
Participant pack Module 7a Developing the personal English skills
... into smaller units of meaning. Suffixes and prefixes are morphemes. Morphology deals with the structure of words and how this affects meaning, e.g. take / takes; faith / faithful / unfaithful / unfaithfulness. The many modes through which we read, write, hear, etc. For example, song is a mode of hea ...
... into smaller units of meaning. Suffixes and prefixes are morphemes. Morphology deals with the structure of words and how this affects meaning, e.g. take / takes; faith / faithful / unfaithful / unfaithfulness. The many modes through which we read, write, hear, etc. For example, song is a mode of hea ...

Linguistic Creativity in the Language of Print Advertising
... similar and there is not a very wide price range. In order to sell the product, advertisers need to form a unique and distinctive picture of the product which will stand out from the rest. In other words, they have to create an effective couple of both the signifier and the signified. Therefore, we ...
... similar and there is not a very wide price range. In order to sell the product, advertisers need to form a unique and distinctive picture of the product which will stand out from the rest. In other words, they have to create an effective couple of both the signifier and the signified. Therefore, we ...

Phonaesthemes: A Corpus-Based Analysis Katya Otis () Eyal Sagi ()
... document-to-term analysis) with a real word bearing that phonaestheme. Participants are asked to read these sentences and then write a paraphrase of each. Preliminary analysis indicates that paraphrase typing latency in the presence of a congruent phonaestheme is significantly less than in the prese ...
... document-to-term analysis) with a real word bearing that phonaestheme. Participants are asked to read these sentences and then write a paraphrase of each. Preliminary analysis indicates that paraphrase typing latency in the presence of a congruent phonaestheme is significantly less than in the prese ...

Pre Test Excerpt
... phonaesthemes. Unlike previous work, our model can be used to directly test whether a cluster of words containing a phonaestheme is more semantically similar than would be expected by chance. While we successfully applied this test to discriminate between phonaesthemes and pseudophonaesthemes, at pr ...
... phonaesthemes. Unlike previous work, our model can be used to directly test whether a cluster of words containing a phonaestheme is more semantically similar than would be expected by chance. While we successfully applied this test to discriminate between phonaesthemes and pseudophonaesthemes, at pr ...


P88-1027 - ACL Anthology Reference Corpus
... Vax 8300 and a Vax 750. Total clock time required " was very little more than this, however, since almost all the parsing was done at night when the systems were otherwise idle. Table 1 compares the LSP's performance in the four part of speech categories. ...
... Vax 8300 and a Vax 750. Total clock time required " was very little more than this, however, since almost all the parsing was done at night when the systems were otherwise idle. Table 1 compares the LSP's performance in the four part of speech categories. ...

PowerPoint 프레젠테이션 - University at Buffalo
... time because of unwanted messages Content of Material - Some of these messages can contain offensive material such as graphic pornography ...
... time because of unwanted messages Content of Material - Some of these messages can contain offensive material such as graphic pornography ...
cross-lingual :
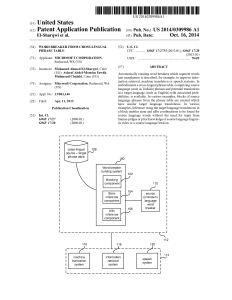
... [0002] Existing word breakers are often created through supervised learning where examples of words and their mor phemes are annotated by human judges. This makes word ...
... [0002] Existing word breakers are often created through supervised learning where examples of words and their mor phemes are annotated by human judges. This makes word ...

Mismatches in default inheritance
... exceptions. Presumably the linguists hold the facts in their minds as default patterns, but the facts are obviously independent of what linguists know about them. DI may or may not be a useful kind of logic in scientific work such as linguistic typology; and it may or may not be right to postulate d ...
... exceptions. Presumably the linguists hold the facts in their minds as default patterns, but the facts are obviously independent of what linguists know about them. DI may or may not be a useful kind of logic in scientific work such as linguistic typology; and it may or may not be right to postulate d ...

Towards Modeling False Memory with Computational Knowledge
... as a viable explanation for false memory in the DRM task. The semantic network used in this experiment was created manually from the words in the “needle” and “doctor” lists. For each list, the fifteen stimuli words are all connected to the lure, with additional connections created based on whether ...
... as a viable explanation for false memory in the DRM task. The semantic network used in this experiment was created manually from the words in the “needle” and “doctor” lists. For each list, the fifteen stimuli words are all connected to the lure, with additional connections created based on whether ...


JQ3616701679
... and machine translation issues about Arabic, such as morphology and Arabic script. [5] focuses on word agreement and ordering in a ruled based EnglishArabic machine translation. [6] investigates different methodologies to manage the problem of morphological and syntactic ambiguities in Arabic with a ...
... and machine translation issues about Arabic, such as morphology and Arabic script. [5] focuses on word agreement and ordering in a ruled based EnglishArabic machine translation. [6] investigates different methodologies to manage the problem of morphological and syntactic ambiguities in Arabic with a ...

Cryptic Crossword Clues - Association for Computational Linguistics
... points1 to each chunk: one specifying the relationships that can occur to the left, another those that can occur to the right, and the third specifying upward attachments. For example the chunk wild lionesses has, amongst many others, an extension point to the left indicating that it can attach as d ...
... points1 to each chunk: one specifying the relationships that can occur to the left, another those that can occur to the right, and the third specifying upward attachments. For example the chunk wild lionesses has, amongst many others, an extension point to the left indicating that it can attach as d ...

TEKS Glossary - Institute for Public School Initiatives
... text in which the majority of words (80%–90%) contain sound–symbol relationships that have already been taught Decodable texts are used to practice specific decoding skills and to apply phonics in early reading. decoding applying knowledge of letter–sound relationships in order to sound out a word I ...
... text in which the majority of words (80%–90%) contain sound–symbol relationships that have already been taught Decodable texts are used to practice specific decoding skills and to apply phonics in early reading. decoding applying knowledge of letter–sound relationships in order to sound out a word I ...

A Play on Words: Using Cognitive Computing as a
... representations and procedures to support particular human activities.” Indeed, the seeds of this concept have already been planted by IBM in their Cognitive Environments Laboratory where numerous smaller subsystems operate synergistically around Watson to provide support to human operators. (IBM, 2 ...
... representations and procedures to support particular human activities.” Indeed, the seeds of this concept have already been planted by IBM in their Cognitive Environments Laboratory where numerous smaller subsystems operate synergistically around Watson to provide support to human operators. (IBM, 2 ...

full text pdf
... representations and procedures to support particular human activities.” Indeed, the seeds of this concept have already been planted by IBM in their Cognitive Environments Laboratory where numerous smaller subsystems operate synergistically around Watson to provide support to human operators. (IBM, 2 ...
... representations and procedures to support particular human activities.” Indeed, the seeds of this concept have already been planted by IBM in their Cognitive Environments Laboratory where numerous smaller subsystems operate synergistically around Watson to provide support to human operators. (IBM, 2 ...

Biblical Hebrew E-Magazine - Ancient Hebrew Research Center
... Question of the Month – Best Books 2? By: Jeff A. Benner Q: What are the best books AHRC recommends for learning the Hebrew language? A: In the last issue we provided our book recommendations for learning the Hebraic perspective (thought) of the Hebrew Bible. Now we will provide our recommendations ...
... Question of the Month – Best Books 2? By: Jeff A. Benner Q: What are the best books AHRC recommends for learning the Hebrew language? A: In the last issue we provided our book recommendations for learning the Hebraic perspective (thought) of the Hebrew Bible. Now we will provide our recommendations ...

Expected English/VFA Time Management of Homework/Study
... a. Read the definitions of each word. Make flashcards and memorize the meanings. This can be done by hand or using Quizlet. b. After definitions are memorized, you will practice applying your new knowledge by completing the rest of the lesson components. Be sure to work through each section of the l ...
... a. Read the definitions of each word. Make flashcards and memorize the meanings. This can be done by hand or using Quizlet. b. After definitions are memorized, you will practice applying your new knowledge by completing the rest of the lesson components. Be sure to work through each section of the l ...

Discovering Light Verb Constructions and their Translations from
... the single words it contains. Melamed (1997) describes one of the earliest attempts to extract MWEs from parallel corpora. The method is based on lexical alignment and mutual information. Statistical lexical alignment can provide straightforward MWE candidates, which can be further filtered using PO ...
... the single words it contains. Melamed (1997) describes one of the earliest attempts to extract MWEs from parallel corpora. The method is based on lexical alignment and mutual information. Statistical lexical alignment can provide straightforward MWE candidates, which can be further filtered using PO ...

EVALUATING PART-OF-SPEECH TAGGING AND PARSING On the
... phrase structure trees. Information about the c-structure category of each word as well as its f-structure is stored in the lexicon. The grammar rules encode constraints between the f-structure of any non-terminal node and the f-structures of its daughter nodes. The functional structure must validat ...
... phrase structure trees. Information about the c-structure category of each word as well as its f-structure is stored in the lexicon. The grammar rules encode constraints between the f-structure of any non-terminal node and the f-structures of its daughter nodes. The functional structure must validat ...

Using part-of-speech information in word alignment
... 1990, p. 154). Another EM-based algorithm Word_align (Ido, Church and Gale 1993) with character alignment as the starting point, was shown to align 60.5% percent of the words correctly, and in 84% of the cases the offset from the correct alignment is at most 3. Gale and Church (1990) proposed using ...
... 1990, p. 154). Another EM-based algorithm Word_align (Ido, Church and Gale 1993) with character alignment as the starting point, was shown to align 60.5% percent of the words correctly, and in 84% of the cases the offset from the correct alignment is at most 3. Gale and Church (1990) proposed using ...

corpus-based cognitive semantics a contrastive
... correlation of collocates in different clause roles, he arrives at ‘Behavioral Profiles’ or the totality of complementation patterns of a word that determines its semantics (Hanks 1996: 77). The full capacity of this approach is not exploited, however, and we will return to this topic in Section 1.2 ...
... correlation of collocates in different clause roles, he arrives at ‘Behavioral Profiles’ or the totality of complementation patterns of a word that determines its semantics (Hanks 1996: 77). The full capacity of this approach is not exploited, however, and we will return to this topic in Section 1.2 ...

View/Open - Queen Mary University of London
... Bauer (2001: 126) makes a further distinction between strong and weak constraints. A strong constraint describes a process in which an affix attaches only to a particular type of base, such as the suffix -ness in English, which attaches only to adjectives (e.g. happi-ness, white-ness). Strong constr ...
... Bauer (2001: 126) makes a further distinction between strong and weak constraints. A strong constraint describes a process in which an affix attaches only to a particular type of base, such as the suffix -ness in English, which attaches only to adjectives (e.g. happi-ness, white-ness). Strong constr ...

Grammars, Words, and Embodied Meanings: On the Uses and
... This paper is about two Germanic words, one German (“so”), one American English (“like”). Each, in one of its usage variants, makes “nonverbal behavior” salient, serving as preface or relevance marker for some unit of body behavior. Both words also give these nonverbal behaviors grammatical status, ...
... This paper is about two Germanic words, one German (“so”), one American English (“like”). Each, in one of its usage variants, makes “nonverbal behavior” salient, serving as preface or relevance marker for some unit of body behavior. Both words also give these nonverbal behaviors grammatical status, ...
