
What is Linguistic Redundancy?
... Although in this instance the tag “didn’t you,” its associated intonation pattern and the subjectpredicate inversion in the tag itself make the sentence interrogative. However, occasionally, you may hear: “You went to the theater, did ye.” In this case the tag is slightly less informative. Not only ...
... Although in this instance the tag “didn’t you,” its associated intonation pattern and the subjectpredicate inversion in the tag itself make the sentence interrogative. However, occasionally, you may hear: “You went to the theater, did ye.” In this case the tag is slightly less informative. Not only ...

Cornetto user documentation
... The Cornetto lexical resource for Dutch covers the most generic and central part of the language. Cornetto combines the structures of the Princeton Wordnet, some of the features from the FrameNet for English and the information on morphological, syntactic, semantic and combinatorial features of lexe ...
... The Cornetto lexical resource for Dutch covers the most generic and central part of the language. Cornetto combines the structures of the Princeton Wordnet, some of the features from the FrameNet for English and the information on morphological, syntactic, semantic and combinatorial features of lexe ...

Making Dictionaries
... original tables. It became obvious that one print table flexible enough to handle many options would be better than repeatedly customizing individual tables for individual users. Since many users of SHOEBOX were using their lexical database for both interlinearizing and building a dictionary, it als ...
... original tables. It became obvious that one print table flexible enough to handle many options would be better than repeatedly customizing individual tables for individual users. Since many users of SHOEBOX were using their lexical database for both interlinearizing and building a dictionary, it als ...

Document
... In dealing with the objectives of stylistics, certain pronouncements of adjacent disciplines such as theory of information, literature, psychology, logic and to some extent statistics must be touched upon. This is indispensable; for nowadays no science is entirely isolated from other domains of huma ...
... In dealing with the objectives of stylistics, certain pronouncements of adjacent disciplines such as theory of information, literature, psychology, logic and to some extent statistics must be touched upon. This is indispensable; for nowadays no science is entirely isolated from other domains of huma ...

Robust French syntax analysis : reconciling statistical methods and
... on him (twice!) in Amsterdam. His guidance throughout my studies, and especially after I started writing my dissertation, has been priceless. He gave me the freedom to explore to my heart’s content, all the while gently nudging me in the right direction. In hindsight I find that his advice has always ...
... on him (twice!) in Amsterdam. His guidance throughout my studies, and especially after I started writing my dissertation, has been priceless. He gave me the freedom to explore to my heart’s content, all the while gently nudging me in the right direction. In hindsight I find that his advice has always ...

Inheritance and Complementation: A Case Study of Easy Adjectives
... and Wasow 1985 and Flickinger 1987). In structured lexicons, word classes may stand in a relationship of inheritance to one another, in which case the properties of the bequeathing class accrue automatically to the inheriting class. Once we allow that a single class may be heir to more than one bequ ...
... and Wasow 1985 and Flickinger 1987). In structured lexicons, word classes may stand in a relationship of inheritance to one another, in which case the properties of the bequeathing class accrue automatically to the inheriting class. Once we allow that a single class may be heir to more than one bequ ...

Choosing a Spanish Part-of-Speech tagger for a lexically
... taggers is not a straightforward task. Differences in their tagsets, output formats and tokenisation processes have to be addressed. Prior to the PoS tagging process, the text has to be tokenised. As pointed out by Dridan and Oepen (2012), tokenisation is often regarded as a solved problem in NLP. H ...
... taggers is not a straightforward task. Differences in their tagsets, output formats and tokenisation processes have to be addressed. Prior to the PoS tagging process, the text has to be tokenised. As pointed out by Dridan and Oepen (2012), tokenisation is often regarded as a solved problem in NLP. H ...
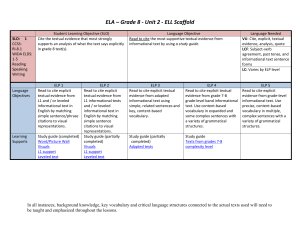
Word - State of New Jersey
... words and phrases as they are used in informational text within the grades 7-8 complexity level using some complex sentences with a variety of grammatical structures and content-based vocabulary. Online support of dictionaries, thesaurus, and sites such as: Wordle, Word Sift Idiom dictionaries ...
... words and phrases as they are used in informational text within the grades 7-8 complexity level using some complex sentences with a variety of grammatical structures and content-based vocabulary. Online support of dictionaries, thesaurus, and sites such as: Wordle, Word Sift Idiom dictionaries ...

Document
... The expressive form that a song takes is related to what the singer has learned: its form may be learned directly from an older family member, it may be heard in a ceremonial dance, it may come to an individual who is training or fasting, or it may come by visiting a particular place. In all of the ...
... The expressive form that a song takes is related to what the singer has learned: its form may be learned directly from an older family member, it may be heard in a ceremonial dance, it may come to an individual who is training or fasting, or it may come by visiting a particular place. In all of the ...

the nature and classification of idioms
... to tell someone where to get off, to bring the house down, to take it out on someone. The learner will have great difficulty here unless he has heard the idioms before. Even when they are used in context, it is not easy to detect the meaning exactly. To get off usually appears together with bus or b ...
... to tell someone where to get off, to bring the house down, to take it out on someone. The learner will have great difficulty here unless he has heard the idioms before. Even when they are used in context, it is not easy to detect the meaning exactly. To get off usually appears together with bus or b ...

The Bitaxonomy algorithm - LIA - Laboratory of Advanced Research
... • Resolving such ambiguities by means of computational models and algorithms • For instance: – part-of-speech tagging resolves the ambiguity between duck as verb and noun – word sense disambiguation decides whether make means create or cook – probabilistic parsing decides whether her and duck are pa ...
... • Resolving such ambiguities by means of computational models and algorithms • For instance: – part-of-speech tagging resolves the ambiguity between duck as verb and noun – word sense disambiguation decides whether make means create or cook – probabilistic parsing decides whether her and duck are pa ...

v. nominalization as a cohesive device in
... sophisticated means of transferring information. In order to make it comprehendible (both spoken and written form) the producer should use clear and coherent text. Hence, to understand what makes the text consistent it is expedient to discuss the concept of the text itself. The concept of a text has ...
... sophisticated means of transferring information. In order to make it comprehendible (both spoken and written form) the producer should use clear and coherent text. Hence, to understand what makes the text consistent it is expedient to discuss the concept of the text itself. The concept of a text has ...

Putting Pieces Together: Combining FrameNet, VerbNet
... and shortcomings. In this work, we aim to combine their strengths, and eliminate their shortcomings, by creating a unified knowledge-base that links them all together, allowing them to benefit from one another. FrameNet provides a good generalization across predicates using frames and semantic roles. ...
... and shortcomings. In this work, we aim to combine their strengths, and eliminate their shortcomings, by creating a unified knowledge-base that links them all together, allowing them to benefit from one another. FrameNet provides a good generalization across predicates using frames and semantic roles. ...

Spoken Language Translator: Phase Two Report (Draft)
... Spoken Language Translator (SLT) is a project whose long-term goal is the construction of practically useful systems capable of translating human speech from one language into another. The current SLT prototype, described in detail in this report, is capable of speech-to-speech translation between E ...
... Spoken Language Translator (SLT) is a project whose long-term goal is the construction of practically useful systems capable of translating human speech from one language into another. The current SLT prototype, described in detail in this report, is capable of speech-to-speech translation between E ...

Document
... a multipurpose enclosed motor vehicle having a boxlike shape, rear or side doors, and side panels often with windows ...
... a multipurpose enclosed motor vehicle having a boxlike shape, rear or side doors, and side panels often with windows ...

Collocation
... and some special forms of the verb to be). Still, these scarce forms are dynamically correlated with the other, grammatically non-agreed forms. C.f.: he went – he goes, I went – I go. But apart from the grammatical forms of agreement, the predicative person is directly reflected upon the verb-predi ...
... and some special forms of the verb to be). Still, these scarce forms are dynamically correlated with the other, grammatically non-agreed forms. C.f.: he went – he goes, I went – I go. But apart from the grammatical forms of agreement, the predicative person is directly reflected upon the verb-predi ...

Recognising Affect in Text using Pointwise
... Research in the area of affect recognition in text is currently rooted in the exploitation of human-supplied knowledge of emotion. Since the nature of affect is inherently ambiguous (both in terms of the affect classes and the natural language words that represent them), some researchers have electe ...
... Research in the area of affect recognition in text is currently rooted in the exploitation of human-supplied knowledge of emotion. Since the nature of affect is inherently ambiguous (both in terms of the affect classes and the natural language words that represent them), some researchers have electe ...

Overview of the Different Complementation Patterns and
... popular. This is beneficial especially for non-native speakers since they very often lack the intuition native speakers have when it comes to choosing the right complementation pattern to express a certain sense of a verb. Language undergoes constant change. It can grow in the number of its words as ...
... popular. This is beneficial especially for non-native speakers since they very often lack the intuition native speakers have when it comes to choosing the right complementation pattern to express a certain sense of a verb. Language undergoes constant change. It can grow in the number of its words as ...

Automatic grouping of morphologically related collocations
... the point of view of identifying collocations in texts. In most of this work, the identification, the linguistic description, the translation and the lexicographic or terminographic presentation of single collocations is in focus. In this article, we make an attempt at going one step further. We do ...
... the point of view of identifying collocations in texts. In most of this work, the identification, the linguistic description, the translation and the lexicographic or terminographic presentation of single collocations is in focus. In this article, we make an attempt at going one step further. We do ...

Alpha-Phonics Video
... Y stands for yuh, and if you put yuh in front of am and ap, you get yam and yap. Z stands for zuh, and if you put zuh in front of ag, you get zag . Thus , by the end of Lesson 9, you've learned the short a vowel sound, and the sounds of consonant letters b, c, d, f, g, h, j, I, m, n, p, r, s, t, v, ...
... Y stands for yuh, and if you put yuh in front of am and ap, you get yam and yap. Z stands for zuh, and if you put zuh in front of ag, you get zag . Thus , by the end of Lesson 9, you've learned the short a vowel sound, and the sounds of consonant letters b, c, d, f, g, h, j, I, m, n, p, r, s, t, v, ...

Chaucer`s Impact on the English Language: A Detailed Study
... focuses on the fact that at a certain moment in history scholars simply selected Chaucer as the originator of English poetry, so that later scholars were greatly affected by this assumption rather than motivated to look at the language themselves. To show this statement he examined Chaucer’s vocabul ...
... focuses on the fact that at a certain moment in history scholars simply selected Chaucer as the originator of English poetry, so that later scholars were greatly affected by this assumption rather than motivated to look at the language themselves. To show this statement he examined Chaucer’s vocabul ...

On Sinn and Bedeutung - University of Roehampton
... Staff and students of the University of Roehampton are reminded that copyright subsists in this extract and the work from which it was taken. This Digital Copy has been made by permission of the rightsholder which allows you to: * access and download a copy; * print out a copy; Please note that this ...
... Staff and students of the University of Roehampton are reminded that copyright subsists in this extract and the work from which it was taken. This Digital Copy has been made by permission of the rightsholder which allows you to: * access and download a copy; * print out a copy; Please note that this ...

Parsing English with a Link Grammar - Link home page
... and irregular verbs (wanted, go, denied, etc.), different types of nouns (mass nouns, those that take to-phrases, etc.), past- or present-participles in noun phrases, commas, a variety of adjective types, prepositions, adverbs, relative clauses, possessives, and many other things. We have also writt ...
... and irregular verbs (wanted, go, denied, etc.), different types of nouns (mass nouns, those that take to-phrases, etc.), past- or present-participles in noun phrases, commas, a variety of adjective types, prepositions, adverbs, relative clauses, possessives, and many other things. We have also writt ...

Towards a Rich Dependency Annotation of Spanish Corpora
... dependency structures such as SSyntS: A. Manually, from the scratch, i.e., starting from a raw corpus. This option would guarantee a high quality annotation (provided that the annotators are adequately trained and high degree of mutual agreement between the annotators is ensured), but is extremely c ...
... dependency structures such as SSyntS: A. Manually, from the scratch, i.e., starting from a raw corpus. This option would guarantee a high quality annotation (provided that the annotators are adequately trained and high degree of mutual agreement between the annotators is ensured), but is extremely c ...

Optimizing Grammars for Minimum Dependency Length
... first present a linear-time algorithm for finding the ordering of a single dependency tree with shortest total dependency length. Then, given that word order must also be determined by grammatical relations, we turn to the problem of specifying a grammar in terms of constraints over such relations. ...
... first present a linear-time algorithm for finding the ordering of a single dependency tree with shortest total dependency length. Then, given that word order must also be determined by grammatical relations, we turn to the problem of specifying a grammar in terms of constraints over such relations. ...