
C H A P T E R I The ways in which new words are formed, and the
... The most influential scholar concerned with the new linguistics was Ferdinand de Saussure, who emphasized the distinction between external linguistics – the study of the effects on a language of the history and culture of its speakers, and internal linguistics – the study of its system and rules. La ...
... The most influential scholar concerned with the new linguistics was Ferdinand de Saussure, who emphasized the distinction between external linguistics – the study of the effects on a language of the history and culture of its speakers, and internal linguistics – the study of its system and rules. La ...

toward memory-based reasoning - Computer Science, Columbia
... Memory-Based Reasoning in More Detail Although the basic idea of memory-based reasoning is simple, its implementation is somewhat more complex: We must separate important features from unimportant ones; moreover, what is important is usually context-sensitive. One cannot assign a single weight to ea ...
... Memory-Based Reasoning in More Detail Although the basic idea of memory-based reasoning is simple, its implementation is somewhat more complex: We must separate important features from unimportant ones; moreover, what is important is usually context-sensitive. One cannot assign a single weight to ea ...

1. Linguistic processing
... The main task of the semantic analysis or, to be more exact, the kind of semantic analysis described below (which can become deeper in case of properly composed knowledge base of the domain), is to reveal semantic meanings of syntaxemes and relations on the set of syntaxemes. In general a semantic r ...
... The main task of the semantic analysis or, to be more exact, the kind of semantic analysis described below (which can become deeper in case of properly composed knowledge base of the domain), is to reveal semantic meanings of syntaxemes and relations on the set of syntaxemes. In general a semantic r ...

A New Entity Salience Task with Millions of Training Examples
... names. An entity EA from the abstract aligns to an entity ED from the document if the syntactic head token of some mention in MEA matches the head token of some mention in MED . If EA aligns with more than one document entity, we align it with the document entity that appears earliest. In general, a ...
... names. An entity EA from the abstract aligns to an entity ED from the document if the syntactic head token of some mention in MEA matches the head token of some mention in MED . If EA aligns with more than one document entity, we align it with the document entity that appears earliest. In general, a ...

Morphological Tagging of Old Norse Texts and Its Use in Studying
... facilitating the use of these texts in research on syntactic variation and change. To create a manually annotated training corpus for Old Norse from scratch would have been a very time-consuming task. Thus, the possibility of using the bootstrapping method that we describe in this section was a key ...
... facilitating the use of these texts in research on syntactic variation and change. To create a manually annotated training corpus for Old Norse from scratch would have been a very time-consuming task. Thus, the possibility of using the bootstrapping method that we describe in this section was a key ...

The Cambridge Learner Corpus - Error Coding and Analysis
... University Press in collaboration with the University of Cambridge Local Examinations Syndicate (now Cambridge ESOL). It comprises English examination scripts, transcribed retaining all errors, written by learners of English with 86 different mother tongues. The scripts range across 8 EFL examinatio ...
... University Press in collaboration with the University of Cambridge Local Examinations Syndicate (now Cambridge ESOL). It comprises English examination scripts, transcribed retaining all errors, written by learners of English with 86 different mother tongues. The scripts range across 8 EFL examinatio ...

PDF hosted at the Radboud Repository of the Radboud University
... know what determines this process of integration, but it may be relevant to borrowability because the latter may change over time. There may be long term integration of items, and there may be the development of channels for integration, as suggested by Heath (1989). We should state right away that ...
... know what determines this process of integration, but it may be relevant to borrowability because the latter may change over time. There may be long term integration of items, and there may be the development of channels for integration, as suggested by Heath (1989). We should state right away that ...

ENLP Lecture 11 Part-of-speech tagging and HMMs
... – Someone wants to send us a sequence of tags: P (T ) – During encoding, “noise” converts each tag to a word: P (W |T ) – We try to decode the observed words back to the original tags. • In fact, decoding is a general term in NLP for inferring the hidden variables in a test instance (so, finding cor ...
... – Someone wants to send us a sequence of tags: P (T ) – During encoding, “noise” converts each tag to a word: P (W |T ) – We try to decode the observed words back to the original tags. • In fact, decoding is a general term in NLP for inferring the hidden variables in a test instance (so, finding cor ...

FNLP Lecture 8 Part-of-speech tagging and HMMs What is part of
... – Words we haven’t seen before (at all, or in this context) – Word-Tag pairs we haven’t seen before (e.g., if we verb a noun) ...
... – Words we haven’t seen before (at all, or in this context) – Word-Tag pairs we haven’t seen before (e.g., if we verb a noun) ...

Abstract - Res per nomen
... encyclopaedia of linguistics, and appears to have been reproduced without question. A comparable problem emerges when we consider Nesselhauf’s claim about want. It is true that the verb want takes many thousands of different types of complements. But Nesselhauf suggests there are no ‘arbitrary const ...
... encyclopaedia of linguistics, and appears to have been reproduced without question. A comparable problem emerges when we consider Nesselhauf’s claim about want. It is true that the verb want takes many thousands of different types of complements. But Nesselhauf suggests there are no ‘arbitrary const ...

Grounding the Ontology on the Semantic Interpretation
... a subconcept of physical-thing. It seems that the concept location is not as much a physicalobject as the concept, say, pencil. One finds the sentences “Peter threw/kicked the pencil” acceptable, but not “Peter threw/kicked Europe” unless one is using them in a figurative sense. That sense is what t ...
... a subconcept of physical-thing. It seems that the concept location is not as much a physicalobject as the concept, say, pencil. One finds the sentences “Peter threw/kicked the pencil” acceptable, but not “Peter threw/kicked Europe” unless one is using them in a figurative sense. That sense is what t ...
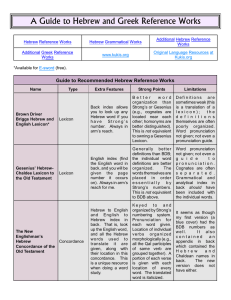
A Guide to Hebrew and Greek Reference Works
... Zodhiates has the KJV and above the words are Strong’s numbers along with a limited morphology (the gender, number and person are not given); the Greek text is off to the side. The latter work has the NKJV off to the side, with the Greek text in the middle of their Bible. Below the Greek text is a l ...
... Zodhiates has the KJV and above the words are Strong’s numbers along with a limited morphology (the gender, number and person are not given); the Greek text is off to the side. The latter work has the NKJV off to the side, with the Greek text in the middle of their Bible. Below the Greek text is a l ...

Using the Oxford Thesaurus of English
... the limitations of the LCD display and for other reasons; these modifications have been implemented under the provisions of the publisher(s). In some rare cases, misspellings and/or mistypings may be found; these are ‘errors’ that have been retained unmodified from the source Dictionaries. ...
... the limitations of the LCD display and for other reasons; these modifications have been implemented under the provisions of the publisher(s). In some rare cases, misspellings and/or mistypings may be found; these are ‘errors’ that have been retained unmodified from the source Dictionaries. ...

Punjabi Text Generation using Interlingua
... knowledge of the vocabulary of both source and target language, but also of their grammar i.e. the system of rules which specifies whether a sentence is well-formed in a particular language or not. Additionally, it requires some element of real world knowledge — knowledge of the nature of things out ...
... knowledge of the vocabulary of both source and target language, but also of their grammar i.e. the system of rules which specifies whether a sentence is well-formed in a particular language or not. Additionally, it requires some element of real world knowledge — knowledge of the nature of things out ...


Text Models
... Hidden Markov Model (HMM) • Model: sentences are generated by a probabilistic process • In particular, a Markov Chain whose states correspond to Parts-of-Speech • Transitions are probabilistic • In each state a word is outputted – The output word is again chosen probabilistically based on the state ...
... Hidden Markov Model (HMM) • Model: sentences are generated by a probabilistic process • In particular, a Markov Chain whose states correspond to Parts-of-Speech • Transitions are probabilistic • In each state a word is outputted – The output word is again chosen probabilistically based on the state ...

On problems of address in an automatic dictionary of
... and recourse to the letter IV is inevitable, if one cannot have the solution of eliminating engerbant as a very rare word and little used. A word like cohobant, which requires three letters for its classification, can be eliminated, for it represents practically nothing. On the whole, one can see th ...
... and recourse to the letter IV is inevitable, if one cannot have the solution of eliminating engerbant as a very rare word and little used. A word like cohobant, which requires three letters for its classification, can be eliminated, for it represents practically nothing. On the whole, one can see th ...

Lexical Relations and WordNet
... bachelor might be ANIMATE and HUMAN and MALE and ADULT and NEVER MARRIED. The representation of man might be ANIMATE and HUMAN and MALE and ADULT; because all the semantic components of man are included in the semantic components of bachelor, it can be inferred that bachelor man. In addition, ther ...
... bachelor might be ANIMATE and HUMAN and MALE and ADULT and NEVER MARRIED. The representation of man might be ANIMATE and HUMAN and MALE and ADULT; because all the semantic components of man are included in the semantic components of bachelor, it can be inferred that bachelor man. In addition, ther ...

How arbitrary is language? - Philosophical Transactions of the
... of the relationships between form and meaning for a large-scale representative vocabulary. The first aim of this study was to determine the properties of the form–meaning mapping for a broad and representative set of words in English. Previous studies have focused on a single measure of sound and of ...
... of the relationships between form and meaning for a large-scale representative vocabulary. The first aim of this study was to determine the properties of the form–meaning mapping for a broad and representative set of words in English. Previous studies have focused on a single measure of sound and of ...

Interpreting compound nouns with kernel methods
... modelling task is to define measures of similarity between data items, formalised as kernel functions. We consider the different sources of information that are useful for understanding compounds and proceed to define kernels that compute similarity between compounds in terms of these sources. In pa ...
... modelling task is to define measures of similarity between data items, formalised as kernel functions. We consider the different sources of information that are useful for understanding compounds and proceed to define kernels that compute similarity between compounds in terms of these sources. In pa ...

Worksheets with stimulus pictures
... to record which picture the subject points to throughout the experiment. Circle the number that corresponds to the location to which the subject pointed. The location of the correct answer (the matching picture) is indicated by the number that is in bold. If the subject would like to hear the audito ...
... to record which picture the subject points to throughout the experiment. Circle the number that corresponds to the location to which the subject pointed. The location of the correct answer (the matching picture) is indicated by the number that is in bold. If the subject would like to hear the audito ...

Part of speech Tagging for Tamil using SVMTool - CEN
... of the recent models have much larger numbers of word classes (POS Tags).Part-ofspeech tagging (POS tagging or POST), also called grammatical tagging, is the process of marking up the words in a text as corresponding to a particular part of speech, based on both its definition, as well as its contex ...
... of the recent models have much larger numbers of word classes (POS Tags).Part-ofspeech tagging (POS tagging or POST), also called grammatical tagging, is the process of marking up the words in a text as corresponding to a particular part of speech, based on both its definition, as well as its contex ...

Sentence diagram generation using dependency parsing
... paper, we use the system of diagramming formalized in (Kolln and Funk, 2002). ...
... paper, we use the system of diagramming formalized in (Kolln and Funk, 2002). ...

word classes and part-of-speech tagging
... freely. In this section we give a more complete definition of these and other classes. Traditionally the definition of parts-of-speech has been based on syntactic and morphological function; words that function similarly with respect to what can occur nearby (their “syntactic distributional properti ...
... freely. In this section we give a more complete definition of these and other classes. Traditionally the definition of parts-of-speech has been based on syntactic and morphological function; words that function similarly with respect to what can occur nearby (their “syntactic distributional properti ...

RET Tib dictionary
... publication in 1994 after the letter B. Beginning at the beginning of the alphabet and moving painstakingly through alphabetical order also has the disadvantage that editorial decisions taken lightly in the beginning can hamstring the project for decades to come. Despite the high level of results th ...
... publication in 1994 after the letter B. Beginning at the beginning of the alphabet and moving painstakingly through alphabetical order also has the disadvantage that editorial decisions taken lightly in the beginning can hamstring the project for decades to come. Despite the high level of results th ...