Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
History of statistics wikipedia , lookup
Degrees of freedom (statistics) wikipedia , lookup
Foundations of statistics wikipedia , lookup
Confidence interval wikipedia , lookup
Taylor's law wikipedia , lookup
Bootstrapping (statistics) wikipedia , lookup
Statistical inference wikipedia , lookup
• Inference about the mean of a population of
measurements (m) is based on the standardized
value of the sample mean (Xbar).
• The standardization involves subtracting the
mean of Xbar and dividing by the standard
deviation of Xbar – recall that
– Mean of Xbar is m ; and
– Standard deviation of Xbar is s/sqrt(n)
• Thus we have (Xbar - m )/(s/sqrt(n)) which has a
Z distribution if:
– Population is normal and s is known ; or if
– n is large so CLT takes over…
• But what if s is unknown?? Then this
standardized Xbar doesn’t have a Z distribution
anymore, but a so-called t-distribution with n-1
degrees of freedom…
• Since s is unknown, the standard deviation of
Xbar, s/sqrt(n), is unknown. We estimate it by
the so-called standard error of Xbar, s/sqrt(n),
where s=the sample standard deviation.
• There is a t-distribution for every value of the
sample size; we’ll use t(k) to stand for the
particular t-distribution with k degrees of
freedom. There are some properties of these tdistributions that we should note…
• Every t-distribution looks like a N(0,1) distribution; i.e., it
is centered and symmetric around 0 and has the same
characteristic “bell” shape… however, the standard
deviation of t(k) {sqrt(k/(k-2))} is greater than 1, the s.d.
of Z so the t-distribution density curve is more spread out
than Z. Probabilities involving r.v.s that have the t(k)
distributions are given by areas under the t(k) density
curve … the pt function in R gives us the probabilities we
need…
pt(q, k) = Prob(t(k)<= q)
• The good news is that everything we’ve already
learned about constructing confidence intervals
and testing hypotheses about m carries through
under the assumption of unknown s …
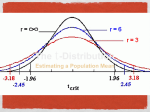
• So e.g., a 95% confidence interval for m based
on a SRS from a population with unknown s is
Xbar +/- t*(s.e.(Xbar))
Recall that s.e.(Xbar) = s/sqrt(n). Here t* is the
appropriate quantile from the t-distribution so that
the area between –t* and +t* is .95
• As we did before, if we change the level of
confidence then the value of t* must change
appropriately…
• e.g., for 95% confidence with df=12, qt(.975,12)
gives the correct t* ….
• Similarly, we may test hypotheses using this tdistributed standardized Xbar… e.g., to test the
H0: m =m0 against Ha: m >m0 we use
(Xbar - m0)/(s/sqrt(n)) which has a tdistribution with n-1 df, assuming the null
hypothesis is true. See the last page of these
notes for a summary of hypothesis testing in the
case of “the one-sample t-test” …
• HW: Read the online Chapter 10 on Hypothesis
Testing with Standard Errors (start with the first 3
sections… the third deals with the t-distribution).
Work on the second problem set handout…
• Note: a statistic is robust if it is insensitive to
violations of the assumptions made when the
statistic is used. For example, the t-statistic
requires normality of the population… how
sensitive is the t-statistic to violations of
normality?? Consider these practical guidelines
for inference on a single mean:
– If the sample size is < 15, use the t procedures if the
data are close to normal.
– If the sample size is >= 15 then unless there is strong
non-normality or outliers, t procedures are OK
– If the sample size is large (say n >= 40) then even if
the distribution is skewed, t procedures are OK