Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Using SAS® Software for the Analysis of Means
Donna O. Fulenwider, SAS Institute Inc., Cary, NC
step-by-step explanation of the SAS code presented by this tutorial, should provide a guide for the implementation of the ANOM
technique using SAS software. The SAS code for the examples
used in this tutorial is given in Appendices 3 and 4.
ABSTRACT
This tutorial is designed as a sequel to the presentation entitled
'Application of the Analysis of Means' given by Dr. Peter R. Nel~
son in the Econometrics, Operations Research, and Quality Control Section. It includes a very brief review of the concept of
analysis of means but focuses primarily on how SAS® software
can be used to perform analysis of means.
THE BASIC STEPS
The following steps present, in their most general form. the
ANOM technique. Listed for each basic step is the SAS software
tool that can be used to perform the task.
INTRODUCTION
• Step 1:
Analysis of means (ANOM) is a technique for comparing a group
of ktreatment means from their grand mean, while controlling the
Type I risk, Q. AN OM can also be viewed as a multiple comparison
procedure that constructs simultaneous confidence intervals for
the contrasts of the individual population means versus their
overall mean (Nelson 1988).
- PROC SHEWHART or
PROC MEANS and the DATA step
• Step 2:
Compute the grand mean.
- PROC SHEWHART or
PROC MEANS and the DATA step
Graphically, ANOM can be thought of as an extension of a
ShewharHype control chart and is viewed in this context
throughout -this tutorial. The dependent or process variable is
plotted versus the classification or subgroup variable. Decision
limits are plotted to statistically and visually test the hypothesis
of differences in means. Consequently, ANOM graphically provides a measure of statistical significance as well as a graphical
measure of quantitative differences.
• Step 3:
Compute an estimate of variance.
- PROC SHEWHART or
PROC MEANS and the DATA step
• Step 4:
ANOM is appropriate for factors involving fixed effects only, as
discussed by Ramig (1983). ANOM can be applied to equal and
unequal sample size data. The choice of the appropriate critical
value to be used for computing the decision lines is the major difference in handling the equal and unequal sample size cases.
When the k means are based on equal sample sizes, their deviations from their grand mean are equicorrelated and exact critical
values, hu, can be computed. For purposes of this tutorial, the
hu values will be computed using an approximation developed by
L.S. Nelson (1983). Nelson reports that the approximation is
accurate to three Significant digits. The sample code for the
approximation is given in Appendix 1.
c
Obtain the appropriate critical value, hu.
the DATA step
• Step 5: Compute the upper and lower deciSion lines
(UDL and LDL).
- the DATA step
• Step 6: Plot the group means, the central grand mean
line, and the decision lines. If any mean falls outside of
the decision lines, declare that there is a statistically
Significant difference among the means.
- PROC SHEWHART
For the unequal sample size, case, the deviations of the group
means from their grand mean are not necessarily equicorrelated,
and therefore exact critical values cannot be computed. Instead,
hu', an upper bound on hu suggested by L.S. Nelson (1983), can
be used. The upper bound is calculated as the fl/2 percentage
point of the Student's t distribution, where,
VARIABLES DATA
Equal Sample Sizes
For simplicity, the ANOM technique is applied to a one-way classification design with equal samples of size n. The data used in
this example are taken from Walpole and Myers (1972, p. 366).
Five different concrete aggregates are used to investigate the
effect of aggregate on the mean absorption of moisture in concrete. Six samples of each aggregate were exposed to moisture
for forty-eight hours, for a total of thirty observations. The data
are read into a SAS data set, EXAMPLE1. with variable names
AGGREGT and MOISTURE. The data are presented in Table 1.
(1 )
k = number of means being compared.
Compute the group means.
(2)
The sample code for hu' can be found in Appendix 2.
Analysis of means is applicable to both variables and attribute
data. Variables data refers to those quality characteristics of a
sample that are expressed as a continuous numerical measure,
such as weight or volume. Conversely, attribute data are quality
characteristics that cannot be expressed as a continuous measure. These types of characteristics are usually noted by observing the presence (or absence) of some attribute of the sample,
such as the number or proportion defective. This tutorial presents
an example of variables data from Ramig (1983). Comparison of
the step-by-step explanation of ANOM given by Ramig, with the
1212
Table 1
The OUTLIMITS data set contains the information necessary to
produce control limits for an X chart of this data. It also provides
the information necessary to calculate the decision limits, or lines,
required by the ANOM technique. The contents of the
OUTHISTORY data set, HIST1, are shown in Table 2; the contents of the OUTLIMITS data set, LlM1, are shown in Table 3.
Moisture Absorption (Wgt %) for Concrete
Aggregate
Aggregt
2
551
457
450
731
499
632
595
580
508
583
633
517
3
639
615
511
573
648
677
4
417
449
517
438
415
555
5
563
631
522
613
656
679
Table 2
Contents of HISTORY Data Set for AGGREGT
AGGREGT
'"'
Step 1 in the ANOM process is to compute the group means, in
this case, the group means of MOISTURE for each value, or level
of AGGREGT. As noted in the previous section, this step can be
accomplished by using either PRQe SHEWHART or PROe
MEANS and the DATA step. PROe SHEWHART is chosen for the
following reasons:
Table 3
• Less programming code is required using PROe
SHEWHART. Several DATA steps and several PROe
MEANS statements are required to provide the same
information given by a single PROe SHEWHART
statement .
OBS
• PROe SHEWHART provides options for creating two
output data sets, the OUTHISTORY and OUTLIMITS data
sets. The OUTHISTORY data set is properly formatted for
reuse in a later PROe SHEWHART statement. The
OUTLIMITS data set contains necessary variable
information that must be entered separately if the PROe
MEANS statement is used.
KOISURES
110.154
47.986
59.946
57.607
58.783
KOI5UREN
Contents of LIMITS Data Set for AGGREGT
_VAL
...5UBGRL
MOISTURE
OB5
KOISURi:X
553.333
569.333
610.500
465.161
610.667
AGGREGT
_TYPE...
..LIKITIL
....ALPHA....
...5IGMAS-
0.0026998
ESTIMATE
....LCLL
JlEAtL
J)CLL
..LCLL
...5_
475.691
561.8
6~7.90J
2.Q3115
66.8952
_UCLL
...5TDDEL
131.759
70.3026
A note about the variable names saved into the OUTHISTORY
data set: if the process variable name is eight characters or more,
PROC SHEWHART creates output variable names by concatenating the first four letters and the last three letters of the variable name. The procedure then appends a suffix letter to the
variable name that indicates the statistic that the variable represents. In this example, the process variable name MOISTURE in
the input data set leads to creation of variables in the
OUTHISTORY data set such as MOISUREN. MOISUREN is a
summary variable that contains n, the number of values of
MOISTURE for each level of AGGREGT.
The following PROC SHEWHART statements produce output
data sets that contain most of the information needed for the
ANOM technique:
PROC SHEWHART DATA:EXAMPLE 1 ;
XCHART MOISTURE*AqGREGT J
NOCHART
STDDEVS
SKETHOD'"RMSDF
OUTHISTORY:HIST 1
DUTLIMITS:LIHl ;
In Step 2 the grand mean is calculated as
(3)
This value corresponds to the grand mean of MOISTURE for all
levels of AGGREGT. PROC SHEWHART saves the value of the
grand mean in the variable _MEAN_ in the OUTLIMITS data set
LIM 1.
The XCHART statement is chosen because it produces Ol,.ltput
data sets that contain information about the subgroup means of
the data. In the syntax of PROC SHEWHART, MOISTURE is the
process variable and AGGREGT is the subgroup variable.
Step 3 is to compute an estimate of· the common but unknown
variance, (i. For this tutorial, S2, the mean square for error, is
used as an estimate of the true population variance. The estimate
of variance is computed as
Several options are used in the XC HART statement. The
NOCHART option is specified in order to suppress the creation
of a chart. At this point in the analysis, the information needed
to create the ANOM chart is not complete.
5
The STDDEVS option requests the use of standard deviations for
creating the control limits for the X chart. By default, PROC
SHEWHART uses the subgroup ranges for estimating the control
limits. The SMETHOD= RMSOF reques"ts the use of the weighted
root mean square method for estimating the subgroup standard
deviations. The use of standard deviations for this analysis is
consistent with the example in Ramig (1983) and is necessary
when using the exact critical values, ha ·
2
~
(n,-1)S12+ ... (nk-1)s~
n, + ... nk - k
(4)
To compute S2, the value provided by the _STDDEV_ variable
contained in LlM1 is used. Recall that the weighted root mean
square method was used to calculate the subgroup standard
deviations in Step 1. This weighted root mean square estimate
is computed as
((n, - 1) 5,2
The OUTHISTORY and OUTLIMITS options create the working
data sets from which the ANOM technique is performed. The
OUTHISTORY data set contains the MOISTURE means for each
level of AGGREGT, or more simply the subgroup means. The
subgroup standard deviation estimates requested by the
STDDEVS option are automatically saved into the OUTHISTORY
data set, HISTl.
c4(n)(n,
+ ... + (nk - 1) 51)'/2
+ ... + n k - k)'/2
(5)
This method provides an unbiased estimate of the subgroup
standard deviations. To compute an unbiased estimate of the
population variance, multiply the unbiased estimate contained in
_STDDEV_ by the unbiasing factor, c4(n), as defined in the Methods for Estimating th·e Standard Deviation a in Chapter 5 of
1213
SAS/QC'-"" User's Guide, Version 5 Edition. SAS/QC software pro-
--.LCLJL=
j!EAN~ ~
vides a DATA step function C4 for calculating the control chart
constant, C4. The square of this quantity provides the estimate
of variance, or MSE, equal to the estimate of variance obtained
from a one-way analysis of variance table. The following DATA
step statements are used to compute the MSE and its corresponding degrees of freedom:
~UCLJL~
jlEAlL
HDELTA;
HDEL'I'A;
~STDDEV~=SQRT( &MSE);
J.LPHL=.05;
t
The creation of the AN OM chart, Step 6, is the final step in the
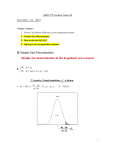
the ANOM technique. The AN OM graph in Figure 1 is produced
using the following PRGC SHEWHART statements:
DATA HIST1Aj
SET HISTI END"'EOF;
RETAIN N;
IF JL'" 1 THEN DO;
N=MOISUREN;
CALL SYKPUT( 'N' ,LEFT( PU'I'(MOISUREN, 11.0) ) J;
END;
IF EOF THEN DO;
SET LIM 1 (KEEP"'---'sTDDEV~J;
KSE"('-sTDDEL * CII(N*JL -(JL-l»)J**2;
KSEDF=JL * (N-1);
CALL SYMPUT( 'MSE' ,LEFT(PUT(MSE, 8. 3 J J );
CALL SYMPUT ( 'KSEDF' ,LEFT (PUT (MSEDF ,8.0) ) ) ;
CALL SYMPUT( 'NTRT' ,LEFT{PUT(JL,8. 0 J );
END;
PROC SHEWHART HISTORY=HIST1A LIMTIS=LIM1A GRAPHICS;
XCHART MOISTURE*AGGREGT /
S'I'DDEVS
TABLEOUT
READLIMITS
READALPHA
CT=WHITE
CLIMTS"-WHITE
CA=WHITE
CFRAME=TAN
FONT=XSWISS
NOCONNECT
CNEEDLES=GREEN
COUT=ORANGE
NOLEGEND
UCLLABEL=' UDL'
LCLLABEL=' LDL'
HAXIS=(' , '1' '2' '3' '4' '5' , ');
LABEL MOISUREX='MOISTURE ABSORPTION'
AGGREGT;:' CONCRETE AGGREGATE' ;
The DATA step above is used to store the value of MOISUREN
into a macro variable for later use in the analysis. Since the example has equal sample sizes for each level of AGGREGT, only one
common variable is needed. This DATA step is also used to store
the MSE, its associated degrees of freedom, and the number of
levels of AGGREGT. This information is needed in the calculation
of the decision limits. The CALL SYMPUT function is used to
avoid tedious data manipulation and merging. For this example,
N~6, MSE~4960.81, MSEDF~25, and NTRT~5.
--
r-----------------------------------------,~-
Step 4 in the ANOM technique involves the calculation of the critical value, ha . A small macro is provided to compute the critical
values for significance levels of .10, .05, .01, and .001. As discussed earlier in this tutorial, the approximation provided by Nelson (1983) was implemented for computing the critical values.
L1---___
. - - - - - - - -___---'-----1
!
The macro has the following syntax:
%ANOMH(alpha,df,k)
where
the Type I risk, a for computing the decision
lines.
alpha
the degrees of freedom associated with
df
S2.
Figure 1
the number of meanS being compared or, in
this context, the number of subgroups.
k
Several options are required to produce the ANOM graph. The
STDDEVS option is needed since the HISTORY data set contains
values based on the subgroup standard deviations. The
REAOLIMITS option indicates to PROC SHEWHART that the limits for the chart should be read from the LlMITS= data set,
LlM1A. Otherwise, the procedure recalculates the control limits
based on the information provided by the HISTORY data set
HIST1.
For a=.05, k=5, and df=25, the ha critical value equals 2.739.
This critical value, which the macro stores into a macro variable,
&HALPHA, is Used in a subsequent step for computing the
desired decision lines.
Step 5 involves the computation of the appropriate decision lines
for the ANOM technique. For equal sample sizes, they are computed as
UDL~X
+ hu S V (k -
l)/kn
(6)
V (k -
l)/kn
(7)
LDL~X - he S
Various other options are specified to provide helpful information
or to designate colors and demarcation for the chart. The
TABLEQUT option creates a table, shown in Table 4, that indentifies the points on the graph that exceed the decision Hnes. The
CNEEDLES option produces orange line segments that connect
the subgroup means with their grand mean. The READALPHA
option is used to produce the note on the graph that shows the
value of a used in the analysis. The HAXIS option that scales the
horizontal axis is new to PROC SHEWHART. It is an enhancement to be found in the next maintenance release of SAS/QC
To produce the appropriate decision lines, the OUTLIMITS data
set, LlM1, is altered to contain decision limits instead of control
limits. The following DATA step is used to create the appropriate
LIMITS data set for producing an AN OM chart with
PROC SHEWHART:
DATA FM1A;
SET LIM1;
HALPHA=~HALPHA;
HDELTA=&HALPHA * SQRT( &MSE) • SQRT(
(&NTRT~1)
ANOM Chart for Example 1
/ (tNTRT*&N»;
1214
CALL SYMPUT{ 'MSEDF' ,LEFT(PUT(MSEOF, S. ) ) ;
CALL SYMPUT{ 'TOTN' ,LEFT(PUT(Sl.JMNI,S.)});
END;
software. For details, see SAS Technical Report P-175, Changes
and Enhancements to the SAS System, Release 5.18, under OS
and eMS. The listing of the SAS code for this example can be
found in Appendix 3.
Table 4
The data set HIST2A is used as the HISTORY data set for input
to PROe SHEWHART. The creation of the _PHASE~ variable is
key in the establishment of the appropriate decision lines for the
ANOM technique. Its purpose is discussed in Step 5.
Resulting Table from TABLEOUT Option for
Example 1
Step 4 in the AN OM technique involves the choice of the appropriate critical value for calculating the decision lines. As discussed previously, an upper bound o·n h(u hu', is used. As in the
equal sample size case, a small macro, ANOMH2, is provided to
compute the critical values.
ANALYSIS OF MEMS
EXAKPLE 1
Subgroup
Sample
Siu
ASGREST
3.a Sigma
LOlfer Limit
For Mean
With n=6
491.35700
Q91.35700
Subgroup
Mean for
MOISTURE
~91.35700
553.33333
569.33333
610.50000
Q91.35700
491.35700
610.66667
~65.16667
3.0 Sigma
Upper Limit
For Mean
With n=6
Mean Limit
Exceeded
The macro has the following syntax:
632.2~300
632.24300
632.24300
632.24300
632.24300
Lower
%ANOMH2(alpha,df,k)
where
alpha
Figure 1 shows that the effect of moisture absorption for Aggregate 4 is significantly different from at least one other aggregate
at an alpha level of .05. Table 4 provides the same information
in tabular form. Other multiple comparison tests, such as
Duncan's Multiple Range Test and Fisher's LSD, lead to the same
conclusions as ANOM for this example. Ramig (1983) notes that
Walpole and Myers (1972) reached the same conclusions using
orthogonal contrasts with the analysis of variance.
the number of means being compared.
52.
Step 5 presents the major difference in the execution of the
ANOM technique for un,equal sample sizes. The AN OM decision
lines are dependent on the individual sample sizes, n j , of the
grouping variable AGGREGT. Therefore, the LIMITS data set for
input to PROe SH EWHART must contain an observation for each
value of AGGREGT, five observations in this example. The decision lines for unequal sample sizes are calculated as
Aggregate Data from Example 1 with Missing
Samples
Aggregt
2
595
580
508
583
633
the degrees of freedom associated with
k
5.
To illustrate the use of the ANOM technique for unequal sample
sizes, suppose that several samples of aggregate from Example
1 were not measureable. Table 5 contains the new unbalanced
data set, EXAMPLE2. The data set contains a total (N) of 22
observations.
1
551
457
450
731
499
632
df
For this example, with a=.05, k=5, and df=17, the critical value,
h(;, is 2.889. As before, the macro stores the critical value into
a macro variable, &HALPHA. This critical value is required in Step
Unequal Sample Sizes
Table 5
the Type I risk, a for computing the decision
lines.
3
639
615
511
573
4
417
449
517
438
5
563
631
522
UDL ~
X+ h; s V (N -
n;)/Nn;
(9)
LDL ~
X-
V (N -
n;)lNn;
(10)
h; s
The following DATA step is executed to produce the LIMITS data
set, LlM2A:
DATA LIM1A;
RETAIN _VAL --'sUBGRP- _SIGNAL -ALPHA..- ..JiEAN....;
LENGTH _INDElL. $ II.;
IF JL: 1 THEN SET LIM2;
SET HIST2 (KEEP",MOISUREN);
_INDEX-=--.N_;
HALPHA=5HALPHA;
HDELTA=5HALPHA. SQRT(~MSEl • SQRT((UOTN - MOISUREN) /
(5TOTN·MOISURENj) ;
_UCLlL.",..JiEML + HDELTA;
--.LCLXL=--.MEAN.... - HDELTA;
--.STDDEV-:SQRT (f;MSE 1 ;
--.LIMITIL=KOISUREN;
Execution of Steps 1 and 2 in the ANOM technique for unequal
sample sizes are no different in concept from the equal sample
size case. OUTHISTORY and OUTUMITS data sets, HIST2 and
L1M2 respectively, are created. A notable difference between the
one-way classification with equal sample sizes versus unequal
sample sizes is in the coding required for the calculation of the
MSE.
Due to the presence of the unequal sample sizes, the ANOM
technique requires varying decision lines. Two new variables,
_PHASE.-.- and _INDEL, are needed to produce these varying
decision lines. The _PHASE.-.- variable resides in the HISTORY
data set, and the _INDEL variable is contained in the LIMITS
data set. Tables 6 and 7 contain the contents of the HISTORY
and LIMITS data sets.
Step 3 in the ANOM process requires the calculation of S2. As
stated previously, the pooled mean square for error, or MSE, is
chosen as this estimate of variance. The following OATA step is
used to produce this estimate of MSE:
DATA HIST2A;
RETAIN SUMNI;
SET HIST2 END"EOF;
_PHASE-"AGGREGT;
SUKNI+KOISUREN;
IF EOF THEN DO;
SET LIM2 (KEEP",--.STDDEL);
MSE=(--.STDDEL.C4(SUMNI - iJL - 1))**2;
MSEDF"SUHNI-JL;
CALL SYKPUT('MSE' ,LEFT(PtrrjMSE,S.3»);
1215
Table 6
OBS
AGGREGT
Table 7
aBS
Contents of HISTORY Data Set for Example 2
IfOlSUREX
KOISURES
553.333
579.BOll
584.500
455.250
572.000
110.154
45.351
56.11BO
43.254
55.055
}tOISUR!N
KOtSVAR
KOISNN
aggregates in terms of their effect on moisture absorption in concrete. Table 8, created by the TABLEOUT option, verifies the conclusion. A listing of the SAS code used to apply the ANOM
technique to the one-way classification Example 2 is given in
Appendix 4.
JHASIL
12133.9
2056.7
3145.0
1810.9
3031.0
...----------r-----------------..t
t----------..r ------·
Contents of LIMITS Data Set for Example 2
_VAR....
--.SUBGRL --.SIGMAS- _Al.PIIL --'!lEAN....
O.002E998549.727
ll.U026998549.127
0.002E99B 549.127
O.002E998549.727
O.002E998549.727
MOISTURE
MOISTun
MOISTURE
MOtSTU!lB
AGGREGT
AGGREGT
AGGREGT
AGGREGT
MOISTUU AGGREGT
476.541 622.914
~E7.088 632.367
454.655644.799
454.655644.799
436.939 662.515
,, v, ,,
,, v ,,
,v
v
v
72.76ll
12.1631
72.1631
12.1631
72.1"631
_INDEx....
_TYPE..... ......LIMITN.....
LI------II....---I-----_..__---.'------1,-
ESTlKAT£
ESTlMATE
ESTlMATE
ESTIMATE
ESTIMATE
2.889
2.889
2.889
2.889
2.889
I
---------,'--......_ ..1___..__.._ --,
.
13.1B7
82.639
95.672
95.'072
112.788
........ _ .. _ .... _ .. __ w.
Within PROC SHEWHART, the variables _PHASE_ and
_INOEL are most often used in the generation of historical control charts. In the context of ANOM, however, these options are
used to signal PROC SHEWHART that varying decision lines
exist.
Figure 2
Table 8
Step 6 of the ANOM technique produces the ANOM chart. The
existence of the _PHASE_ and _INDEX- variables in the
HISTORY and LIMITS data sets facilitates the use of the
READPHASES and READINDEXES options in the XCHART
statement. With the exception of these two options, Step 6 for
the one-way classification with unequal sample sizes is identical
to the equal sample size case.
ANOM Chart for Example 2
Resulting Table from TABLEOUT Option for
Example 2
Phase
AGGREG'I'
Subqroup
Sample
Size
3.0 Slgma
tower Limit
For Mean
476.54067
467.08797
454.65509
454.65509
436.93915
PROC SHEWHART HISTORY"HIST2A LIMITS=LIK2A GRAPHICS;
XCHART HOISTURE*AGGREGT I
STOOEVS
TABLEOUT
REAOPHASES"('I' '2' '3' 'ii' '5')
REAOINOEXES,,{'l' '2' '3' '4' '5')
READLIKITS
NOCONNECT
NOLEGENO
CT"WHITE
CLIMITS"WHITE
CA"WHITE
CNEEDLES"GREEN
FONT=XSWISS
UCLLABEL=' UOL'
LCLLABEL=' LOt'
CFRAME=LIO
COUT",ORANGE
HAXIS=(' , 'I' '2' '3' '4' '5' , 'I;
LABEL MOISUREX,,'MOISTURE ABSORPTION'
AGGREGT'" CONCRETE AGGREGATE';
Phase
AGGREGT
Subgroup
Mean for
MOISTURE
553.33333
S79.S0nOO
584.50000
455.25000
572.00000
3.n Sigma
Upper Limit
For Mean
622.91387
632.36658
644.79945
644.79945
662.51540
Mean Limit
E:xceeded
SUMMARY
SAS software can easily be used to perform the ANOM technique. The SHEWHART procedure facilitates the use of the analysis of means with its variety of chart statements and options. This
tutorial provides the SAS software tools necessary to perform
analysis of means.
Appendix 1
1****************************************************************1
S A S S AMP L E L I BRA R Y
*1
The READPHASES and READINDEXES options direct PROC
SHEWHART to plot the information given in the HISTORY and
LIMITS data sets corresponding to the character values given in
the READPHASES and READINDEXES list. In this example, the
_PHASE_ and _INDEX- variables contained character representations of the numeric values 1 through 5. The READPHASES
and READINDEXES options require that the information provided
by the HISTORY and LIMITS data sets be plotted for values of
_PHASE- and _INDEX- that correspond to the character values, 1 through 5. In this example, the character list given by the
XCHART options is an exhaustive one.
,.1*
.,
1*
1*
1*
1*
1*
1*
NAME: ANOMH
*1
TITLE: MACRO FOR PROVIDING CRITICAL VALUES FOR ANALYSIS
*1
OF MEANS TECHNIQUE
*1
REF: L,S. NELSON (19B3), 'EXACT CRITICAL VALUES FOR
*1
USE WITH THE ANALYSIS Of MEANS'. JOURNAL OF QUALITY */
TECHNOLOGY 15, pp, 110-11'11.
*1
.,
"1***********************************'****************************1
,.,.1*
"
,."
Figure 2 presents the ANOM chart for AGGREGT. It is apparent
from the graph that there is no significant difference among
1216
THIS MACRO IS DESIGNED TO PROVIDE THE CRITICAL VALUES
NEEDED FOR USE WITH THE ANALYSIS OF MEANS. TilE VALUES
ARE VALID FOR THE ANALYSIS OF MEANS OF EQUAL SAMPLE
SIZES FOR SIGNIFICANCE LEVELS OF .10, .05, .01, AND
.001 • THE VALUES GENERATED ARE APPROXIMATE VALUES
WITH THE ABSOLUTE MAXIMUM DEVIATION FROM THE TRUE
*1
"
"
"
"
"
TABLE VALUES TO BE LESS THAN ONE IN THE THIRD
SIGNIFICANT DIGIT.
f.
f.
Appendix 2
'1
'1
f . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .•••••• f
f •••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••• f
f.
I'
I'
I'
I'
I'
I'
I'
SHACRO ANO.KH(ALPHA,DF,K);
J,GLOBAL HALPHA;
DATA ---.NULL.....;
f.
CHECK FOR ERRORS IN ARGUKENTS OF THE FUNCTION
'1
"
"
IF 'OF LT J THEN DO;
PUT
ERROR: THE DEGREES OF FREEDOM ARE LESS THAN 3';
ABORT;
IF I>K GT 'DF THEN DO;
PUT' ERROR: THE NUMBER OF MEANS IS GREATER THAN THE NUMBER OF'
DEGREES OF FREEDOM. DEGREES OF FREEDOM FOR ERROR SHOULD BE'
K( N-I ) • CHECK YOUR INPUT.';
ABORT;
END;
f.
I'
I'
I'
I'
I'
"
"
I'
BUILD ARRAYS TO CONTAIN THE CONSTANTS TO BE USED FOR
APPROXIMATING THE HALPHA VALUES.
NAME: ANOMH2
TITLE: MACRO FOR PROVIDING UPPER BOUNDS ON THE TRUE
VALUE OF THE CRITICAL VALUE NECESSARY FOR THE
ANALYSIS OF MEANS TECHNIQUE
REF: L.S. NELSON (1983), 'EXACT CRITICAL VALUES FOR
USE WITH THE ANALYSIS OF MEANS'. JOURNAL OF QUALITY
TECHNOLOGY IS, PP. 40-~4.
'f
'1
'1
'1
'1
'1
'1
'1
"'1
f •••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••• f
END;
f.
f.
S ASS AMP L E L I BRA R Y
THIS MACRO IS DESIGNED TO PROVIDE UPPER BOUNDS ON THE
CRITICAL VALUES NEEDED FOR USE WITH THE ANALYSIS OF MEANS
TECHNIQUE FOR DATA WITH UNEQUAL SAMPLE SHES.
THE VALUES GENERATED ARE CALCULATED AS THE UPPER 'ALPHA" f2
PERCENTAGE POINTS OF A STUDENT'S T DISTRIBUTION, 'WHERE
'ALPHA*' 12=1-( I-ALPHA) •• ! 11K}
ALPHA = THE DESIRED SIGNIFICANCE LEVEL
K = THE NUHBER OF MEANS
IT SHOULD ALSO BE USED TO PROVIDE HALPHA VALUES WHERE THE
NUHBER OF DEGREES OF FREEDOM FOR ERROR IS LESS THAN K.
THE ARGUMENTS OF THE FUNCTION ARE THE SAME FOR THE BALANCED
DATA CASE. (SEE THE SAMPLE KEMBER, ANOKH)
I'
I'
f.
f ••• .................................
'f
'f
IF 'ALPHA=.IO THEN DO;
ARRAY BIOO(81 Bl-B8;
BIOOI1)= 1.2092;
BlOOP)" 0.7992;
BIOOP)= 0.6238;
BIOO(III-" 0.11797;
BIOO(5)= 1.6819;
BIOO{6),,-0.2155;
BIOO(1)'" 0.4529;
BIOO(8)=-0.6095;
'f
'1
'1
'1
'1
'1
'1
'1
'1
'1
'1
.f
*•••• *........... ** ••••••••• *f
j1MACRO ANOKH2(ALPHA,DF ,K);
DATA ---.NULL.....;
ASTAR = 1 -
(l-'ALPHA)"(lf~KJ;
f. SINCE ASTAR CORRESPONDS TO A TWO-SIDED SIGNIFICANCE LEVEL,
f. THE ONE-SIDED LEVEL h'OULO BE ASTARf2
.f
.f
END;
IF tALPHA". 05 THEN DO;
ARRAY B050(8) Bl-B8;
B050(1)'" 1.7011;
B050(2)'"' 0.6047;
B050P]'" 0.7102;
B050 (4] = 1.11605;
B050(5]= 1.9102;
B050(6]= 0.2250;
8050(1]= 0.6300;
B050 (8) =-0. 2202;
END;
IF 'ALPHA=.OI THEN DO;
ARRAY BOIO/8) 81-B8;
BOIOP)= 2.3539;
BOIOPI= 0.5176;
B010(3}= 0.711J7;
B010(1I]= 4.3161;
B010(51= 2.3629;
B010(6)= 4.6400;
8010P): 1.86110;
8010(8)= 0.3204;
END;
IF ,ALPHA=.OOI THEN DO;
ARRAY BOOI18] BI-88;
8001(1]= 3.1981;
BOOIP}= 0.3619;
BOOIP)= 0.7886;
BOOI1~)= 8.31189;
BOOI{5)= 3.1003;
B001(6]=21.1005;
BOO1{7}= 5.1211;
8001(8)= 0.7271;
END;
AS TAR " ASTARf2;
f. COMPUTE THE PROBABILITY VALUE NECESSARY FOR THE TINV FOHCTION *f
PROB = 1 - ASTAR;
HALPHA = TINV(PROB,&DF);
CALL SYMPUTj' HALPHA' ,LEFT(PUT{HALPHA,8. 3»));
j1MEND ANOMH2;
Appendix 3
UNCLUDE ANOHH;
RUN;
DATA EXAMPLE I ;
INPUT AGGREGT $ 1 iii;
DO 1=1 TO 6;
INPUT MOISTURE iii;
OUTPUT;
END;
DROP I;
CARDS;
551 451
595 580
639 615
411 449
563 631
Q50
508
511
511
522
731
583
573
438
613
499
633
648
415
656
632
517
611
555
619
PROC SHEWHART DATA:EXAMPLE 1 ;
XCHART HOISTURE.AGGREGTI
HOCKART
SToDEVS
SKETHOD"'RKSDF
OUTHISTORY"'HISTI
OUTLIMITS=-LIKl ;
KI
LOG!");
K2
LOG{iK-21;
VI
If(&DF-11;
HALPHA = Bl -+ B2.{K'**B3) -+ (B4 + B5.Kl).Vl +
(B6 + B1.K2 + B8.K2.,2).Vl**2;
CALL SYMPUT{ 'HALPHA' ,LEFT(PUT(HALPKA,8.3)));
DATA HIST1A;
SET HIST1 END=EOF;
RETAIN N;
IF ---.N_"I THEN DO;
N"MOISUREN;
CALL SYMPUT( 'N' ,LEFT(PUT(HOISUREN, 4.)));
END;
IF EOF THEN DO;
SET LIMI (KEEP"'_STDDEL);
iHEND ANOKH;
1217
KSE= (_STDDEV- * ClI(N*...1L - 1_1L-1) J)**2;
KSEDF=....lL*(N-l) ;
CALL SYKPUT1' NTRT' ,LEFT(PUT(...1L. ij.1 J J;
CALL SYKPUTI 'KSE' ,LEFT1PUT(MSE,8 .3}) J;
CALL SYMPUT( 'MSEDF' ,LEFT{PUT{HSEDF ,8.) J J;
END;
STDDEVS
SMETHOD=RHSDF
OUTHISTORY=HIST2
OUTLIMITS=LIH2 ;
RUN;
RUN;
/"
NOTE;
ALPHA LEVEL IS .05, HALPHA IS CALCULATED
DATA HIST2A;
RETAIN SUHNI;
SET HIST2 END=EOF;
---.PHASIL=AGGREGT;
SUHNI+HOISUREN;
IF EOF THEN DO;
SET LIH2(KEEP,,---.STDDEV-I;
KSE=(---'sTDDEV-*C4{SUHNI - (..JL -111)**2;
HSEDF=SUMNI-....lL;
CALL SYMPUT( 'KSE' ,LEFT{PUT(HSE,B. 31));
CALL SYMPUT{ 'KSEDF' ,LEFT(PUT{MSEDF ,B.)));
CALL SYMPUT{ 'NTRT' ,LEFT(PUT(....lL, 8. )));
CALL SYMPUT( 'TOTN' ,LEFT(PUT(SUMNI,S.));
0/
:i.ANOMH{. 05, iMSEDF. iNTRT);
DATA LIM1A;
SET LIM1;
HALPHA"iHALPHA;
HDELTA"tHALPHA*SQRT( iKSEJ.SQRT{ (iNTRT-l)/( Ufi'RT*iN));
....I.CLx....=...1!EAlL-HDELTA;
_UCLL=...1!EAN....+HDELTA;
_STDDEV-=SQRT( iKSE);
-ALPHA.....=.OS;
END;
RUN;
1*
NOTE:
ALPHA LEVEL IS .05, HALPHA IS CALCULATED
RUN;
lANOKH2{ .05, tHSEDF, tNTRT);
GOPTIONS NOTEXT82;
SYHBOL 1 V"NONE H=3 C=WHITE '1(=20 F=;
TITLEl FONT=XSWISS H=1.5 C=WHITE 'ANALYSIS OF HEANS";
TITtE2 FONT"XSWISS H=.9 C=WHITE 'EXAMPLE 1';
PROC SHEWHART HISTORY=HIST1A LIKITS=LIH1A GRAPHICS;
XCHART HOISTURE*AGGREGTI
STDDEVS
SHETHOO=RKSDF
CT=WHITE
CFRAKE=TAN
CLIHITS=WHITE
CA"'WHITE
COUT=KORO
FONT=XS14ISS
READLIHITS
READALPHA
NOCONNECT
CNEEDLES=GREEN
NOLEGEND
UCLLABEL=' UDL'
LCLLABEL=' LOL'
HAXIS=(' , '1' '2' '3' '4' '5' , 'I;
LABEL HOISUREX= 'MOISTURE ABSORPTION'
AGGREGT=' CONCRETE AGGREGATE' :
DATA LIM2A;
RETAIN _VAL ---'sUBGRP_ ---.SIGKAL -ALPHA.... ...1!EAlL;
LENGTH _INDEL $ -4.;
IF ....lL" 1 THEN SET LIM2;
SET HIST2(KEEP=MOISUREN);
_INDEL=....lL;
HALPHA=tHALPHA;
HDELTA=iHALPHA*SQRT( ~MSE) .SQRT{ (tTOTN-MOISUREN) /
(tTOTN*HOISUREN) );
---ULL=...1!EAlL-HDELTA;
_UCLL=JlEAtL+HDELTA;
---.STDDEL"SQRT1 tMSE);
....I.IKITtL=MOISUREN;
OUTPUT;
GOPTIONS NOTEXTB2;
SYMBOL 1 V=NONE H=3 14=20 F=;
TITLE 1 FONT=XSWISS H=1.5 C"WHI'I'E 'ANALYSIS OF MEANS';
TITLE2 FONT=XSWISS H=.9 C=WHITE 'EXAMPLE 2';
PROC SHEWHART IiISTORY=HIST2A LIMITS=LIM2A GRAPHICS;
XCHART KOISTURE*AGGREGTI
STDDEVS
TABLEOUT
READPHASES"( 'I' '2' '3' '4' '5')
READINDEXES=('1' '2' '3' 'ij' '5')
CT=WHITE
CLIMI'l'S=WHI'l'E
CA=WHITE
FONT=XSWISS
READLIKITS
NOCONNECT
CNEEDLES=GREEN
COUT"ORANGE
CFRAKE=LIO
NOLEGEND
UCLLABEL=' \JDL' LCLLABEL'" LDL'
HAXIS=(' , 'I' '2' '3' '4' '5' , 'J;
LABEL HOISUREX,,'MOISTURE ABSORPTION'
AGGREGT=' CONCRETE AGGREGATE';
RUN;
Appendix 4
UNCLUDE ANOMH2;
RUN;
DATA EXAKPLE2 ;
INPUT AGGREGT $ MOISTURE
CARDS;
551
4S7
<SO
731
'"
612
595
580
50'
583
63J
639
615
511
573
'"
m
517
43'
563
631
522
PROC SHEWHART DATA=EXAMPLE2;
XCHART HOISTURE*AGGREGT I
NOCHART
1218
REFERENCES
Nelson, L.S. (1974), "Factors for the Analysis of Means," Journal
of Quality Technology, 6,175-181.
Nelson, l. S. (1983). "Exact Critical Values for Use With the Analysis of Means," Journal of Quality Technology, 15,40-44.
Nelson, P. R. (1983), "A Comparison of Sample Sizes for the Analysis of Means and the Analysis of Variance," Journal of Quality
Technology, 15, 33-39.
Nelson, P. R. (1985), "Power Curves for the Analysis of Means,ft
Technometrics, 27, 65-73.
Ne/son, P.R. (1988). "Multiple Comparisons of Means Using
Simultaneous Confidence Intervals, Submitted for Publication.
Ott, E. R. (1967). "Analysis of Means - A Graphical Procedure," Industrial Quality Control, 24, 101-109.
Ramig, P. R. (1983), "Applications of the Analysis of Means,"
Journal of Quality Technology, 15. 19-25.
Walpole, RE. and Myers, R.H. (1972). Probability and Statistics
for Engineers and Scientists. New York: The MacMillian Co.
ft
SAS and SAS/QC are registered trademarks of SAS Institute Inc_.
Cary, NC, USA.
1219