
Towards a Universal Grammar for Natural Language Processing
... – In multilingual applications involving parsers, it is a major drawback if downstream components cannot assume uniform output representations from parsing, because we then require specialized interfaces for each language. – In cross-lingual learning and parser evaluation, inconsistent annotation st ...
... – In multilingual applications involving parsers, it is a major drawback if downstream components cannot assume uniform output representations from parsing, because we then require specialized interfaces for each language. – In cross-lingual learning and parser evaluation, inconsistent annotation st ...

linguistics
... Otto Jesperson : The Great Danish Philologist and Anglicist, published his first famous work “ Modern English Grammar on Historical Principles in 1909. The second, third, forth and fifth parts were also issued in succession. Jesperson died in 1943 when he was working at the sixth and seventh parts. ...
... Otto Jesperson : The Great Danish Philologist and Anglicist, published his first famous work “ Modern English Grammar on Historical Principles in 1909. The second, third, forth and fifth parts were also issued in succession. Jesperson died in 1943 when he was working at the sixth and seventh parts. ...

Here - Index of
... should all be about the same topic. The main sentence in a paragraph is called the topic sentence. Every new idea needs a new paragraph. Paragraphs help us because they break up the text into smaller, more readable parts. You should begin a new paragraph when there is: • A change of time • A change ...
... should all be about the same topic. The main sentence in a paragraph is called the topic sentence. Every new idea needs a new paragraph. Paragraphs help us because they break up the text into smaller, more readable parts. You should begin a new paragraph when there is: • A change of time • A change ...

Lecture guide
... and documents were essentially treated as a bag of words. For example, the the sentences “Microsoft bought Google” and “Google bought Microsoft” would be indistinguishable in these models. Clearly, these two sentences have different meanings, even though they have the same set of words. In order to ...
... and documents were essentially treated as a bag of words. For example, the the sentences “Microsoft bought Google” and “Google bought Microsoft” would be indistinguishable in these models. Clearly, these two sentences have different meanings, even though they have the same set of words. In order to ...
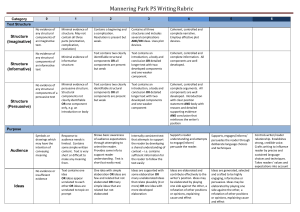
Tighes Hill Writing Rubric - Mannering Park PS Collaborative Staff
... focused on one idea or set of like ideas. At least one paragraph is logically constructed and contains a topic sentence and supporting detail paragraphs are correct but basic Most simple sentences are correct ...
... focused on one idea or set of like ideas. At least one paragraph is logically constructed and contains a topic sentence and supporting detail paragraphs are correct but basic Most simple sentences are correct ...

Interpreting aReading Scaled Scores for Instruction
... conclusions based on supporting details, identifying cause and effect relationships, comparing or contrasting characteristics of objects or concepts described in informational text, inferring the meaning of a nonsense word using context, inferring the author’s purpose, deleting a sentence that does ...
... conclusions based on supporting details, identifying cause and effect relationships, comparing or contrasting characteristics of objects or concepts described in informational text, inferring the meaning of a nonsense word using context, inferring the author’s purpose, deleting a sentence that does ...

Loci et Imagines Tiner 3
... translate in Latin word order, then give a second version, making minimum necessary changes for clear English. Going in order makes it possible to: a. note and appreciate nuances of meaning signaled by particular word orders; b. give correct sense when ambiguities arise; c. most important, read and ...
... translate in Latin word order, then give a second version, making minimum necessary changes for clear English. Going in order makes it possible to: a. note and appreciate nuances of meaning signaled by particular word orders; b. give correct sense when ambiguities arise; c. most important, read and ...

KS3 Skills Pack - Beacon Hill Community School
... should all be about the same topic. The main sentence in a paragraph is called the topic sentence. Every new idea needs a new paragraph. Paragraphs help us because they break up the text into smaller, more readable parts. You should begin a new paragraph when there is: • A change of time • A change ...
... should all be about the same topic. The main sentence in a paragraph is called the topic sentence. Every new idea needs a new paragraph. Paragraphs help us because they break up the text into smaller, more readable parts. You should begin a new paragraph when there is: • A change of time • A change ...

100 Pre-course PG English Subject Knowledge Test
... required to demonstrate by the end of your training. We ask you to carry out the audit printed below to analyse your initial strengths and areas for development. We will then use this to plan subject knowledge sessions that address the needs identified. Please bring it to your first English session. ...
... required to demonstrate by the end of your training. We ask you to carry out the audit printed below to analyse your initial strengths and areas for development. We will then use this to plan subject knowledge sessions that address the needs identified. Please bring it to your first English session. ...

Supersense Tagging of Unknown Nouns using Semantic Similarity
... ing directly underneath. Other alternative sets of supersenses can be created by an arbitrary cut through the W ORD N ET hierarchy near the top, or by using topics from a thesaurus such as Roget’s (Yarowsky, 1992). These topic distinctions are coarser-grained than W ORD N ET senses, which have been ...
... ing directly underneath. Other alternative sets of supersenses can be created by an arbitrary cut through the W ORD N ET hierarchy near the top, or by using topics from a thesaurus such as Roget’s (Yarowsky, 1992). These topic distinctions are coarser-grained than W ORD N ET senses, which have been ...

Chapter 5 Dictionaries
... ‘Paper’ here is intended to convey ‘intended for human readers’, as opposed to ‘electronic’ meaning ‘intended for use by computers’. Of course, it is possible for a paper dictionary to be stored on a computer like any other document, and our use of ‘paper’ here is not supposed to exclude this. If on ...
... ‘Paper’ here is intended to convey ‘intended for human readers’, as opposed to ‘electronic’ meaning ‘intended for use by computers’. Of course, it is possible for a paper dictionary to be stored on a computer like any other document, and our use of ‘paper’ here is not supposed to exclude this. If on ...

A PHONETIC, MORPHOLOGICAL AND SEMANTIC ANALYSIS OF
... Malay language has employed Arabic words in a new and different way It rendered thescwords nl!W 1,1_ based on the M:.I:.yc-onceptof parts of speech (Asmah 1983: 119-128) which is entirely different from thhe concept conceived by the Arabs (Sibawaihi 1966:12). No other Muslim language, with the excep ...
... Malay language has employed Arabic words in a new and different way It rendered thescwords nl!W 1,1_ based on the M:.I:.yc-onceptof parts of speech (Asmah 1983: 119-128) which is entirely different from thhe concept conceived by the Arabs (Sibawaihi 1966:12). No other Muslim language, with the excep ...

Unit 1 - Types of Words and Word-Formation
... incorporation of new members into it. b. Function(al) or grammatical morphemes are free morphemes which have little or no meaning on their own, but which show grammatical relationships in and between sentences. For instance, in a language, these morphemes are represented by prepositions, conjunction ...
... incorporation of new members into it. b. Function(al) or grammatical morphemes are free morphemes which have little or no meaning on their own, but which show grammatical relationships in and between sentences. For instance, in a language, these morphemes are represented by prepositions, conjunction ...

Making Sense of Nonce Sense
... referents are not denumerable. He can be used to refer to any of an indefinitely large number of males, past, present, and future, real and imaginary. These males cannot be listed, even in theory, since someone can always imagine another male and refer to it with he. Let me call this property nonden ...
... referents are not denumerable. He can be used to refer to any of an indefinitely large number of males, past, present, and future, real and imaginary. These males cannot be listed, even in theory, since someone can always imagine another male and refer to it with he. Let me call this property nonden ...

Year 1 Spelling Class: Rules Guidance Notes
... a letter or letters would be if the words couldn’t, it’s, I’ll were written in full (e.g. can’t – cannot). It’s means it is (e.g. It’s raining) or sometimes it has (e.g. It’s been raining), but it’s is never used for the possessive. ...
... a letter or letters would be if the words couldn’t, it’s, I’ll were written in full (e.g. can’t – cannot). It’s means it is (e.g. It’s raining) or sometimes it has (e.g. It’s been raining), but it’s is never used for the possessive. ...

Thinking About What We Are Asking Speakers to Do
... I suggest that this is true not just with regard to the kind of noun/verb the form is intended to represent, but also with respect to the circumstances under which the hypothetical inflected form could be part of the speaker’s language. Putting the concern another way, while virtually all studies, r ...
... I suggest that this is true not just with regard to the kind of noun/verb the form is intended to represent, but also with respect to the circumstances under which the hypothetical inflected form could be part of the speaker’s language. Putting the concern another way, while virtually all studies, r ...

slides - stony brook cs
... “The/DT planet/NN Jupiter/NNP and/CC its/PPS moons/NNS are/VBP in/IN effect/NN a/DT minisolar/JJ system/NN ,/, and/CC Jupiter/NNP itself/PRP is/VBZ often/RB called/VBN a/DT star/NN that/IN never/RB caught/VBN fire/NN ./.” ...
... “The/DT planet/NN Jupiter/NNP and/CC its/PPS moons/NNS are/VBP in/IN effect/NN a/DT minisolar/JJ system/NN ,/, and/CC Jupiter/NNP itself/PRP is/VBZ often/RB called/VBN a/DT star/NN that/IN never/RB caught/VBN fire/NN ./.” ...

Filling Knowledge Gaps in Human
... our meta-language framework when different bodies of online knowledge were used, and analyze the main factors that affect the performance. Test 1 was conducted on 11885 user tasks from the Tasks/Steps table of OMICS, consisted of three rounds. In the first round of Test 1, only the definitions of th ...
... our meta-language framework when different bodies of online knowledge were used, and analyze the main factors that affect the performance. Test 1 was conducted on 11885 user tasks from the Tasks/Steps table of OMICS, consisted of three rounds. In the first round of Test 1, only the definitions of th ...

Slide 1
... the ACCURAT project will significantly contribute not only to the theory of MT, but also to corpus linguistics, information extraction and natural language processing in general NooJ2011 Dubrovnik ...
... the ACCURAT project will significantly contribute not only to the theory of MT, but also to corpus linguistics, information extraction and natural language processing in general NooJ2011 Dubrovnik ...

CUSTOMER_CODE SMUDE DIVISION_CODE SMUDE
... b.Ambiguity: the word may be placed in such a position that it can give meaning to a varying range of elements within the sentence (1 mark) c.Brevity: the words may be omitted to make a sentence short (1 mark) d.Use Lists: Lists are useful tools to shorten the length of your sentences in technical w ...
... b.Ambiguity: the word may be placed in such a position that it can give meaning to a varying range of elements within the sentence (1 mark) c.Brevity: the words may be omitted to make a sentence short (1 mark) d.Use Lists: Lists are useful tools to shorten the length of your sentences in technical w ...

Appendix to “Measuring Central Bank
... The problem of the algorithmic tagging of text belongs to the linguistic subfield of natural language processing (NLP). Researchers in NLP have proposed several methods to identify POS and other higher-level grammatical constructs. The family of probabilistic taggers and parsers are a frequently emp ...
... The problem of the algorithmic tagging of text belongs to the linguistic subfield of natural language processing (NLP). Researchers in NLP have proposed several methods to identify POS and other higher-level grammatical constructs. The family of probabilistic taggers and parsers are a frequently emp ...

Developing Reading Vocabulary
... A. Word Analysis When we use the term word analysis, we mean that it is possible to take an unfamiliar word, figure out what a part or parts of the word mean, and come up with a definition. For example, let’s say you come across the following sentence: “He thought it might be a good idea to study de ...
... A. Word Analysis When we use the term word analysis, we mean that it is possible to take an unfamiliar word, figure out what a part or parts of the word mean, and come up with a definition. For example, let’s say you come across the following sentence: “He thought it might be a good idea to study de ...

PREPOSITION Help Sheet
... 1. Her desire to study is commendable. (to study -- used as part verb and part adjective) 2. To work hard remains his task. (noun) 3. He wanted to mail the letters early. (direct object) 4. To show good taste is important. (subject) 5. Ping went to buy a paper. (adverb) 12. To tell whether you have ...
... 1. Her desire to study is commendable. (to study -- used as part verb and part adjective) 2. To work hard remains his task. (noun) 3. He wanted to mail the letters early. (direct object) 4. To show good taste is important. (subject) 5. Ping went to buy a paper. (adverb) 12. To tell whether you have ...

Understanding New Metaphors
... The italicized words in these examples are common English words with many polysemous senses. The theory predicts that the meanings of these words in the UNIX domain will be related to their other polysemous senses by one or more of the known regularities. The system was implemented and tested as a c ...
... The italicized words in these examples are common English words with many polysemous senses. The theory predicts that the meanings of these words in the UNIX domain will be related to their other polysemous senses by one or more of the known regularities. The system was implemented and tested as a c ...

Uzzi Ornan - CS Technion
... the verb in the center of the expression, and showing how all the other parts of the sentence should obey the demands of the verb. (Tesnière should be mentioned here as the “father–figure”, as Somers 1987, p.1 emphasizes, but note what follows on the same page, as well as in Ch.2.) We exploit this c ...
... the verb in the center of the expression, and showing how all the other parts of the sentence should obey the demands of the verb. (Tesnière should be mentioned here as the “father–figure”, as Somers 1987, p.1 emphasizes, but note what follows on the same page, as well as in Ch.2.) We exploit this c ...