Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
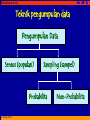
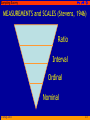
Sampling Survey SAMPLING SURVEY TECHNIQUE © aSup-2011 1 Sampling Survey POPULATIONS and SAMPLES THE POPULATION is the set of all the individuals of interest in particular study The result from the sample are generalized from the population The sample is selected from the population THE SAMPLE is a set of individuals selected from a population, usually intended to represent the population in a research study © aSup-2011 2 Sampling Survey Teknik pengumpulan data Pengumpulan Data Sensus (populasi) Sampling (sampel) Probabilita © aSup-2011 Non-Probabilita Sampling Survey PARAMETER and STATISTIC A parameter is a value, usually a numerical value, that describes a population. A parameter may be obtained from a single measurement, or it may be derived from a set of measurements from the population A statistic is a value, usually a numerical value, that describes a sample. A statistic may be obtained from a single measurement, or it may be derived from a set of measurement from sample © aSup-2011 4 Sampling Survey SAMPLING ERROR Although samples are generally representative of their population, a sample is not expected to give a perfectly accurate picture of the whole population There usually is some discrepancy between sample statistic and the corresponding population parameter called sampling error © aSup-2011 5 Sampling Survey TWO KINDS OF NUMERICAL DATA Generally fall into two major categories: 1. Counted frequencies enumeration data 2. Measured metric or scale values measurement or metric data Statistical procedures deal with both kinds of data © aSup-2011 6 Sampling Survey DATUM and DATA The measurement or observation obtain for each individual is called a datum or, more commonly a score or raw score The complete set of score or measurement is called the data set or simply the data After data are obtained, statistical methods are used to organize and interpret the data © aSup-2011 7 Sampling Survey VARIABLE A variable is a characteristic or condition that changes or has different values for different individual A constant is a characteristic or condition that does not vary but is the same for every individual A research study comparing vocabulary skills for 12-year-old boys © aSup-2011 8 Sampling Survey QUALITATIVE and QUANTITATIVE Categories Qualitative: the classes of objects are different in kind. There is no reason for saying that one is greater or less, higher or lower, better or worse than another. Quantitative: the groups can be ordered according to quantity or amount It may be the cases vary continuously along a continuum which we recognized. © aSup-2011 9 Sampling Survey DISCRETE and CONTINUOUS Variables A discrete variable. No values can exist between two neighboring categories. A continuous variable is divisible into an infinite number or fractional parts ○ It should be very rare to obtain identical measurements for two different individual ○ Each measurement category is actually an interval that must be define by boundaries called real limits © aSup-2011 10 Sampling Survey CONTINUOUS Variables Most interval-scale measurement are taken to the nearest unit (foot, inch, cm, mm) depending upon the fineness of the measuring instrument and the accuracy we demand for the purposes at hand. And so it is with most psychological and educational measurement. A score of 48 means from 47.5 to 48.5 We assume that a score is never a point on the scale, but occupies an interval from a half unit below to a half unit above the given number. © aSup-2011 11 Sampling Survey FREQUENCIES, PERCENTAGES, PROPORTIONS, and RATIOS Frequency defined as the number of objects or event in category. Percentages (P) defined as the number of objects or event in category divided by 100. Proportions (p). Whereas with percentage the base 100, with proportions the base or total is 1.0 Ratio is a fraction. The ratio of a to b is the fraction a/b. A proportion is a special ratio, the ratio of a part to a total. © aSup-2011 12 Sampling Survey MEASUREMENTS and SCALES (Stevens, 1946) Ratio Interval Ordinal Nominal © aSup-2011 13 Sampling Survey FREQUENCY DISTRIBUTION, GRAPH, and PERCENTILE © aSup-2011 14 Sampling Survey A class of 40 students has just returned the Perceptual Speed test score. Aside from the primary question about your grade, you’d like to know more about how you stand in the class How does your score compare with other in the class? What was the range of performance What more can you learn by studying the scores? © aSup-2011 15 Sampling Survey Score of PERCEPTUAL SPEED Test 29 40 36 32 46 47 49 53 51 50 45 48 25 48 28 40 37 58 54 44 48 48 33 47 52 48 46 33 40 49 49 55 43 38 56 45 67 42 44 48 Taken from Guilford p.55 © aSup-2011 16 Sampling Survey OVERVIEW When a researcher finished the data collect phase of an experiment, the result usually consist pages of numbers The immediate problem for the researcher is to organize the scores into some comprehensible form so that any trend in the data can be seen easily and communicated to others This is the jobs of descriptive statistics; to simplify the organization and presentation of data One of the most common procedures for organizing a set of data is to place the scores in a FREQUENCY DISTRIBUTION © aSup-2011 17 Sampling Survey GROUPED SCORES After we obtain a set of measurement (data), a common next step is to put them in a systematic order by grouping them in classes With numerical data, combining individual scores often makes it easier to display the data and to grasp their meaning. This is especially true when there is a wide range of values. © aSup-2011 18 Sampling Survey TWO GENERAL CUSTOMS IN THE SIZE OF CLASS INTERVAL 1. We should prefer not fewer than 10 and more than 20 class interval. ○ More commonly, the number class interval used is 10 to 15. ○ An advantage of a small number class interval is that we have fewer frequencies which to deal with ○ An advantage of larger number class interval is higher accuracy of computation © aSup-2011 19 Sampling Survey TWO GENERAL CUSTOMS IN THE SIZE OF CLASS INTERVAL 2. Determining the choice of class interval is that certain ranges of units (scores) are preferred. Those ranges are 2, 3, 5, 10, and 20. These five interval sizes will take care of almost all sets of data © aSup-2011 20 Sampling Survey Score of PERCEPTUAL SPEED Test 29 40 36 32 46 47 49 53 51 50 45 48 25 48 28 40 37 58 54 44 48 48 33 47 52 48 46 33 40 49 49 55 43 38 56 45 67 42 44 48 Taken from Guilford p.55 © aSup-2011 21 Sampling Survey HOW TO CONSTRUCT A GROUPED FREQUENCY DISTRIBUTION Step 1 : find the lowest score and the highest score Step 2 : find the range by subtracting the lowest score from the highest Step 3 : divide the range by 10 and by 20 to determine the largest and the smallest acceptable interval widths. Choose a convenient width (i) within these limits © aSup-2011 22 Sampling Survey Score of PERCEPTUAL SPEED Test 29 47 45 40 48 48 49 45 40 49 48 37 48 46 55 67 36 53 25 58 33 33 43 42 32 51 48 54 47 40 38 44 46 50 28 44 52 49 56 48 Range = 42 42 : 10 = 4,2 and 42 : 20 = 2,1 © aSup-2011 23 Sampling Survey WHERE TO START CLASS INTERVAL It’s natural to start the interval with their lowest scores at multiples of the size of the interval. When the interval is 3, to start with 24, 27, 30, 33, etc.; when the interval is 4, to start with 24, 28, 32, 36, etc. © aSup-2011 24 Sampling Survey HOW TO CONSTRUCT A GROUPED FREQUENCY DISTRIBUTION Step 4 : determine the score at which the lowest interval should begin. It should ordinarily be a multiple of the interval. Step 5 : record the limits of all class interval, placing the interval containing the highest score value at the top. Make the intervals continuous and of the same width Step 6 : using the tally system, enter the raw scores in the appropriate class intervals Step 7 : convert each tally to a frequency © aSup-2011 25 Sampling Survey FREQUENCY DISTRIBUTION TABLE SCORE 66 - 68 X max = 67 63 - 65 60 - 62 Interval = 3 C.i = 15 60 - 63 RANGE = 42 56 - 59 51 - 53 52 - 55 Interval = 4 48 - 50 48 - 51 45 - 47 C.i = 11 44 - 47 42 - 44 39 - 41 40 - 43 36 - 38 36 - 39 33 - 35 32 - 35 30 - 32 © aSup-2011 64 - 67 X min = 25 57 -59 54 - 56 SCORE 27 - 29 28 - 31 24 - 26 24 - 27 26 Sampling Survey P E R C E P T U A L S P E E D SCORE f Xc Lower Exact Limit Upper Exact Limit 64 -67 1 65.5 63.5 67.5 60 - 63 0 61.5 59.5 63.5 56 - 59 2 57.5 55.5 59.5 52 - 55 4 53.5 51.5 55.5 48 - 51 11 49.5 47.5 51.5 44 - 47 8 45.5 43.5 47.5 40 - 43 5 41.5 39.5 43.5 36 - 39 3 37.5 35.5 39.5 32 - 35 3 33.5 31.5 35.5 28 - 31 2 29.5 27.5 31.5 24 - 27 1 25.5 23.5 27.5 © aSup-2011 27 Sampling Survey WARNING!! Although grouped frequency distribution can make easier to interpret data, some information is lost. In the table, we can see that more people scored in the interval 48 – 51 than in any other interval However, unless we have all the original scores to look at, we would not know whether the 11 scores in this interval were all 48s, all, 49s, all 50s, or all 51 or were spread throughout the interval in some way This problem is referred to as GROUPING ERROR The wider the class interval width, the greater the potential for grouping error © aSup-2011 28 Sampling Survey STEM and LEAF DISPLAY In 1977, J.W. Tukey presented a technique for organizing data that provides a simple alternative to a frequency distribution table or graph This technique called a stem and leaf display, requires that each score be separated into two parts. The first digit (or digits) is called the stem, and the last digit (or digits) is called the leaf. © aSup-2011 29 Sampling Survey Data 83 62 71 76 85 32 56 74 82 93 68 52 42 57 73 81 © aSup-2011 63 78 33 97 46 59 74 76 Stem & Leaf Display 3 4 5 6 7 8 9 2 3 2 6 6 2 7 9 2 1 3 3 2 8 3 6 4 3 8 4 6 5 2 1 7 30 Sampling Survey 7 9 3 4 3 8 4 6 2 1 GROUPED FREQUENCY DISTRIBUTION HISTOGRAM AND A STEM AND LEAF DISPLAY 2 2 6 2 1 3 3 30 40 50 60 70 80 90 © aSup-2011 3 4 5 6 7 8 9 0 3 6 2 8 6 5 7 7 6 5 4 3 2 1 31 Sampling Survey MAKING GRAPH POLIGON and HISTOGRAM © aSup-2011 32 Sampling Survey MAKING GRAPH POLIGON © aSup-2011 33 Sampling Survey P E R C E P T U A L S P E E D SCORE f Xc 64 -67 1 65.5 63.5 67.5 60 - 63 0 61.5 59.5 63.5 56 - 59 2 57.5 55.5 59.5 52 - 55 4 53.5 51.5 55.5 48 - 51 11 49.5 47.5 51.5 44 - 47 8 45.5 43.5 47.5 40 - 43 5 41.5 39.5 43.5 36 - 39 3 37.5 35.5 39.5 32 - 35 3 33.5 31.5 35.5 28 - 31 2 29.5 27.5 31.5 24 - 27 1 25.5 23.5 27.5 © aSup-2011 Lower Exact Limit Lower Exact Limit 34 Sampling Survey f 12 POLIGON 10 8 6 Class Interval’s MIDPOINT 4 2 0 © aSup-2011 X 21.5 29.5 37.5 45.5 53.5 61.5 69.5 25.5 33.5 41.5 49.5 57.5 65.5 35 Sampling Survey f 12 PERCEPTUAL SPEED 10 8 6 4 2 0 © aSup-2011 X 21.5 29.5 37.5 45.5 53.5 61.5 69.5 25.5 33.5 41.5 49.5 57.5 65.5 36 Sampling Survey MAKING GRAPH HISTOGRAM © aSup-2011 37 Sampling Survey P E R C E P T U A L S P E E D SCORE f Xc 64 -67 1 65.5 63.5 67.5 60 - 63 0 61.5 59.5 63.5 56 - 59 2 57.5 55.5 59.5 52 - 55 4 53.5 51.5 55.5 48 - 51 11 49.5 47.5 51.5 44 - 47 8 45.5 43.5 47.5 40 - 43 5 41.5 39.5 43.5 36 - 39 3 37.5 35.5 39.5 32 - 35 3 33.5 31.5 35.5 28 - 31 2 29.5 27.5 31.5 24 - 27 1 25.5 23.5 27.5 © aSup-2011 Lower Exact Limit Lower Exact Limit 38 Sampling Survey f 12 HISTOGRAM 10 8 Class Interval’s EXACT LIMIT 6 4 2 0 © aSup-2011 X 27.5 35.5 43.5 51.5 59.5 67.5 23.5 31.5 39.5 47.5 55.5 63.5 39 Sampling Survey f 12 POLIGON and HISTOGRAM 10 8 6 4 2 0 © aSup-2011 X 27.5 35.5 43.5 51.5 59.5 67.5 23.5 31.5 39.5 47.5 55.5 63.5 40 Sampling Survey THE SHAPE OF A FREQUENCY DISTRIBUTION Symmetrical positive It is possible to draw a vertical line through the middle so that one side of the distribution is a mirror image of the other Skewed negative The scores tend to pile up toward one end of the scale and taper off gradually at the other end © aSup-2011 41 Sampling Survey LEARNING CHECK Describe the shape of distribution for the data in the following table © aSup-2011 X f 5 4 3 2 1 4 6 3 1 1 The distribution is negatively skewed 42 Sampling Survey PERCENTILES and PERCENTILE RANKS The percentile system is widely used in educational measurement to report the standing of an individual relative performance of known group. It is based on cumulative percentage distribution. A percentile is a point on the measurement scale below which specified percentage of the cases in the distribution falls The rank or percentile rank of a particular score is defined as the percentage of individuals in the distribution with scores at or below the particular value When a score is identified by its percentile rank, the score called percentile © aSup-2011 43 Sampling Survey Suppose, for example that A have a score of X=78 on an exam and we know exactly 60% of the class had score of 78 or lower….… Then A score X=78 has a percentile of 60%, and A score would be called the 60th percentile Percentile Rank refers to a percentage Percentile refers to a score © aSup-2011 44 Sampling Survey CENTRAL TENDENCY Mean, Median, and Mode © aSup-2011 45 Sampling Survey OVERVIEW The general purpose of descriptive statistical methods is to organize and summarize a set score Perhaps the most common method for summarizing and describing a distribution is to find a single value that defines the average score and can serve as a representative for the entire distribution In statistics, the concept of an average or representative score is called central tendency © aSup-2011 46 Sampling Survey OVERVIEW Central tendency has purpose to provide a single summary figure that best describe the central location of an entire distribution of observation It also help simplify comparison of two or more groups tested under different conditions There are three most commonly used in education and the behavioral sciences: mode, median, and arithmetic mean © aSup-2011 47 Sampling Survey The MODE A common meaning of mode is ‘fashionable’, and it has much the same implication in statistics In ungrouped distribution, the mode is the score that occurs with the greatest frequency In grouped data, it is taken as the midpoint of the class interval that contains the greatest numbers of scores The symbol for the mode is Mo © aSup-2011 48 Sampling Survey The MEDIAN The median of a distribution is the point along the scale of possible scores below which 50% of the scores fall and is there another name for P50 Thus, the median is the value that divides the distribution into halves It symbols is Mdn © aSup-2011 49 Sampling Survey The ARITHMETIC MEAN The arithmetic mean is the sum of all the scores in the distribution divided by the total number of scores Many people call this measure the average, but we will avoid this term because it is sometimes used indiscriminately for any measure of central tendency For brevity, the arithmetic mean is usually called the mean © aSup-2011 50 Sampling Survey The ARITHMETIC MEAN Some symbolism is needed to express the mean mathematically. We will use the capital letter X as a collective term to specify a particular set of score (be sure to use capital letters; lower-case letters are used in a different way) We identify an individual score in the distribution by a subscript, such as X1 (the first score), X8 (the eighth score), and so forth You remember that n stands for the number in a sample and N for the number in a population © aSup-2011 51 Sampling Survey Properties of the Mode The mode is easy to obtain, but it is not very stable from sample to sample Further, when quantitative data are grouped, the mode maybe strongly affected by the width and location of class interval There may be more than one mode for a particular set of scores. In rectangular distribution the ultimate is reached: every score share the honor! For these reason, the mean or the median is often preferred with numerical data However, the mode is the only measure that can be used for data that have the character of a nominal scale © aSup-2011 52 Sampling Survey Properties of the Mean Unlike the other measures of central tendency, the mean is responsive to the exact position of reach score in the distribution Inspect the basic formula ΣX/n. Increasing or decreasing the value of any score changes ΣX and thus also change the value of the mean The mean may be thought of as the balance point of the distribution, to use a mechanical analogy. There is an algebraic way of stating that the mean is the balance point: ( X X ) 0 © aSup-2011 53 Sampling Survey Properties of the Mean The sums of negative deviation from the mean exactly equals the sum of the positive deviation The mean is more sensitive to the presence (or absence) of scores at the extremes of the distribution than are the median or (ordinarily the mode When a measure of central tendency should reflect the total of the scores, the mean is the best choice because it is the only measure based of this quantity © aSup-2011 54 Sampling Survey The MEAN of Ungrouped Data The mean (M), commonly known as the arithmetic average, is compute by adding all the scores in the distribution and dividing by the number of scores or cases M= © aSup-2011 ΣX N 55 Sampling Survey The MEAN of Grouped Data When data come to us grouped, or M when they are too lengthy for comfortable addition without the aid of a calculating machine, or X when we are going to 20 - 24 group them for other purpose anyway, 15 - 19 we find it more convenient 10 - 14 to apply another formula 5-9 for the mean: 0-4 © aSup-2011 Σ f.Xc = N Xc f f.Xc 22 17 12 7 2 1 4 7 5 3 22 68 84 35 6 56 Sampling Survey The MEDIAN of Ungrouped Data Method 1: When N is an odd number list the score in order (lowest to highest), and the median is the middle score in the list Method 2: When N is an even number list the score in order (lowest to highest), and then locate the median by finding the point halfway between the middle two scores © aSup-2011 57 Sampling Survey The MEDIAN of Ungrouped Data Method 3: When there are several scores with the same value in the middle of the distribution 1, 2, 2, 3, 4, 4, 4, 4, 4, 5 There are 10 scores (an even number), so you normally would use method 2 and average the middle pair to determine the median By this method, the median would be 4 © aSup-2011 58 Sampling Survey f f 5 5 4 4 3 3 2 2 1 1 0 © aSup-2011 1 2 3 4 5 X 0 1 2 3 4 5 X 59 Sampling Survey The MEDIAN of Grouped Data There are 10 scores (an even number), so you normally would use method 2 and average the middle pair to determine the median. By this method the median would be 4 In many ways, this is a perfectly legitimate value for the median. However when you look closely at the distribution of scores, you probably get the clear impression that X = 4 is not in the middle The problem comes from the tendency to interpret the score of 4 as meaning exactly 4.00 instead of meaning an interval from 3.5 to 4.5 © aSup-2011 60 Sampling Survey THE MODE The word MODE means the most common observation among a group of scores In a frequency distribution, the mode is the score or category that has the greatest frequency © aSup-2011 61 Sampling Survey SELECTING A MEASURE OF CENTRAL TENDENCY How do you decide which measure of central tendency to use? The answer depends on several factors Note that the mean is usually the preferred measure of central tendency, because the mean uses every score score in the distribution, it typically produces a good representative value The goal of central tendency is to find the single value that best represent the entire distribution © aSup-2011 62 Sampling Survey SELECTING A MEASURE OF CENTRAL TENDENCY Besides being a good representative, the mean has the added advantage of being closely related to variance and standard deviation, the most common measures of variability This relationship makes the mean a valuable measure for purposes of inferential statistics For these reasons, and others, the mean generally is considered to be the best of the three measure of central tendency © aSup-2011 63 Sampling Survey SELECTING A MEASURE OF CENTRAL TENDENCY But there are specific situations in which it is impossible to compute a mean or in which the mean is not particularly representative It is in these condition that the mode an the median are used © aSup-2011 64 Sampling Survey WHEN TO USE THE MEDIAN 1. Extreme scores or skewed distribution When a distribution has a (few) extreme score(s), score(s) that are very different in value from most of the others, then the mean may not be a good representative of the majority of the distribution. The problem comes from the fact that one or two extreme values can have a large influence and cause the mean displaced © aSup-2011 65 Sampling Survey WHEN TO USE THE MEDIAN 2. Undetermined values Occasionally, we will encounter a situation in which an individual has an unknown or undetermined score Person Time (min.) 1 2 3 4 5 6 © aSup-2011 8 11 12 13 17 Never finished Notice that person 6 never complete the puzzle. After one hour, this person still showed no sign of solving the puzzle, so the experimenter stop him or her 66 Sampling Survey WHEN TO USE THE MEDIAN 2. Undetermined values There are two important point to be noted: The experimenter should not throw out this individual’s score. The whole purpose to use a sample is to gain a picture of population, and this individual tells us about that part of the population cannot solve this puzzle This person should not be given a score of X = 60 minutes. Even though the experimenter stopped the individual after 1 hour, the person did not finish the puzzle. The score that is recorded is the amount of time needed to finish. For this individual, we do not know how long this is © aSup-2011 67 Sampling Survey WHEN TO USE THE MEDIAN 3. Open-ended distribution A distribution is said to be open-ended when there is no upper limit (or lower limit) for one of the categories Number of children (X) 5 or more 4 3 2 1 0 © aSup-2011 f 3 2 2 3 6 4 Notice that is impossible to compute a mean for these data because you cannot find ΣX 68 Sampling Survey WHEN TO USE THE MEDIAN 4. Ordinal scale when score are measured on an ordinal scale, the median is always appropriate and is usually the preferred measure of central tendency © aSup-2011 69 Sampling Survey WHEN TO USE THE MODE Nominal scales Because nominal scales do not measure quantity, it is impossible to compute a mean or a median for data from a nominal scale Discrete variables indivisible categories Describes shape the mode identifies the location of the peak (s). If you are told a set of exam score has a mean of 72 and a mode of 80, you should have a better picture of the distribution than would be available from mean alone © aSup-2011 70 Sampling Survey CENTRAL TENDENCY AND THE SHAPE OF THE DISTRIBUTION Because the mean, the median, and the mode are all trying to measure the same thing (central tendency), it is reasonable to expect that these three values should be related There are situations in which all three measures will have exactly the same or different value The relationship among the mean, median, and mode are determined by the shape of the distribution © aSup-2011 71 Sampling Survey SYMMETRICAL DISTRIBUTION SHAPE For a symmetrical distribution, the right-hand side will be a mirror image of the left-hand side By definition, the mean and the median will be exactly at the center because exactly half of the area in the graph will be on either side of the center Thus, for any symmetrical distribution, the mean and the median will be the same © aSup-2011 72 Sampling Survey SYMMETRICAL DISTRIBUTION SHAPE If a symmetrical distribution has only one mode, it will also be exactly in the center of the distribution. All three measures of central tendency will have same value A bimodal distribution will have the mean and the median together in the center with the modes on each side A rectangular distribution has no mode because all X values occur with the same frequency. Still the mean and the median will be in the center and equivalent in value © aSup-2011 73 Sampling Survey MEASURES OF VARIABILITY © aSup-2011 74 Sampling Survey Knowing the central value of a set of measurement tells us much, but it does not by any means give us the total pictures of the sample we have measured Two groups of six-year-old children may have the same average IQ of 105. One group contain no individuals with IQs below 95 or above 115, and that the other includes individuals with IQs ranging from 75 to 135 We recognize immediately that there is a decided difference between the two groups in variability or dispersion © aSup-2011 75 Sampling Survey 75 85 95 105 115 125 135 The BLUE group is decidedly more homogenous than the RED group with respect to IQ © aSup-2011 76 Sampling Survey Purpose of Measures of Variability To explain and to illustrate the methods of indicating degree of variability or dispersion by the use of single numbers The three customary values to indicate variability are ○ The total range ○ The semi-interquartile range Q, and ○ The standard deviation S © aSup-2011 77 Sampling Survey The TOTAL RANGE The total range is the easiest and most quickly ascertained value, but it also the most unreliable The BLUE group (from an IQ of 95 to one of 115) is 20 points. The range of RED group from 75 to 135, or 60 points The range is given by the highest score minus the lowest score The RED group has three times the range of the BLUE group © aSup-2011 78 Sampling Survey The SEMI-INTERQUARTILE RANGE Q The Q is one-half the range of the middle 50 percent of the cases First we find by interpolation the range of the middle 50 percent, or interquartile range, the divide this range into 2 © aSup-2011 79 Sampling Survey Low Middle Quarter Lowest Quarter Q1 High Middle Quarter Q2 Highest Quarter Q3 Q2 – Q1 Q3 – Q2 Q3 – Q1 = 2Q Q= © aSup-2011 Q3 – Q1 2 80 Sampling Survey The STANDARD DEVIATION S Standard deviation is by far the most commonly used indicator of degree of dispersion and is the most dependable estimate of the variability in the population from which the sample came The S is a kind of average of all deviation from the mean S= © aSup-2011 √ ∑ x2 n-1 81 Sampling Survey As a general concept, the standard deviation is often symbolized by SD, but much more often by simply S In verbal terms, a S is the square root of the arithmetic mean of the squared deviations of measurements from their means © aSup-2011 82 Sampling Survey Interpretation of a Standard Deviation The usual and most accepted interpretation of a S is in percentage of cases included within the range from one S below the mean to one S above the mean In a normal distribution the range from -1σ to +1σ contains 68,27 percent of the cases If the mean = 29,6 and S = 10,45; we say about two-third of the cases lies from 19,15 to 40,05 © aSup-2011 83 Sampling Survey Interpretation of a Standard Deviation One of the most common source of variance in statistical data is individual differences, where each measurement comes from a different person © aSup-2011 84 Sampling Survey Interpretation of a Standard Deviation Giving a test of n items to a group of person Before the first item is given to the group, as far as any information from this test is concerned, the individuals are all alike. There is no variance Now administer the first item to the group. Some pass it and some fail. Some now have score of 1, and some have scores of zero There are two groups of individuals. There is much variation, this much variance © aSup-2011 85 Sampling Survey Interpretation of a Standard Deviation Give a second item. Of those who passed the first, some will past the second and some will fail it. Etc. There are now three possible scores : 0, 1, and 2. More variance has been introduced Carry the illustration further, adding item by item The differences between scores will keep increasing, and also, by computation, the variance and variability © aSup-2011 86 Sampling Survey Another rough check is to compare the S obtained with the total range of measurement In very large samples (N=500 or more) the S is about one-sixth of the total range In other word, the total range is about six S In smaller samples the ratio of range to S can be expected to be smaller (see Guilford & Fruchter p.71) © aSup-2011 87 Sampling Survey Ratios of the Total Range to the Standard Deviation in a Distribution for Different Values of N Rough check for a computed SD ○ The actual percentage of a case between +1 SD and 1 SD deviates 68 percents ○ In very large sample (N = 500 or more) the SD as about one-sixth of the total range N Range/S N Range/S N Range/S 5 2.3 40 4.3 400 5.9 10 3.1 50 4.5 500 6.1 15 3.5 100 5.0 700 6.3 20 3.7 200 5.5 1000 6.5 © aSup-2011 88 Sampling Survey z-Score: Location of Scores and Standardized Distribution © aSup-2011 89 Sampling Survey PREVIEW In particular, we will convert each individual score into a new, standardize score, so that the standardized score provides a meaningful description of its exact location within the distribution We will use the mean as a reference point to determine whether the individual is above or below average The standard deviation will serve as yardstick for measuring how much an individual differ from the group average © aSup-2011 90 Sampling Survey EXAMPLE Suppose you received a score of X = 76 on a statistics exam. How did you do? It should be clear that you need more information to predict your grade Your score could be one of the best score in class, or it might be the lowest score in the distribution © aSup-2011 91 Sampling Survey X = 76, the best score or the lowest score? To find the location of your score, you must have information about the other score in the distribution If the mean were μ = 70 you would be in better position than the mean were μ = 86 Obviously, your position relative to the rest of the class depends on mean © aSup-2011 92 Sampling Survey X = 76 and μ = 70 However, the mean by itself is not sufficient to tell you the exact location of your score At this point, you know that your score is six points above the mean Six points may be a relatively big distance and you may have one of the highest score in class, or Six points may be a relatively small distance and you are only slightly above the average © aSup-2011 93 Sampling Survey THE z-SCORE FORMULA X-μ z= σ © aSup-2011 94 Sampling Survey z-Score and Location In a Distribution One of the primary purpose of a z-Score is to describe the exact location of a score within a distribution The z-Score accomplishes this goal by transforming each X value into a signed number (+ or -), so that: ○ The sign tells whether the score is located above (+) or below (-) the mean, and ○ The number tells the distance between the score and the mean in term of the number of standard deviation © aSup-2011 95 Sampling Survey If every X value is transformed into a z-score, then the distribution of z-score will have the following properties: Shape of the z-score distribution will be the same as the original distribution of raw scores. Each individual has exactly the same relative position in the X distribution and the z-score distribution The Mean will always have a mean of zero. The subject with score same as the mean is transformed into z = 0 The Standard Deviation will always have a standard deviation of 1. The subject with score same as the +1S from the mean is transformed into z = +1 © aSup-2011 96 Sampling Survey PROBABILITY and NORMAL DISTRIBUTION σ μ In simpler terms, the normal distribution is symmetrical with a single mode in the middle. The frequency tapers off as you move farther from the middle in either direction © aSup-2011 97 Sampling Survey THE DISTRIBUTION OF SAMPLE MEANS © aSup-2011 98 Sampling Survey OVERVIEW Whenever a score is selected from a population, you should be able to compute a zscore And, if the population is normal, you should be able to determine the probability value for obtaining any individual score In a normal distribution, a z-score of +2.00 correspond to an extreme score out in the tail of the distribution, and a score at least large has a probability of only p = .0228 © aSup-2011 99 Sampling Survey THE DISTRIBUTION OF SAMPLE MEANS Two separate samples probably will be different even though they are taken from the same population The sample will have different individual, different scores, different means, and so on The distribution of sample means is the collection of sample means for all the possible random samples of a particular size (n) that can be obtained from a population © aSup-2011 100 Sampling Survey COMBINATION n! nCr = r! (n-r)! Consider a population that consist of 5 scores: 3, 4, 5, 6, and 7 Mean population = ? Construct the distribution of sample means for n = 1, n = 2, n = 3, n = 4, n = 5 © aSup-2011 101 Sampling Survey SAMPLING DISTRIBUTION … is a distribution of statistics obtained by selecting all the possible samples of a specific size from a population CENTRAL LIMIT THEOREM For any population with mean μ and standard deviation σ, the distribution of sample means for sample size n will have a mean of μ and a standard deviation of σ/√n and will approach a normal distribution as n approaches infinity © aSup-2011 102 Sampling Survey The STANDARD ERROR OF MEAN The value we will be working with is the standard deviation for the distribution of sample means, and it called the σM Remember the sampling error There typically will be some error between the sample and the population The σM measures exactly how much difference should be expected on average between sample mean M and the population mean μ © aSup-2011 103 Sampling Survey The MAGNITUDE of THE σM Determined by two factors: ○The size of the sample, and ○The standard deviation of the population from which the sample is selected M © aSup-2011 n 104 Sampling Survey PROBABILITY AND THE DISTRIBUTION OF SAMPLE MEANS The primary use of the standard distribution of sample means is to find the probability associated with any specific sample Because the distribution of sample means present the entire set of all possible Ms, we can use proportions of this distribution to determine probabilities © aSup-2011 105 Sampling Survey EXAMPLE The population of scores on the SAT forms a normal distribution with μ = 500 and σ = 100. If you take a random sample of n = 16 students, what is the probability that sample mean will be greater that M = 540? σM = σ √n = 25 M-μ z= σ M = 1.6 z = 1.6 Area C p = .0548 © aSup-2011 106 Sampling Survey © aSup-2011 107 Sampling Survey Tipe-tipe Pengambilan Sampel Desain pengambilan sampel random/probabilita Untuk desain pengambilan sampel random atau probabilita, setiap elemen dalam populasi harus memiliki kesempatan yang sama dan bebas untuk dipilih sebagai sampel. © aSup-2011 108 Sampling Survey Terdapat dua keuntungan dari sampel acak/probabilita: 1. Sebagai representasi pengambilan sampel populasi total, penarikan kesimpulan dari sampel seperti ini dapat digeneralisasikan ke pengambilan sampel populasi total. 2. Pengujian statistik yang didasarkan pada teori probabilita dapat diaplikasikan hanya pada data yang dikumpulkan dari sampel acak. © aSup-2011 109 Sampling Survey Metode-metode mengambil sampel acak The fishbowl draw: jika jumlah total populasi kecil, prosedur yang mudah adalah menuliskan setiap elemen pada secarik kertas tiap elemennya, masukan pada sebuah kotak, dan ambil satu-persatu tanpa dilihat, sampai kertas yang dipilih sesuai dengan ukuran sampel yang telah ditetapkan © aSup-2011 110 Sampling Survey Metode-metode mengambil sampel acak Program komputer Tabel acak: kebanyakan buku metodologi penelitian dan statistik memasukan tabel acak pada bagian lampirannya. Sampel dapat dipilih dengan menggunakan tabel sesuai prosedur © aSup-2011 111