
SRCMF tutorial
... Figure 7: Graphs and subgraphs The navigation panel below the graph contains some useful quantitative information about the query results (see figure 7), in particular the number of matching GRAPHS and SUBGRAPHS. It is very important to understand what these numbers mean! ...
... Figure 7: Graphs and subgraphs The navigation panel below the graph contains some useful quantitative information about the query results (see figure 7), in particular the number of matching GRAPHS and SUBGRAPHS. It is very important to understand what these numbers mean! ...

The Expressive Pause: Punctuation, Rests, and Breathing in
... and exclamations were indeterminate in length, some writers remarking that the stop may be equivalent to a comma, semicolon, colon, or period, as the sense of the sentence demands. 20 One writer, however, Joseph Robertson, notes that in questions the stop should be longer than that of a period, beca ...
... and exclamations were indeterminate in length, some writers remarking that the stop may be equivalent to a comma, semicolon, colon, or period, as the sense of the sentence demands. 20 One writer, however, Joseph Robertson, notes that in questions the stop should be longer than that of a period, beca ...

Spelling - Broadhurst Primary School
... Set 6: Words ending in 'nk' and words of two syllables Set 7: Words ending in 'tch' and 've' Set 8: Words ending in 's' and ‘es' Set 9: Words with short vowel sounds ending in 'er' and 'est' Set 10: Words with long vowel sounds ending in 'er' and 'est' Set 11: Words containing 'ai' and 'oi' Set 12: ...
... Set 6: Words ending in 'nk' and words of two syllables Set 7: Words ending in 'tch' and 've' Set 8: Words ending in 's' and ‘es' Set 9: Words with short vowel sounds ending in 'er' and 'est' Set 10: Words with long vowel sounds ending in 'er' and 'est' Set 11: Words containing 'ai' and 'oi' Set 12: ...

Sense and Reference
... Identity1 gives rise to challenging questions which are not altogether easy to answer. Is it a relation ? A relation between objects, or between names or signs of objects? In my BegriffsschriftA I assumed the latter. The reasons which seem to favor this are the following: a=a and a=b are obviously s ...
... Identity1 gives rise to challenging questions which are not altogether easy to answer. Is it a relation ? A relation between objects, or between names or signs of objects? In my BegriffsschriftA I assumed the latter. The reasons which seem to favor this are the following: a=a and a=b are obviously s ...

Frege: ON SENSE AND REFERENCE
... Equality [1] gives rise to challenging questions which are not altogether easy to answer. Is it a relation? A relation between objects, or between names or signs of objects? In my Begriffsschrift [2] I assumed the latter. The reasons which seem to favour this are the following: a = a and a = b are o ...
... Equality [1] gives rise to challenging questions which are not altogether easy to answer. Is it a relation? A relation between objects, or between names or signs of objects? In my Begriffsschrift [2] I assumed the latter. The reasons which seem to favour this are the following: a = a and a = b are o ...

The Case of Old English HRĒOW
... because it is fairly regular as well as relatively predictable and, moreover, operates on a lexical stock consistently comprised of Germanic items. On the theoretical side, the line is taken that the interplay of paradigmatic and syntagmatic resources can explain morphological processes from several ...
... because it is fairly regular as well as relatively predictable and, moreover, operates on a lexical stock consistently comprised of Germanic items. On the theoretical side, the line is taken that the interplay of paradigmatic and syntagmatic resources can explain morphological processes from several ...

FRAME SEMANTICS Miriam RL Petruck
... illustrated with the words land and ground, both of which identify the same entity, the dry surface of the earth. Hearing that a traveler spent a few hours on land, we understand that the traveler interrupted a sea voyage; hearing that a traveler spent a few few hours on the ground, we understand th ...
... illustrated with the words land and ground, both of which identify the same entity, the dry surface of the earth. Hearing that a traveler spent a few hours on land, we understand that the traveler interrupted a sea voyage; hearing that a traveler spent a few few hours on the ground, we understand th ...

Narrative writing marking guide
... • space between blocks of text • student annotations, eg P for paragraph, tram lines, square brackets, asterisk • available space on previous line left unused, followed by new line for paragraph beginning. ...
... • space between blocks of text • student annotations, eg P for paragraph, tram lines, square brackets, asterisk • available space on previous line left unused, followed by new line for paragraph beginning. ...

Frege - Princeton University
... Identity1 gives rise to challenging questions which are not altogether easy to answer. Is it a relation ? A relation between objects, or between names or signs of objects? In my BegriffsschriftA I assumed the latter. The reasons which seem to favor this are the following: a=a and a=b are obviously s ...
... Identity1 gives rise to challenging questions which are not altogether easy to answer. Is it a relation ? A relation between objects, or between names or signs of objects? In my BegriffsschriftA I assumed the latter. The reasons which seem to favor this are the following: a=a and a=b are obviously s ...

Computing with Words - People @ EECS at UC Berkeley
... that Computing With Words (CWW) is a methodology in which the objects of computation are words and propositions drawn from a natural language. [It is] inspired by the remarkable human capability to perform a wide variety of physical and mental tasks without any measurements and any computations. Thi ...
... that Computing With Words (CWW) is a methodology in which the objects of computation are words and propositions drawn from a natural language. [It is] inspired by the remarkable human capability to perform a wide variety of physical and mental tasks without any measurements and any computations. Thi ...

Reference Manual for Interpreting the New Testament
... to locate the circumstances of a given epistle; they are trying to discover information about author and audience, which will help complete the understanding of the particular act of communication represented by the message. At this point, an important warning needs to be expressed. For students of ...
... to locate the circumstances of a given epistle; they are trying to discover information about author and audience, which will help complete the understanding of the particular act of communication represented by the message. At this point, an important warning needs to be expressed. For students of ...

The Alpino Dependency Treebank
... dependency structure, which is a relatively theory independent annotation format. The format is taken from the corpus of spoken Dutch (CGN)1 (Oostdijk 2000), which in turn based its format on the Tiger Treebank (Skut 1997). In section 3 we go into the characteristics of dependency structures and mot ...
... dependency structure, which is a relatively theory independent annotation format. The format is taken from the corpus of spoken Dutch (CGN)1 (Oostdijk 2000), which in turn based its format on the Tiger Treebank (Skut 1997). In section 3 we go into the characteristics of dependency structures and mot ...

writing style guide - University of Hull
... wall. The hope is that this balanced approach will satisfy the broadest possible readership, including both young people and their influencers. Only up to a point, however, is it possible to generalise about ‘University of Hull style’. While our rules concerning hyphens or capital initials, for exam ...
... wall. The hope is that this balanced approach will satisfy the broadest possible readership, including both young people and their influencers. Only up to a point, however, is it possible to generalise about ‘University of Hull style’. While our rules concerning hyphens or capital initials, for exam ...

Robust Handling of Out-of-Vocabulary Words in
... to the property of lexical novelty that is intrinsic to natural languages, deep grammars need some mechanism to handle OOV words if they are to be used in applications to analyze unrestricted text. The aim of this work is thus to investigate ways of improving the handling of OOV words in deep gramma ...
... to the property of lexical novelty that is intrinsic to natural languages, deep grammars need some mechanism to handle OOV words if they are to be used in applications to analyze unrestricted text. The aim of this work is thus to investigate ways of improving the handling of OOV words in deep gramma ...

A Review of Machine Learning Algorithms for Text
... the classification accuracy of some learning algorithms as their evaluation function. Since wrappers have to train a classifier for each feature subset to be evaluated, they are usually much more time consuming especially when the number of features is high. So wrappers are generally not suitable fo ...
... the classification accuracy of some learning algorithms as their evaluation function. Since wrappers have to train a classifier for each feature subset to be evaluated, they are usually much more time consuming especially when the number of features is high. So wrappers are generally not suitable fo ...

Probabilistic Topic Models - UCI Cognitive Science Experiments
... depending on the weight given to the topic. For example, documents 1 and 3 were generated by sampling only from topic 1 and 2 respectively while document 2 was generated by an equal mixture of the two topics. Note that the superscript numbers associated with the words in documents indicate which top ...
... depending on the weight given to the topic. For example, documents 1 and 3 were generated by sampling only from topic 1 and 2 respectively while document 2 was generated by an equal mixture of the two topics. Note that the superscript numbers associated with the words in documents indicate which top ...

Usage-based vs. rule-based learning: the acquisition of word order
... A constructivist account of the acquisition of wh-questions in English is advocated by Rowland & Pine (2000, 2003) and Rowland, Pine, Lieven & Theakston (2003). This approach argues that English-speaking children’s early wh-questions are the result of a distributional learning mechanism that reprodu ...
... A constructivist account of the acquisition of wh-questions in English is advocated by Rowland & Pine (2000, 2003) and Rowland, Pine, Lieven & Theakston (2003). This approach argues that English-speaking children’s early wh-questions are the result of a distributional learning mechanism that reprodu ...

click to proceedings of the conference.
... Treebank (MST) [29] has proved to be an invaluable resource over the years, and has been utilized by almost every Turkish dependency parser to date. However, its dependency grammar has come to be criticized on occasion from various standpoints, and it is known to contain a large amount of annotation ...
... Treebank (MST) [29] has proved to be an invaluable resource over the years, and has been utilized by almost every Turkish dependency parser to date. However, its dependency grammar has come to be criticized on occasion from various standpoints, and it is known to contain a large amount of annotation ...

A Study of the Microstructure of Monolingual Urdu Dictionaries
... not to provide lexical relations. The figures in Table 2-b and the discussion indicate that these Urdu dictionaries mostly include synonyms as meanings, even though it creates ambiguities. This may be the reason these dictionaries avoid giving importance to synonymy as an additional element. The NOD ...
... not to provide lexical relations. The figures in Table 2-b and the discussion indicate that these Urdu dictionaries mostly include synonyms as meanings, even though it creates ambiguities. This may be the reason these dictionaries avoid giving importance to synonymy as an additional element. The NOD ...

Functional and Content Words
... sign capable of functioning alone (the word understood as the "smallest free form", or interpreted as the "potential minimal sentence"), it is irrelevant for the bulk of functional words which cannot be used "independently" even in elliptical responses (to say nothing of the fact that the very notio ...
... sign capable of functioning alone (the word understood as the "smallest free form", or interpreted as the "potential minimal sentence"), it is irrelevant for the bulk of functional words which cannot be used "independently" even in elliptical responses (to say nothing of the fact that the very notio ...
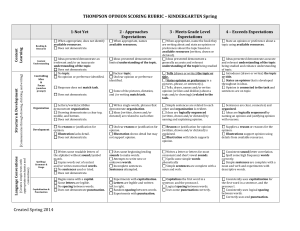
THOMPSON OPINION SCORING RUBRIC
... States an opinion, develops with reasons and details, and concludes an opinion piece of writing that demonstrates an understanding of the topic. Introduces the topic or text by hooking readers into caring or wanting to learn about the topic. Creates a structure that lists reasons. Uses linking words ...
... States an opinion, develops with reasons and details, and concludes an opinion piece of writing that demonstrates an understanding of the topic. Introduces the topic or text by hooking readers into caring or wanting to learn about the topic. Creates a structure that lists reasons. Uses linking words ...

Natural Language Processing in Perl
... lazy dogs"; my @words = split / /, $text; my $stems = stem(@words); print "@$stems\n"; # the quick brown fox jump over the lazi dog ...
... lazy dogs"; my @words = split / /, $text; my $stems = stem(@words); print "@$stems\n"; # the quick brown fox jump over the lazi dog ...
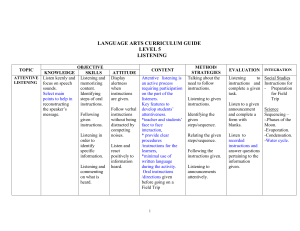
Gr V Lang Art - Teacher Training materials for ICT in Education
... KNOWLEDGE SKILLS ATTENTIVE Listen keenly and Listening and LISTENING focus on speech ...
... KNOWLEDGE SKILLS ATTENTIVE Listen keenly and Listening and LISTENING focus on speech ...

Quantum Neural Network based Parts of Speech Tagger for Hindi
... context. For the subsequent manipulations of the text, annotation of a text with POS tags is useful. The tagger processes all words and that belongs to a certain class providing a useful abstraction in some special way like getting all verbs from a text. The grammatical parts of speech are important ...
... context. For the subsequent manipulations of the text, annotation of a text with POS tags is useful. The tagger processes all words and that belongs to a certain class providing a useful abstraction in some special way like getting all verbs from a text. The grammatical parts of speech are important ...

Categorizing Words Using "Frequent Frames": What Cross
... distributional information of this type as a primary basis for categorizing words. In the past decade, a number of studies have investigated how useful purely distributional information might be to young children in initially forming categories of words (Cartwright & Brent, 1997; Mintz, 2003; Mintz, ...
... distributional information of this type as a primary basis for categorizing words. In the past decade, a number of studies have investigated how useful purely distributional information might be to young children in initially forming categories of words (Cartwright & Brent, 1997; Mintz, 2003; Mintz, ...