
Pre-course PG English Subject Knowledge Test
... required to demonstrate by the end of your training. We ask you to carry out an audit to analyse your initial strengths and areas for development. We will then use this to plan subject knowledge sessions that address the needs identified. The audit will be given to you during your ‘keeping in touch’ ...
... required to demonstrate by the end of your training. We ask you to carry out an audit to analyse your initial strengths and areas for development. We will then use this to plan subject knowledge sessions that address the needs identified. The audit will be given to you during your ‘keeping in touch’ ...

Morpho-syntactic Lexical Generalization for CCG
... variations in morphology, syntax, and semantics across word classes. The grammar uses domain-independent facts about the English language to restrict the number of incorrect parses that must be considered, thereby enabling effective learning from less data. Experiments in benchmark domains match pre ...
... variations in morphology, syntax, and semantics across word classes. The grammar uses domain-independent facts about the English language to restrict the number of incorrect parses that must be considered, thereby enabling effective learning from less data. Experiments in benchmark domains match pre ...

The Australian Curriculum English
... • ‘Did I fall asleep and miss my dinner?’ (joining clauses) • subordinating conjunctions introduce certain kinds of dependent clauses; • ‘that’ simply marks declaratives, for example ‘I know that he is ill’ • ‘whether’ (or ‘if’ in the sense in which it is equivalent to whether) marks interrogatives, ...
... • ‘Did I fall asleep and miss my dinner?’ (joining clauses) • subordinating conjunctions introduce certain kinds of dependent clauses; • ‘that’ simply marks declaratives, for example ‘I know that he is ill’ • ‘whether’ (or ‘if’ in the sense in which it is equivalent to whether) marks interrogatives, ...

PPT
... Heights) that outperformed previous knowledgebased approaches • Use of probabilistic finite state machines to model word pronunciations • Make use of hill-climbing training algorithms to fit model parameters to actual speech data November 2005 ...
... Heights) that outperformed previous knowledgebased approaches • Use of probabilistic finite state machines to model word pronunciations • Make use of hill-climbing training algorithms to fit model parameters to actual speech data November 2005 ...

part-of-speech tagging using a variable memory markov model
... the EM (Dempster et al., 1977) algorithm, which guarantees convergence to.a local minimum (Wu, 1983). The advantage of an HMM is that it can be trained using untagged text. On the other hand, the training procedure is time consuming, and a fixed model (topology) is assumed. Another disadvantage is d ...
... the EM (Dempster et al., 1977) algorithm, which guarantees convergence to.a local minimum (Wu, 1983). The advantage of an HMM is that it can be trained using untagged text. On the other hand, the training procedure is time consuming, and a fixed model (topology) is assumed. Another disadvantage is d ...

Languages in Contrast Title Semantic niches and analogy in word
... comparisons of word formation processes. The overall impression that the formal part of word formation does not lend itself to comparison seems too pessimistic to me, but I agree that semantics usually is the more promising starting point for contrastive analyses. The question I want to raise is abo ...
... comparisons of word formation processes. The overall impression that the formal part of word formation does not lend itself to comparison seems too pessimistic to me, but I agree that semantics usually is the more promising starting point for contrastive analyses. The question I want to raise is abo ...

Lexicalising a robust parser grammar using the WWW
... However, the correct handling of attachment ambiguities, especially PP-attachment, is still an issue. The use of traditional subcategorisation lexicons is not of much help. Large-scale lexical subcategorisation information for verbs, nouns and adjectives is available for few languages. When availabl ...
... However, the correct handling of attachment ambiguities, especially PP-attachment, is still an issue. The use of traditional subcategorisation lexicons is not of much help. Large-scale lexical subcategorisation information for verbs, nouns and adjectives is available for few languages. When availabl ...

Prefixes and Suffixes
... e.g. ‘co-exist’ means to exist together dis means away, apart, between, utterly (when used with a negative word) and not. e.g. 'disarm' means to remove or take weapons away inter means among, between or together e.g. 'intermission' is the short period of time between parts in a performance or a film ...
... e.g. ‘co-exist’ means to exist together dis means away, apart, between, utterly (when used with a negative word) and not. e.g. 'disarm' means to remove or take weapons away inter means among, between or together e.g. 'intermission' is the short period of time between parts in a performance or a film ...

Part-of-speech Tagging Using A Variable Memory Markov Model
... stage we can transform the tree into a variable memory Markov process. The key idea is to iteratively build a prediction tree whose probability measure equals the empirical probability measure calculated from the sample. We start with a tree consisting of a single node and add nodes which we have r ...
... stage we can transform the tree into a variable memory Markov process. The key idea is to iteratively build a prediction tree whose probability measure equals the empirical probability measure calculated from the sample. We start with a tree consisting of a single node and add nodes which we have r ...

grade 6 - Stanhope School
... language arts skills as well as the other curricula in which those skills should be implemented. It would be counterproductive to ignore the expertise and competence of the individual classroom teachers. Nevertheless, everyone benefits when instruction is codified, thereby ensuring continuity, elimi ...
... language arts skills as well as the other curricula in which those skills should be implemented. It would be counterproductive to ignore the expertise and competence of the individual classroom teachers. Nevertheless, everyone benefits when instruction is codified, thereby ensuring continuity, elimi ...

restarting automata: motivations and applications
... Among the topical problems of current corpus linguistics (i.e. the branch of linguistics dealing with large bodies of running texts - so called corpora) is the resolution of morphological ambiguity of words in a text corpus - either on the level of Part-of-Speech (PoS) of a word (e.g., the German wo ...
... Among the topical problems of current corpus linguistics (i.e. the branch of linguistics dealing with large bodies of running texts - so called corpora) is the resolution of morphological ambiguity of words in a text corpus - either on the level of Part-of-Speech (PoS) of a word (e.g., the German wo ...

ppt
... Getting Around the Clever Strategies Using indirect methods like the preferential looking paradigm, we can test children’s comprehension of multiword combinations even when they can only produce one word utterances themselves Hirsh-Pasek & Golinkoff (1991): 13- to 15-month-olds can comprehend impro ...
... Getting Around the Clever Strategies Using indirect methods like the preferential looking paradigm, we can test children’s comprehension of multiword combinations even when they can only produce one word utterances themselves Hirsh-Pasek & Golinkoff (1991): 13- to 15-month-olds can comprehend impro ...

Assignment 1: Manual Direct Translation
... implemented one) seems to be quite accurate and looks like English. It is far away though, from the full-fledged style in the example translation. The quality, I would say is not too bad for being a very simple MT-implementation, but especially the last part of the sentence sounds a bit weird in Eng ...
... implemented one) seems to be quite accurate and looks like English. It is far away though, from the full-fledged style in the example translation. The quality, I would say is not too bad for being a very simple MT-implementation, but especially the last part of the sentence sounds a bit weird in Eng ...

large lexicons for natural language processing
... described in, eg., Tompa 1986); on the other hand a method of access was clearly required, which was flexible enough to support a range of applications intending to make use of the LDOCE tape. The requirement for having the dictionary entries in a form convenient for symbolic manipulation from withi ...
... described in, eg., Tompa 1986); on the other hand a method of access was clearly required, which was flexible enough to support a range of applications intending to make use of the LDOCE tape. The requirement for having the dictionary entries in a form convenient for symbolic manipulation from withi ...

Derivational Morphology in French - Journal of Language Sciences
... than one morpheme, derivational morphology studies the shapes of bound morphemes and free morphemes, their different types and semantic coverage of these contextual types. Each one of a derivation’s morphemes, whether basis or affix can have different shapes. Through observing these factors, it can ...
... than one morpheme, derivational morphology studies the shapes of bound morphemes and free morphemes, their different types and semantic coverage of these contextual types. Each one of a derivation’s morphemes, whether basis or affix can have different shapes. Through observing these factors, it can ...

Part 3 Word Formation I We have discussed the historical, cultural
... compounding involve different wordforming elements affixes and root or stem. Indeed, some people use root or stem interchangeably. In this book, these two terms are used differently. A root is the basic form of a word which cannot be further analysed without total loss of identity. As mentioned ...
... compounding involve different wordforming elements affixes and root or stem. Indeed, some people use root or stem interchangeably. In this book, these two terms are used differently. A root is the basic form of a word which cannot be further analysed without total loss of identity. As mentioned ...

1. The word as the basic unit of the language. The size-of
... Affixes are bound morphemes. They can’t function in the sentence alone. But: ladd|like, eat|able.(there are exist semi-sufficsis. –like,–able can be both suffices and independent words.) The two aspects of the word analysis: on the morphemic and derivational levels. The morphemic structure of the w ...
... Affixes are bound morphemes. They can’t function in the sentence alone. But: ladd|like, eat|able.(there are exist semi-sufficsis. –like,–able can be both suffices and independent words.) The two aspects of the word analysis: on the morphemic and derivational levels. The morphemic structure of the w ...

Matching Ottoman Words: An image retrieval approach to historical
... We should note that better methods could be applied for preprocessing, but our focus is on representation of words after segmentation, and therefore in this stage we choose the simplest methods with the knowledge that better segmentation would result in better retrieval performance. We should also m ...
... We should note that better methods could be applied for preprocessing, but our focus is on representation of words after segmentation, and therefore in this stage we choose the simplest methods with the knowledge that better segmentation would result in better retrieval performance. We should also m ...

WHAT IS LANGUAGE - Erciyes University
... Suppose you didn’t know English and were a linguist from the planet Zorx wishing to analyze the language. ...
... Suppose you didn’t know English and were a linguist from the planet Zorx wishing to analyze the language. ...

Semantic constraints on lexical categories
... encountered in context. The point we want to stress is that the information provided by the text and the reader's (or listener's) knowledge of the world do not constrain the range of hypotheses enough to allow rapid learning. There will always be indefinitely many hypotheses logically consistent wit ...
... encountered in context. The point we want to stress is that the information provided by the text and the reader's (or listener's) knowledge of the world do not constrain the range of hypotheses enough to allow rapid learning. There will always be indefinitely many hypotheses logically consistent wit ...
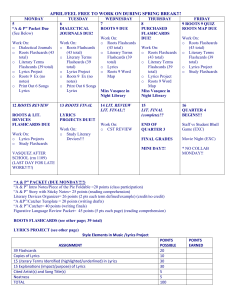
APRIL2010Reminders
... Paradox/antithesis: a statement that seems impossible because it contains two opposing ideas that are both true; reveals a kind of truth which at first seems contradictory. Two opposing ideas Parody: a piece of writing, music etc or an action that copies someone or something in an amusing way Parall ...
... Paradox/antithesis: a statement that seems impossible because it contains two opposing ideas that are both true; reveals a kind of truth which at first seems contradictory. Two opposing ideas Parody: a piece of writing, music etc or an action that copies someone or something in an amusing way Parall ...

Automatic Refinement of Linguistic Rules for Tagging
... - prevagreement (Features): there is number and/or gender agreement between the current and the previous word - prevmood (Mood): the previous word is a verb whose mood is Mood. - prevtense (Tense): the previous word is a verb whose tense is Tense. - curmood (Mood): in the verbal interpretation of th ...
... - prevagreement (Features): there is number and/or gender agreement between the current and the previous word - prevmood (Mood): the previous word is a verb whose mood is Mood. - prevtense (Tense): the previous word is a verb whose tense is Tense. - curmood (Mood): in the verbal interpretation of th ...


Graph-based Clustering of Synonym Senses for German Particle
... Assuming that clusters represent senses, we hypothesize that combining properties of individual synonym candidates with properties of the graphbased clusters of synonym candidates results in a ranking of the synonym candidates that overcomes both facets of the re-translation sense problem: Including ...
... Assuming that clusters represent senses, we hypothesize that combining properties of individual synonym candidates with properties of the graphbased clusters of synonym candidates results in a ranking of the synonym candidates that overcomes both facets of the re-translation sense problem: Including ...

Key Components Overview, part-of
... • prepositions: on, under, over, … • particles: up, down, on, off, … • determiners: a, an, the, … • pronouns: she, who, I, .. • conjunctions: and, but, or, … • auxiliary verbs: can, may should, … • numerals: one, two, three, third, … ...
... • prepositions: on, under, over, … • particles: up, down, on, off, … • determiners: a, an, the, … • pronouns: she, who, I, .. • conjunctions: and, but, or, … • auxiliary verbs: can, may should, … • numerals: one, two, three, third, … ...