Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Gene regulatory network wikipedia , lookup
Community fingerprinting wikipedia , lookup
Ribosomally synthesized and post-translationally modified peptides wikipedia , lookup
Ancestral sequence reconstruction wikipedia , lookup
Real-time polymerase chain reaction wikipedia , lookup
Two-hybrid screening wikipedia , lookup
RNA interference wikipedia , lookup
Deoxyribozyme wikipedia , lookup
Peptide synthesis wikipedia , lookup
Metalloprotein wikipedia , lookup
RNA silencing wikipedia , lookup
Promoter (genetics) wikipedia , lookup
Proteolysis wikipedia , lookup
Polyadenylation wikipedia , lookup
RNA polymerase II holoenzyme wikipedia , lookup
Artificial gene synthesis wikipedia , lookup
Transcriptional regulation wikipedia , lookup
Nucleic acid analogue wikipedia , lookup
Silencer (genetics) wikipedia , lookup
Eukaryotic transcription wikipedia , lookup
Protein structure prediction wikipedia , lookup
Amino acid synthesis wikipedia , lookup
Messenger RNA wikipedia , lookup
Biochemistry wikipedia , lookup
Gene expression wikipedia , lookup
Point mutation wikipedia , lookup
Transfer RNA wikipedia , lookup
Epitranscriptome wikipedia , lookup
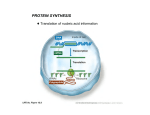
CHAPTER 3 OUTLINE GENE FUNCTION TRANSCRIPTION RNA differs from DNA. -single-stranded -uracil instead of thymine -ribose instead of deoxyribose For any gene there is a transcribed strand (template) and a non-template strand. RNA polymerase makes RNA in a 5’ to 3’ direction, directed by a template, which is anti-parallel to the transcript. Initiation involved interaction of RNA polymerase with the promoter. There are consensus target sequences in the promoter that are critical for these interactions. The strength of the promoters is to some extent a function of how close the target sequences are to the consensus. Mutations in these target sites can have UP or DOWN effects depending on whether the resulting sequences are closer or farther from the consensus. Elongation Nucleoside triphosphates are added to the 3’ end of the growing polynucleotide chain. The identity of the incorporated bases is dictated by the template sequence. Termination Termination is dependent on specific nucleotide sequence signals. A common motif in prokaryotes is the hairpin loop structure, followed by poly-U sequence. Unlike prokaryotes, where there is one principle RNA polymerase, transcription in eukaryotes involves three different RNA polymerases -RNA polymerase I (rRNAs) -RNA polymerase II (mRNAs) -RNA polymerase III (other small functional RNAs) In eukaryotes, RNAs typically undergo processing after being made. -capping at the 5’ end -polyadenylation at the 3’ end -splicing (removal of introns) For splicing there are conserved sequence targets in the intron sequence (GU_________A___AG). Splicing occurs by two transesterification events, resulting in the excised lariat + spliced exons. TRANSLATION Information in the polynucleotide chain is converted to protein, a chain of amino acids. The amino acids are joined by peptide bonds, involving condensation between carboxyl and amino ends. There is a wide variety of amino acids that differ by virtue of their R groups. Levels of protein structure: 1. Primary = the linear amino acid sequence 2. Secondary = periodic structures formed by the polypeptide chains that are stabilized by H bonds. Alpha-helix and beta-pleated sheet. 3. Tertiary = folded secondary structure 4. Quaternary = Interaction between polypeptide subunits GENETIC CODE The genetic code is a triplet code, which is redundant, unambiguous and universal. It includes punctuation, such as start and stop codons. Transfer RNA is the key intermediary in translating. It contains an anticodon at one end (capable of interacting with mRNA codons) and an amino acid at the other end. A family of aminoacyl tRNA synthetases ensures that the tRNAs have the appropriate amino acids. A “Wobble” at the 3’ position of the codon permits the tRNA anticodon to recognize more than one codon: G in the anticodon will base pair with either C or U U in the anticodon will base pair with either A or G I (inosine) in the anticodon with base pair with C or U or A The ribosome is the site of protein synthesis. It is made of one large and one small subunit, each of which is composed of a complex of rRNA and ribosomal proteins. MECHANICS OF TRANSLATION Initiation In prokaryotes, the Shine-Dalgarno sequence in the 5’ UTR pairs with the 16s rRNA in the small subunit of the ribosome, permitting proper positioning of the start codon of the mRNA. The start codon is AUG (or GUG) and is recognized by a specific tRNA that carries a formylated met. In eukaryotes, the 5’ cap interacts with the ribosome, at which point the mRNA is scanned for the start codon (AUG). The initiator tRNA carries methionine. The end result is that the tRNA is now located in the P site (peptidyl) along with the start codon of the mRNA and the ribosome is poised for elongation. Elongation The next codon is located in the A site (aminoacyl), the point where tRNAs carrying aminoacids gain entry. The identity of the amino acid is dictated by the codon-anticodon interaction. A peptide bond is formed between the carboxyl end of the growing polypeptide chain and the amino end of the incoming amino acid. The polypeptide chain then becomes associated with the A site, before being translocation to the P site. The result is that the A site is opened up once again for the addition of the next amino acid. Termination Once the stop codon is in the A site, a release factor causes chain termination and the ribosome dissociates from the mRNA. PROTEIN FUNCTION Beadle and Tatum’s studies with Neurospora established clearly the relationship between genes and their gene products, by identifying mutations that corresponded to specific steps in biochemical pathways. The result was the one gene-one enzyme hypothesis, which became further refined as the one gene-one polypeptide hypothesis. Mutations and human disease Garrod and alkaptonuria Errors in metabolism Mutant nomenclature -denoting recessive vs dominant alleles -types of mutations: point mutations, frameshifts, deletions, etc. and their gene targets. OUTPUT in terms of function: null, leaky, silent Haplo-sufficient vs haplo-insufficient wild type genes. Suggested Problems for Chapter 3: 1-3, 9-12, 16, 18-19, 24-25 Make sure to look at the solved problems (pp. 86-87) as well.