Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Data assimilation wikipedia , lookup
Time series wikipedia , lookup
Interaction (statistics) wikipedia , lookup
Instrumental variables estimation wikipedia , lookup
Choice modelling wikipedia , lookup
Regression toward the mean wikipedia , lookup
Regression analysis wikipedia , lookup
Measurement Math
DeShon - 2006
Univariate Descriptives
Mean
Variance, standard deviation
Var ( x) S
2
X
i
X X i X
n 1
S
X
i
X X i X
n 1
Skew & Kurtosis
If normal distribution, mean and SD are
sufficient statistics
Normal Distribution
Univariate Probability Functions
Bivariate Descriptives
Mean and SD of each variable and the
correlation (ρ) between them are
sufficient statistics for a bivariate normal
distribution
Distributions are abstractions or models
Used to simplify
Useful to the extent the assumptions of the
model are met
2D – Ellipse or Scatterplot
Galton’s
Original
Graph
3D Probability Density
Covariance
Covariance is the extent to which two variables
co-vary from their respective means
X
Cov( x, y )
i
X Yi Y
n 1
Case
X
Y
x=X-3
y =Y-4
xy
1
1
2
-2
-2
4
2
2
3
-1
-1
1
3
3
3
0
-1
0
4
6
8
3
4
12
Sum
17
Cov(X,Y) =
17/(4-1) = 5.667
Covariance
Covariance ranges from negative to positive
infinity
Variance - Covariance matrix
Variance is the covariance of a variable with itself
Var ( X ) Cov( XY ) Cov( XZ )
Cov( XY ) Var (Y ) Cov(YZ )
Cov( XZ ) Cov(YZ
Var ( Z )
Correlation
Covariance is an unbounded statistic
Standardize the covariance with the
standard deviations
-1 ≤ r ≤ 1
rp
Cov( X , Y )
Var ( X )Var (Y )
Correlation Matrix
Table 1. Descriptive Statistics for the Variables
Correlations
Variables
Mean
s.d
1
2
3
4
5
6
7
8
9
Self-rated cog ability
4.89
.86
.81
Self-enhancement
4.03
.85
.34
.79
Individualism
4.92
.89
.40
.41
.78
Horiz individualism
5.19
1.05
.41
.25
.82
.80
Vert individualism
4.65
1.11
.25
.42
.84
.37
.72
Collectivism
5.05
.74
.21
.11
.08
.06
.06
.72
21.00
1.70
.12
.01
.17
.13
.16
.01
--
Gender
1.63
.49
-.16
-.06
-.11
.07
-.11
-.02
-.01
Academic seniority
2.17
1.01
.17
.07
.22
.23
.14
.06
.45
.12
--
10.71
1.60
.17
-.02
.08
.11
.03
.07
-.02
-.07
.12
Age
Actual cog ability
10
--
--
Notes: N = 608; gender was coded 1 for male and 2 for female. Reliabilities (Coefficient alpha) are on the diagonal.
Coefficient of Determination
r2 = percentage of variance in Y accounted
for by X
Ranges from 0 to 1 (positive only)
This number is a meaningful proportion
Other measures of association
Point Biserial Correlation
Biserial Correlation
Tetrachoric Correlation
Polychoric Correlation
binary variables
ordinal variables
Odds Ratio
binary variables
Point Biserial Correlation
Used when one variable is a natural (real)
dichotomy (two categories) and the other
variable is interval or continuous
Just a normal correlation between a
continuous and a dichotomous variable
Biserial Correlation
When one variable is an artificial
dichotomy (two categories) and the
criterion variable is interval or continuous
Tetrachoric Correlation
Estimates what the
correlation between two
binary variables would
be if you could measure
variables on a
continuous scale.
Example: difficulty
walking up 10 steps and
difficulty lifting 10 lbs.
Difficulty Walking Up 10 Steps
no
d
d
if
iff
fi
L e ve
Tetrachoric Correlation
Assumes that both “traits”
are normally distributed
Correlation, r, measures
how narrow the ellipse is.
a, b, c, d are the
proportions in each
quadrant
d
c
a
b
Tetrachoric Correlation
For α = ad/bc,
Approximation 1:
1
Q
1
Approximation 2 (Digby):
1
Q 34
1
34
Tetrachoric Correlation
Example:
Tetrachoric correlation =
0.61
Pearson correlation =
0.41
o
o
Assumes threshold is
the same across people
Strong assumption that
underlying quantity of
interest is truly
continuous
Difficulty Walking Up
10 Steps
Difficulty
Lifting 10 lb.
No
Yes
No
40
10
50
Yes
20
30
50
60
40
100
Odds Ratio
Measure of association
between two binary
variables
Risk associated with x
given y.
Example:
odds of difficulty walking
up 10 steps to the odds of
difficulty lifting 10 lb:
OR
p1 /(1 p1 )
p2 /(1 p2 )
ad
bc
( 40 )( 30 )
( 20 )(10 )
6
Pros and Cons
Tetrachoric correlation
Odds Ratio
same interpretation as Spearman and Pearson
correlations
“difficult” to calculate exactly
Makes assumptions
easy to understand, but no “perfect” association that
is manageable (i.e. {∞, -∞})
easy to calculate
not comparable to correlations
May give you different results/inference!
Dichotomized Data:
A Bad Habit of Psychologists
Sometimes perfectly good quantitative data is
made binary because it seems easier to talk
about "High" vs. "Low"
The worst habit is median split
Usually the High and Low groups are mixtures of the
continua
Rarely is the median interpreted rationally
See references
Cohen, J. (1983) The cost of dichotomization. Applied
Psychological Measurement, 7, 249-253.
McCallum, R.C., Zhang, S., Preacher, K.J., Rucker, D.D. (2002)
On the practice of dichotomization of quantitative variables.
Psychological Methods, 7, 19-40.
Simple Regression
The simple linear regression MODEL is:
y = b 0 + b 1 x +e
x
y
e
describes how y is related to x
b0 and b1 are called parameters of the model.
e is a random variable called the error term.
E ( y) yˆ b 0 b1 x
Simple Regression
E ( y) b 0 b1 x
Graph of the regression equation is a straight
line.
β0 is the population y-intercept of the
regression line.
β1 is the population slope of the regression
line.
E(y) is the expected value of y for a given x
value
Simple Regression
E(y)
Regression line
Intercept
b0
Slope b1
is positive
x
Simple Regression
E(y)
Regression line
Intercept
b0
Slope b1
is 0
x
Estimated Simple Regression
The estimated simple linear regression equation
is:
ŷ b0 b1 x
The graph is called the estimated regression line.
b0 is the y intercept of the line.
b1 is the slope of the line.
ŷ is the estimated/predicted value of y for a given x
value.
Estimation process
Regression Model
y = b0 + b1x +e
Regression Equation
E(y) = b0 + b1x
Unknown Parameters
b0, b1
b0 and b1
provide estimates of
b0 and b1
Sample Data:
x
y
x1
y1
.
.
.
.
xn yn
Estimated
Regression Equation
ŷ b0 b1 x
Sample Statistics
b0, b1
Least Squares Estimation
Least Squares Criterion
where:
min (y i y i ) 2
yi = observed value of the dependent
variable for the ith observation
^
yi = predicted/estimated value of the
dependent variable for the ith observation
Least Squares Estimation
Estimated Slope
b1
x y ( x y ) / n Cov( X , Y )
Var ( X )
x ( x ) / n
i
i
i
2
i
Estimated y-Intercept
b0 y bx
i
2
i
Model Assumptions
1. X is measured without error.
2. X and e are independent
3. The error e is a random variable with mean
of zero.
4. The variance of e , denoted by 2, is the
same for all values of the independent
variable (homogeneity of error variance).
5. The values of e are independent.
6. The error e is a normally distributed random
variable.
Example: Consumer Warfare
Number of Ads (X)
1
3
2
1
3
Purchases (Y)
14
24
18
17
27
Example
Slope for the Estimated Regression Equation
b1 = 220 - (10)(100)/5 = 5
24 - (10)2/5
y-Intercept for the Estimated Regression
Equation
b0 = 20 - 5(2) = 10
Estimated Regression Equation
y^ = 10 + 5x
Example
Scatter plot with regression line
30
25
Purchases
20
^
y = 10 + 5x
15
10
5
0
0
1
2
# of Ads
3
4
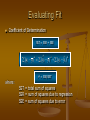
Evaluating Fit
Coefficient of Determination
SST = SSR + SSE
2
2
^ )2
( y i y ) ( y^i y ) ( y i y
i
where:
r2 = SSR/SST
SST = total sum of squares
SSR = sum of squares due to regression
SSE = sum of squares due to error
Evaluating Fit
Coefficient of Determination
r2 = SSR/SST = 100/114 = .8772
The regression relationship is very strong
because 88% of the variation in number
of purchases can be explained by the
linear relationship with the between the
number of TV ads
Mean Square Error
An Estimate of
2
The mean square error (MSE) provides the
estimate of 2,
S2 = MSE = SSE/(n-2)
where:
SSE (yi yˆi ) 2 ( yi b0 b1 xi ) 2
Standard Error of Estimate
An Estimate of S
To estimate we take the square root of 2.
The resulting S is called the standard error of the
estimate.
Also called “Root Mean Squared Error”
SSE
s MSE
n2
Linear Composites
Linear composites are fundamental to
behavioral measurement
Prediction & Multiple Regression
Principle Component Analysis
Factor Analysis
Confirmatory Factor Analysis
Scale Development
Ex: Unit-weighting of items in a test
Test = 1*X1 + 1*X2 + 1*X3 + … + 1*Xn
Linear Composites
Sum Scale
Unit-weighted linear composite
ScaleA = X1 + X2 + X3 + … + Xn
ScaleA = 1*X1 + 1*X2 + 1*X3 + … + 1*Xn
Weighted linear composite
ScaleA = b1X1 + b2X2 + b3X3 + … + bnXn
Variance of a weighted Composite
X
Y
Y
Var(X)
Cov(XY)
Y
Cov(XY)
Var(Y)
Var ( X Y ) w12 *Var ( X 1 ) w22 *Var ( X 2 ) 2w1w2 * Cov( X , Y )
Effective vs. Nominal Weights
Nominal weights
The desired weight assigned to each
component
Effective weights
the actual contribution of each component to
the composite
function of the desired weights, standard
deviations, and covariances of the
components
Principles of Composite Formation
Standardize before combining!!!!!
Weighting doesn’t matter much when the
correlations among the components are
moderate to large
As the number of components increases,
the importance of weighting decreases
Differential weights are difficult to
replicate/cross-validate
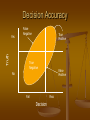
Decision Accuracy
Truth
Yes
False
Negative
True
Positive
True
Negative
False
Positive
No
Fail
Pass
Decision
Signal Detection Theory
Polygraph Example
Sensitivity, etc…