ , and b) what will be the residual sum of squares? (Warning, the picture is deliberately NOT drawn to scale, so do the math) Y: length= 50 45 X: length=10 24. Below are the descriptive statistics and regression of annual sales on salesman’s age for the Covey trained people in our class example: -----------------------------------------------------------------------------ann_sale | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------age | .3305073 .0917516 3.60 0.005 .126072 .5349425 _cons | 47.51559 4.30679 11.03 0.000 37.91946 57.11172 -----------------------------------------------------------------------------------------------------------------------------------------Variable | Mean Std. Dev. Min Max -------------+----------------------------------------------ann_sale | 62.33333 6.386539 52 73 age | 44.83333 14.52167 21 67 ------------------------------------------------------------- a) If I want a beta coefficient (standard deviation changes) instead of the usual OLS coefficient, what will be the value of the new slope coefficient? b) If instead of age (where birth=0), I regress annual sales on age_since_20 (where for a 20 year old, age_since_20=0, and birth= -20) what would be the new slope and intercept values with this change in the way that the slope variable is measured? 6 25. Let Wi=weight in pounds of the ith person, and Hi=height of the ith person in inches above five feet (so a six-foot person would have H=12). Suppose that a sample of 100 males yields the following sample regression function (ignoring the error term), which is statistically significant at the five percent level: Wi = 125 + 4.0 Hi Sum of Squared Errors=1800.0 a. If coach is 76 inches tall, what is his predicted weight? Now suppose that a friend suggests adding Fi, the percent body fat, to the equation (where F=10 means 10 percent body fat). The body fat of our 100 males is measured, and the new model is estimated as follows: Wi = 120 + 4.1 Hi + .3 Fi Sum of Squared Errors=600.0 b. If coach has a percent body fat of 25%, what is his predicted weight based on the second equation? c. Which equation do you prefer, if you only want to include statistically significant regressors? (Show your reasoning, including any necessary derivations. You can assume that absolute t values greater than 2 are significant, and chi-square and F-statistic values greater than 3 are significant under the null hypothesis). 7 26. Suppose that for the standard regression model, y X , we rescale both the independent variables and the dependent variable by non-zero variables c0, c1, c2, …, ck by regressing c0yi on a constant c1, c2x2i, c3x3i,…, ckxki (so there are k regressors, including an intercept which is measured as c1 instead of 1). In other words, instead of the OLS estimator ˆ ( X ' X ) 1 X ' Y , you do OLS on the transformed data ˆ * ( X * ' X * ) 1 X * ' Y * , where the transformed data can be described by: c1 0 0 0 0 c 0 0 0 0 0 0 c 0 c 0 0 0 0 0 0 2 0 X * XC where C 0 0 c3 0 0 and Y * C 0Y , C 0 0 0 c0 0 0 = c0 I . 0 0 0 ... 0 0 0 0 ... 0 0 0 0 0 c k 0 0 0 0 c0 Prove that the ith beta between the transformed data, and the untransformed data, have the c following relationship: ˆi* 0 ˆi . ci 8 III. Some Bigger Proofs. 27. Prove that s2, the estimator of the variance of µi (where µi is the error term in the classical regression model), is unbiased using matrix algebra. 9 28. Given the usual regression model Y X where the population error terms have a first order autoregressive process: t t 1 et where et is a white noise error term, independently distributed with zero mean and variance 2 , derive the variance-covariance matrix for . 10 29. Given the usual assumptions about the n by k matrix of instrumental variables, Z, prove that the instrumental variable estimator is consistent: Z'X i.e., prove that for ˆIV (Z ' X )1 Z 'Y that plim ˆIV . (You may assume that is a n positive definite matrix with finite elements for any value of n, the sample size). 11