
Semantic peculiarities of homonyms in English and Uzbek
... Modern English has a very extensive vocabulary; the number of words according to the dictionary data is no less than 400, 000.A question naturally arises whether this enormous word-stock is composed of separate independent lexical units, or may it perhaps be regarded as a certain structured system m ...
... Modern English has a very extensive vocabulary; the number of words according to the dictionary data is no less than 400, 000.A question naturally arises whether this enormous word-stock is composed of separate independent lexical units, or may it perhaps be regarded as a certain structured system m ...


Negative Prefixes in English and Macedonian
... contrary opposition is a relation among many terms on the scale, and it is not the case that if one entity is negated, it is a negative counterpart of the term on the other end, because there are not only two terms, but several which exhibit the scalar character of this kind of opposition. Consequen ...
... contrary opposition is a relation among many terms on the scale, and it is not the case that if one entity is negated, it is a negative counterpart of the term on the other end, because there are not only two terms, but several which exhibit the scalar character of this kind of opposition. Consequen ...

A Argumentation Mining: State of the Art and Emerging Trends
... before we discuss methods, we shall first define a taxonomy to organize the tasks that go under the umbrella of AM. Next, we will survey the machine learning and natural language methods employed by existing systems based on the role they play in a typical AM system architecture. The systems develop ...
... before we discuss methods, we shall first define a taxonomy to organize the tasks that go under the umbrella of AM. Next, we will survey the machine learning and natural language methods employed by existing systems based on the role they play in a typical AM system architecture. The systems develop ...

From a children`s first dictionary to a lexical
... The study of words in the goal of understanding their meaning and how they relate to each other is a very large and complex field in itself. Aiming t o render this information usable by a computer presents an even larger problem. Researchers have tried to constrain this problem in a few ways. Words ...
... The study of words in the goal of understanding their meaning and how they relate to each other is a very large and complex field in itself. Aiming t o render this information usable by a computer presents an even larger problem. Researchers have tried to constrain this problem in a few ways. Words ...

met*: A Method for Discriminating Metonymy and Metaphor by
... Structure-Mapping Engine (Falkenhainer, Forbus and Gentner 1989), closely resembles a comparison view of metaphor. The theory addresses literal similarity, analogy, abstraction, and anomaly, which Gentner refers to as four "kinds of comparison." An algorithm compares the semantic information from tw ...
... Structure-Mapping Engine (Falkenhainer, Forbus and Gentner 1989), closely resembles a comparison view of metaphor. The theory addresses literal similarity, analogy, abstraction, and anomaly, which Gentner refers to as four "kinds of comparison." An algorithm compares the semantic information from tw ...

sv-lncs
... The special case is the relation DERIVED which was introduced into EWN to capture derivational relations existing in some EWN languages, however, according to our knowledge it was not elaborated in the way we do it here. In fact, the role DERIVED was designed to cover any derivational relation that ...
... The special case is the relation DERIVED which was introduced into EWN to capture derivational relations existing in some EWN languages, however, according to our knowledge it was not elaborated in the way we do it here. In fact, the role DERIVED was designed to cover any derivational relation that ...

Tigris and Euphrastes - a comparison between human and machine
... naked idea N1.give. This, however is analysable farther to N2.cause N2.pertain with suitable syntactic bonding, where cause and pertain are catchwords for the corresponding general concepts. It is possible to analyse further, but in the present context it is doubtful if this would serve a useful pur ...
... naked idea N1.give. This, however is analysable farther to N2.cause N2.pertain with suitable syntactic bonding, where cause and pertain are catchwords for the corresponding general concepts. It is possible to analyse further, but in the present context it is doubtful if this would serve a useful pur ...

58 COHESION IN POEM A Case Study in `Marks` and `the way and
... This study is a linguistic analysis on literary works, especially of poem. It is mainly based on the study of cohesion given by Halliday and Hasan (1976). The study intends to describe how the cohesion works in two poems ‘Marks’ and ‘the way and the way things are’ written respectively by Linda Past ...
... This study is a linguistic analysis on literary works, especially of poem. It is mainly based on the study of cohesion given by Halliday and Hasan (1976). The study intends to describe how the cohesion works in two poems ‘Marks’ and ‘the way and the way things are’ written respectively by Linda Past ...

Distributional semantics in linguistic and cognitive research
... linguistic contexts representative of the distributional and combinatorial behavior of a given word, we may find evidence about (some of) its semantic properties. A key issue is how this functional dependence between word distributions and semantic constitution is made explicit and explained, i.e. w ...
... linguistic contexts representative of the distributional and combinatorial behavior of a given word, we may find evidence about (some of) its semantic properties. A key issue is how this functional dependence between word distributions and semantic constitution is made explicit and explained, i.e. w ...

Abstract - NYU Computer Science
... “Getting to know my significant other’s parents,” “Cooking dinner for four,” “Cooking pasta primavera,” “Chopping a zucchini,” “Cutting once through the zucchini”, and “With the right hand, grasping the knife by the handle, blade downward, and lowering it at about 1 foot per second through the cente ...
... “Getting to know my significant other’s parents,” “Cooking dinner for four,” “Cooking pasta primavera,” “Chopping a zucchini,” “Cutting once through the zucchini”, and “With the right hand, grasping the knife by the handle, blade downward, and lowering it at about 1 foot per second through the cente ...

code/API
... reads the dictionary in and parses through it, removing unimportant information and separating the key information about the word's characteristics, from the actual definitions. After reading in and generating the dictionary, the program gets an input sentence and begins to tag the words in it for t ...
... reads the dictionary in and parses through it, removing unimportant information and separating the key information about the word's characteristics, from the actual definitions. After reading in and generating the dictionary, the program gets an input sentence and begins to tag the words in it for t ...

Linguistic Ambiguity in Language-based Jokes
... The ambiguity that distinguishes verbal from referential jokes “can reside in a range of components in the linguistic system, such as the syntax, the lexicon, or the phonology” (Lew 1996, p. 126). Pepicello and Green adhere to this belief and analyze riddles on the basis of “language as a system con ...
... The ambiguity that distinguishes verbal from referential jokes “can reside in a range of components in the linguistic system, such as the syntax, the lexicon, or the phonology” (Lew 1996, p. 126). Pepicello and Green adhere to this belief and analyze riddles on the basis of “language as a system con ...

English Success Standards - Truth in American Education
... The spoken word consists of a sequence of elementary sounds (phonemes). A phoneme is defined as the minimal change in sound that will change one word into another word: sit-> bit; top ->shop (see Figure 1, Intervention Strategies for Phonemic Awareness). Phonemic awareness is the ability to recogniz ...
... The spoken word consists of a sequence of elementary sounds (phonemes). A phoneme is defined as the minimal change in sound that will change one word into another word: sit-> bit; top ->shop (see Figure 1, Intervention Strategies for Phonemic Awareness). Phonemic awareness is the ability to recogniz ...

File - Tennessee Against Common Core
... The spoken word consists of a sequence of elementary sounds (phonemes). A phoneme is defined as the minimal change in sound that will change one word into another word: sit-> bit; top ->shop (see Figure 1, Intervention Strategies for Phonemic Awareness). Phonemic awareness is the ability to recogniz ...
... The spoken word consists of a sequence of elementary sounds (phonemes). A phoneme is defined as the minimal change in sound that will change one word into another word: sit-> bit; top ->shop (see Figure 1, Intervention Strategies for Phonemic Awareness). Phonemic awareness is the ability to recogniz ...

automatic prosodic sentence analysis, accentuation and phrasing
... prosodic interpretation phrasing, accentuation ...
... prosodic interpretation phrasing, accentuation ...

A brain network for integration of tone and suffix Roll, Mikael
... posters - core issues in morphological processing research. There will be two additional foci this year. The first is on the linguistic side of things, with a keynote address given by Mark Aronoff, one of the most prominent morphologists in the world, and a symposium on the processing of morphosynta ...
... posters - core issues in morphological processing research. There will be two additional foci this year. The first is on the linguistic side of things, with a keynote address given by Mark Aronoff, one of the most prominent morphologists in the world, and a symposium on the processing of morphosynta ...

Ontologies and Knowledge Representation Outline - (CUI)
... Hence, the web is not machine processable. – impossible to write a program to find a German car for sale at a price lower than 1000 € ...
... Hence, the web is not machine processable. – impossible to write a program to find a German car for sale at a price lower than 1000 € ...


Morphemes Introduction Morphemes are what make up words. Often
... Second :This set consists largely of the functional words in the language such as conjunctions , prepositions and pronouns this is called ( functional morphemes) eg)and , but , on , near , the , that , it …… ...
... Second :This set consists largely of the functional words in the language such as conjunctions , prepositions and pronouns this is called ( functional morphemes) eg)and , but , on , near , the , that , it …… ...

Lexical Rules for Deverbal Adjectives
... zone, instead of variables w h i c h are b o u n d to syntactic elements, the m e a n i n g s o f the e l e m e n t s re2 Similar values are assigned to any scale based on a property concept. It should be noted, however, that numerical values like these correspond to the feature of gradability, whic ...
... zone, instead of variables w h i c h are b o u n d to syntactic elements, the m e a n i n g s o f the e l e m e n t s re2 Similar values are assigned to any scale based on a property concept. It should be noted, however, that numerical values like these correspond to the feature of gradability, whic ...

Automatic Labeling of Semantic Roles
... Defining semantic roles at this intermediate frame level helps avoid some of the well-known difficulties of defining a unique small set of universal, abstract thematic roles, while also allowing some generalization across the roles of different verbs, nouns, and adjectives, each of which adds additi ...
... Defining semantic roles at this intermediate frame level helps avoid some of the well-known difficulties of defining a unique small set of universal, abstract thematic roles, while also allowing some generalization across the roles of different verbs, nouns, and adjectives, each of which adds additi ...

Structured development of problem solving methods
... generic search paradigm. The characterization of problem solving methods as taskspecific reasoning patterns has also been undermined by much recent research. For example, [53] reports on a simple assignment task that was used as a common benchmark to compare and contrast alternative methodologies an ...
... generic search paradigm. The characterization of problem solving methods as taskspecific reasoning patterns has also been undermined by much recent research. For example, [53] reports on a simple assignment task that was used as a common benchmark to compare and contrast alternative methodologies an ...

the equivalence and shift in the english translation of indonesian
... the various layers of the translation. All that appears as new with respect to the original or fails to appear where it might have been expected may be interpreted as a shift. So, when the form in source language has a new form or different form from target language, it is called shift. According t ...
... the various layers of the translation. All that appears as new with respect to the original or fails to appear where it might have been expected may be interpreted as a shift. So, when the form in source language has a new form or different form from target language, it is called shift. According t ...
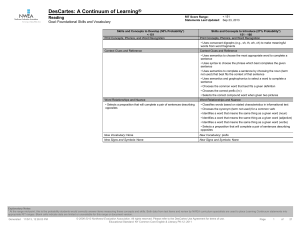
Foundational Skills and Vocabulary
... • Infers the general meaning of a noun (term not used) based on the real life/familiar context given in a short paragraph • Infers the general meaning of a noun based on the real life/familiar context given in a sentence • Infers the general meaning of a verb (term not used) based on the real life/f ...
... • Infers the general meaning of a noun (term not used) based on the real life/familiar context given in a short paragraph • Infers the general meaning of a noun based on the real life/familiar context given in a sentence • Infers the general meaning of a verb (term not used) based on the real life/f ...