Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
CSE 326: Data Structures
Binary Search Trees
Today’s Outline
• Dictionary ADT / Search ADT
• Quick Tree Review
• Binary Search Trees
ADTs Seen So Far
• Stack
– Push
– Pop
• Queue
– Enqueue
– Dequeue
• Priority Queue
– Insert
– DeleteMin
Then there is decreaseKey…
The Dictionary ADT
• Data:
– a set of
(key, value)
pairs
• Operations:
– Insert (key,
value)
– Find (key)
– Remove (key)
•
jfogarty
James
Fogarty
CSE 666
•
phenry
Peter
Henry
CSE 002
•
boqin
Bo
Qin
CSE 002
insert(jfogarty, ….)
find(boqin)
• boqin
Bo, Qin, …
The Dictionary ADT is also
called the “Map ADT”
A Modest Few Uses
•
•
•
•
•
Sets
Dictionaries
Networks
Operating systems
Compilers
: Router tables
: Page tables
: Symbol tables
Probably the most widely used ADT!
5
Implementations
insert
• Unsorted Linked-list
• Unsorted array
• Sorted array
find
delete
Tree Calculations
Recall: height is max
number of edges from
root to a leaf
t
Find the height of the
tree...
runtime:
7
Tree Calculations Example
A
How high is this tree?
B
D
C
E
F
G
H
J
M
K
I
L
L
N
8
More Recursive Tree Calculations:
Tree Traversals
A traversal is an order for
visiting all the nodes of a tree
+
*
Three types:
• Pre-order: Root, left subtree, right subtree
• In-order:
Left subtree, root, right subtree
• Post-order: Left subtree, right subtree, root
2
5
4
(an expression tree)
Inorder Traversal
void traverse(BNode t){
if (t != NULL)
traverse (t.left);
process t.element;
traverse (t.right);
}
}
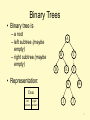
Binary Trees
• Binary tree is
– a root
– left subtree (maybe
empty)
– right subtree (maybe
empty)
A
B
C
D
E
• Representation:
F
G
H
Data
left
right
pointer pointer
I
J
11
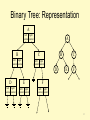
Binary Tree: Representation
A
left right
pointer pointer
A
B
C
left right
pointer pointer
left right
pointer pointer
B
D
D
E
F
left right
pointer pointer
left right
pointer pointer
left right
pointer pointer
C
E
F
12
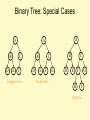
Binary Tree: Special Cases
A
B
D
C
E
A
A
F
Complete Tree
B
D
B
C
E
F
G
D
C
E
F
G
Perfect Tree
H
I
Full Tree
Binary Tree: Some Numbers!
For binary tree of height h:
– max # of leaves:
– max # of nodes:
– min # of leaves:
– min # of nodes:
Average Depth for N nodes?
Binary Search Tree Data Structure
• Structural property
– each node has 2 children
– result:
• storage is small
• operations are simple
• average depth is small
8
5
11
• Order property
– all keys in left subtree smaller
2
than root’s key
– all keys in right subtree larger
than root’s key
– result: easy to find any given key 4
• What must I know about what I store?
6
10
7
9
12
14
13
Example and Counter-Example
5
8
4
1
8
7
5
11
3
BINARY SEARCH TREES?
2
7
4
11
6
10
15
18
20
21
Find in BST, Recursive
Node Find(Object key,
Node root) {
if (root == NULL)
return NULL;
10
5
15
2
9
7
Runtime:
if (key < root.key)
return Find(key,
root.left);
else if (key > root.key)
return Find(key,
root.right);
else
return root;
20
17 30
}
Find in BST, Iterative
Node Find(Object key,
Node root) {
10
while (root != NULL &&
root.key != key) {
if (key < root.key)
root = root.left;
else
root = root.right;
}
5
15
2
9
7
return root;
}
Runtime:
20
17 30
Insert in BST
10
5
Insert(13)
Insert(8)
Insert(31)
15
2
9
7
20
17 30
Insertions happen only
at the leaves – easy!
Runtime:
BuildTree for BST
• Suppose keys 1, 2, 3, 4, 5, 6, 7, 8, 9 are
inserted into an initially empty BST.
Runtime depends on the order!
– in given order
– in reverse order
– median first, then left median, right median, etc.
Bonus: FindMin/FindMax
• Find minimum
10
5
• Find maximum
15
2
9
7
20
17 30
Deletion in BST
10
5
15
2
9
7
20
17 30
Why might deletion be harder than insertion?
Lazy Deletion
Instead of physically deleting
nodes, just mark them as
deleted
10
+ simpler
+ physical deletions done in
batches
+ some adds just flip deleted
flag
– extra memory for “deleted” flag
– many lazy deletions = slow
finds
– some operations may have to
be modified (e.g., min and
max)
5
15
2
9
7
20
17 30
Non-lazy Deletion
• Removing an item disrupts the tree
structure.
• Basic idea: find the node that is to be
removed. Then “fix” the tree so that it is
still a binary search tree.
• Three cases:
– node has no children (leaf node)
– node has one child
– node has two children
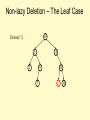
Non-lazy Deletion – The Leaf Case
10
Delete(17)
5
15
2
9
7
20
17 30
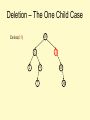
Deletion – The One Child Case
10
Delete(15)
5
15
2
9
7
20
30
Deletion – The Two Child Case
10
Delete(5)
5
20
2
9
7
What can we replace 5 with?
30
Deletion – The Two Child Case
Idea: Replace the deleted node with a value
guaranteed to be between the two child subtrees
Options:
• succ from right subtree: findMin(t.right)
• pred from left subtree : findMax(t.left)
Now delete the original node containing succ or pred
• Leaf or one child case – easy!
Finally…
10
7 replaces 5
2
7
20
9
Original node containing
7 gets deleted
30
Balanced BST
Observation
• BST: the shallower the better!
• For a BST with n nodes
•
– Average height is O(log n)
– Worst case height is O(n)
Simple cases such as insert(1, 2, 3, ..., n)
lead to the worst case scenario
Solution: Require a Balance Condition that
1. ensures depth is O(log n)
– strong enough!
2. is easy to maintain
– not too strong!
Potential Balance Conditions
1. Left and right subtrees of the root
have equal number of nodes
2. Left and right subtrees of the root
have equal height
Potential Balance Conditions
3. Left and right subtrees of every node
have equal number of nodes
4. Left and right subtrees of every node
have equal height
CSE 326: Data Structures
AVL Trees
Balanced BST
Observation
• BST: the shallower the better!
• For a BST with n nodes
•
– Average height is O(log n)
– Worst case height is O(n)
Simple cases such as insert(1, 2, 3, ..., n)
lead to the worst case scenario
Solution: Require a Balance Condition that
1. ensures depth is O(log n)
– strong enough!
2. is easy to maintain
– not too strong!
Potential Balance Conditions
1. Left and right subtrees of the root
have equal number of nodes
2. Left and right subtrees of the root
have equal height
3. Left and right subtrees of every node
have equal number of nodes
4. Left and right subtrees of every node
have equal height
The AVL Balance Condition
AVL balance property:
Left and right subtrees of every node
have heights differing by at most 1
• Ensures small depth
– Will prove this by showing that an AVL tree of height
h must have a lot of (i.e. O(2h)) nodes
• Easy to maintain
– Using single and double rotations
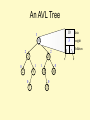
The AVL Tree Data Structure
Structural properties
1. Binary tree property
(0,1, or 2 children)
2. Heights of left and right
subtrees of every node
differ by at most 1
Result:
Worst case depth of any
node is: O(log n)
Ordering property
– Same as for BST
8
5
2
11
6
4
10
7
9
12
13 14
15
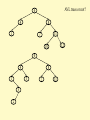
AVL trees or not?
6
4
8
1
11
7
12
10
6
4
1
8
5
3
2
7
11
Proving Shallowness Bound
Let S(h) be the min # of nodes in an
AVL tree of height h
AVL tree of height h=4
with the min # of nodes (12)
8
Claim: S(h) = S(h-1) + S(h-2) + 1
Solution of recurrence: S(h) = O(2h)
(like Fibonacci numbers)
5
2
11
6
10
7
9 13
12
14
15
Testing the Balance Property
We need to be able to:
10
5
1. Track Balance
15
2. Detect Imbalance
2
9
20
3. Restore Balance
7
NULLs have
height -1
17
30
An AVL Tree
3
10
2
20
1
0
2
9
0
1
0
15
30
0
7
17
data
3
height
children
2
5
10
AVL trees: find, insert
• AVL find:
– same as BST find.
• AVL insert:
– same as BST insert, except may need to
“fix” the AVL tree after inserting new value.
AVL tree insert
Let x be the node where an imbalance occurs.
Four cases to consider. The insertion is in the
1.
2.
3.
4.
left subtree of the left child of x.
right subtree of the left child of x.
left subtree of the right child of x.
right subtree of the right child of x.
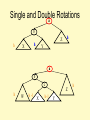
Idea: Cases 1 & 4 are solved by a single rotation.
Cases 2 & 3 are solved by a double rotation.
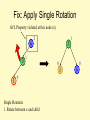
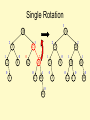
Bad Case #1
Insert(6)
Insert(3)
Insert(1)
Fix: Apply Single Rotation
AVL Property violated at this node (x)
6
3
2
1
3
1
0
0
1
1
0
Single Rotation:
1. Rotate between x and child
6
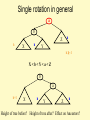
Single rotation in general
a
b
h
X
Z
h
h
Y
h -1
X<b<Y<a<Z
b
a
h+1
X
h
Y
Z
h
Height of tree before? Height of tree after? Effect on Ancestors?
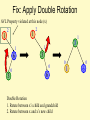
Bad Case #2
Insert(1)
Insert(6)
Insert(3)
Fix: Apply Double Rotation
AVL Property violated at this node (x)
1
2
1
2
1
1
1
6
3
0
3
3
0
6
Double Rotation
1. Rotate between x’s child and grandchild
2. Rotate between x and x’s new child
0
0
1
6
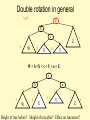
Double rotation in general
h0
a
b
c
h
h
Z
h -1
W
h-1
X
Y
W < b <X < c < Y < a < Z
c
b
h
a
h-1
h
W
X
Y
h
Z
Height of tree before? Height of tree after? Effect on Ancestors?
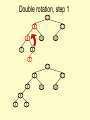
Double rotation, step 1
15
8
4
17
16
10
6
3
5
15
8
6
4
3
5
17
10
16
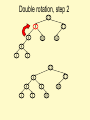
Double rotation, step 2
15
8
6
17
16
10
4
3
5
15
17
6
4
3
8
5
16
10
Imbalance at node X
Single Rotation
1. Rotate between x and child
Double Rotation
1. Rotate between x’s child and grandchild
2. Rotate between x and x’s new child
Single and Double Rotations:
Inserting what integer values
would cause the tree to need a:
1. single rotation?
9
5
2
2. double rotation?
3. no rotation?
0
11
7
3
13
Insertion into AVL tree
1.
2.
3.
4.
Find spot for new key
Hang new node there with this key
Search back up the path for imbalance
If there is an imbalance:
case #1: Perform single rotation and exit
case #2: Perform double rotation and exit
Both rotations keep the subtree height unchanged.
Hence only one rotation is sufficient!
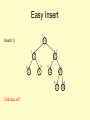
Easy Insert
3
10
Insert(3)
1
2
5
15
0
0
2
9
0
1
12
20
0
0
17 30
Unbalanced?
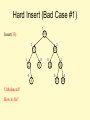
Hard Insert (Bad Case #1)
3
10
Insert(33)
2
2
5
15
1
0
2
9
0
How to fix?
1
12
20
0
0
3
Unbalanced?
0
17
30
Single Rotation
3
3
10
10
2
3
5
15
1
0
2
9
0
0
12
20
1
20
0
2
30
33
1
15
0
3
0
1
9
0
1
17
2
5
2
0
3
2
30
0
12
17
0
33
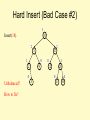
Hard Insert (Bad Case #2)
3
10
Insert(18)
2
2
5
15
1
0
2
9
0
Unbalanced?
How to fix?
0
1
12
20
0
0
3
17
30
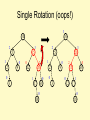
Single Rotation (oops!)
3
3
10
10
2
3
5
15
1
0
2
9
0
2
5
0
12
20
30
0
18
0
2
0
17
20
1
2
1
3
3
2
15
9
0
0
30
0
3
1
12
17
0
18
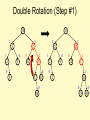
Double Rotation (Step #1)
3
3
10
10
2
3
5
15
1
0
2
9
0
2
5
0
12
20
30
0
18
0
2
0
17
15
1
2
1
3
3
9
0
2
12
17
0
1
3
20
0
18
0
30
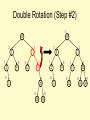
Double Rotation (Step #2)
3
3
10
10
2
3
5
15
1
0
2
2
9
2
5
0
1
2
12
17
0
18
30
1
15
0
3
0
1
9
0
20
0
0
2
1
3
17
20
0
12
0
18 30
Insert into an AVL tree: 5, 8, 9, 4, 2, 7, 3, 1
CSE 326: Data Structures
Splay Trees
AVL Trees Revisited
• Balance condition:
Left and right subtrees of every node
have heights differing by at most 1
– Strong enough
: Worst case depth is O(log n)
– Easy to maintain : one single or double rotation
• Guaranteed O(log n) running time for
–
–
–
–
Find ?
Insert ?
Delete ?
buildTree ?
Single and Double
Rotations
a
b
Z
h
h
X
h
Y
a
b
c
Z
h
W
h -1
X
h-1
Y
h
AVL Trees Revisited
• What extra info did we maintain in each
node?
• Where were rotations performed?
• How did we locate this node?
Other Possibilities?
• Could use different balance conditions, different ways
to maintain balance, different guarantees on running
time, …
• Why aren’t AVL trees perfect?
• Many other balanced BST data structures
–
–
–
–
–
–
Red-Black trees
AA trees
Splay Trees
2-3 Trees
B-Trees
…
Splay Trees
• Blind adjusting version of AVL trees
– Why worry about balances? Just rotate
anyway!
• Amortized time per operations is O(log n)
• Worst case time per operation is O(n)
– But guaranteed to happen rarely
Insert/Find
always
rotate node to the
SAT/GRE
Analogy
question:
root!
AVL
is to Splay trees as ___________ is to __________
Recall: Amortized Complexity
If a sequence of M operations takes O(M f(n)) time,
we say the amortized runtime is O(f(n)).
• Worst case time per operation can still be large, say O(n)
• Worst case time for any sequence of M operations is O(M f(n))
Average time per operation for any sequence is O(f(n))
Amortized complexity is worst-case guarantee over
sequences of operations.
Recall: Amortized Complexity
• Is amortized guarantee any weaker than
worstcase?
• Is amortized guarantee any stronger than
averagecase?
• Is average case guarantee good enough in
practice?
• Is amortized guarantee good enough in
practice?
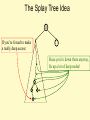
The Splay Tree Idea
10
If you’re forced to make
a really deep access:
17
Since you’re down there anyway,
fix up a lot of deep nodes!
5
2
9
3
Find/Insert in Splay Trees
1. Find or insert a node k
2. Splay k to the root using:
zig-zag, zig-zig, or plain old zig rotation
Why could this be good??
1. Helps the new root, k
o Great if k is accessed again
2. And helps many others!
o
Great if many others on the path are accessed
Splaying node k to the root:
Need to be careful!
One option (that we won’t use) is to repeatedly use AVL
single rotation until k becomes the root: (see Section
4.5.1 for details)
p
k
q
F
r
s
E
p
s
D
A
B
k
A
q
F
r
E
B
C
C
D
Splaying node k to the root:
Need to be careful!
What’s bad about this process?
k
p
q
r
s
F
s
p
E
D
A
B
B
C
F
r
k
A
q
C
E
D
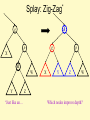
Splay: Zig-Zag*
k
g
p
g
p
X
k
W
Y
*Just
like an…
X
Y
Z
W
Z
Which nodes improve depth?
Splay: Zig-Zig*
k
g
p
p
W
Z
k
g
X
Y
Y
Z
W
*Is this just two AVL single rotations in a row?
X
Special Case for Root: Zig
root
k
p
k
p
Z
X
root
X
Y
Relative depth of p, Y, Z?
Y
Z
Relative depth of everyone else?
Why not drop zig-zig and just zig all the way?
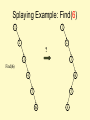
Splaying Example: Find(6)
1
1
2
2
?
3
3
Find(6)
4
6
5
5
6
4
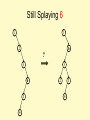
Still Splaying 6
1
1
2
6
?
3
3
6
5
4
2
5
4
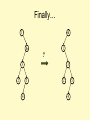
Finally…
1
6
6
1
?
3
2
3
5
4
2
5
4
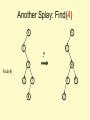
Another Splay: Find(4)
6
6
1
1
?
3
4
Find(4)
2
5
4
3
2
5
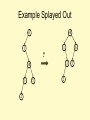
Example Splayed Out
6
4
1
1
6
?
3
4
3
2
5
2
5
But Wait…
What happened here?
Didn’t two find operations take linear time
instead of logarithmic?
What about the amortized O(log n)
guarantee?
Why Splaying Helps
• If a node n on the access path is at depth d
before the splay, it’s at about depth d/2 after
the splay
• Overall, nodes which are low on the access
path tend to move closer to the root
• Splaying gets amortized O(log n)
performance. (Maybe not now, but soon, and for the rest of the
operations.)
Practical Benefit of Splaying
• No heights to maintain, no imbalance to
check for
– Less storage per node, easier to code
• Data accessed once, is often soon
accessed again
– Splaying does implicit caching by bringing it to
the root
Splay Operations: Find
• Find the node in normal BST manner
• Splay the node to the root
– if node not found, splay what would have
been its parent
What if we didn’t splay?
Amortized guarantee fails!
Bad sequence: find(leaf k), find(k), find(k), …
Splay Operations: Insert
• Insert the node in normal BST manner
• Splay the node to the root
What if we didn’t splay?
Splay Operations: Remove
k
find(k)
delete k
L
R
Now what?
L
<k
R
>k
Join
Join(L, R):
given two trees such that (stuff in L) < (stuff in R), merge
them:
splay
L
max
L
R
R
Splay on the maximum element in L, then
attach R
Does this work to join any two trees?
Delete Example
Delete(4)
6
4
1
9
4
find(4)
6
1
7
6
1
9
2
2
2
1
7
Find max
7
2
9
2
6
1
6
9
7
9
7
Splay Tree Summary
• All operations are in amortized O(log n) time
• Splaying can be done top-down; this may be better
because:
– only one pass
– no recursion or parent pointers necessary
– we didn’t cover top-down in class
• Splay trees are very effective search trees
– Relatively simple
– No extra fields required
– Excellent locality properties:
frequently accessed keys are cheap to find
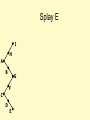
Splay E
I
H
A
B
G
F
C
D
E
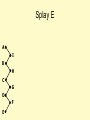
Splay E
A
I
B
H
C
G
D
F
E
CSE 326: Data Structures
B-Trees
B-Trees
Weiss Sec. 4.7
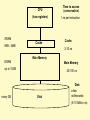
CPU
(has registers)
SRAM
8KB - 4MB
Cache
TIme to access
(conservative)
1 ns per instruction
Cache
2-10 ns
Main Memory
DRAM
Main Memory
up to 10GB
40-100 ns
Disk
many GB
Disk
a few
milliseconds
(5-10 Million ns)
Trees so far
• BST
• AVL
• Splay
AVL trees
Suppose we have 100 million items
(100,000,000):
• Depth of AVL Tree
• Number of Disk Accesses
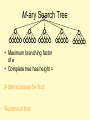
M-ary Search Tree
• Maximum branching factor
of M
• Complete tree has height =
# disk accesses for find:
Runtime of find:
Solution: B-Trees
• specialized M-ary search trees
• Each node has (up to) M-1 keys:
– subtree between two keys x and y contains
leaves with values v such that 3 7 12 21
xv<y
• Pick branching factor M
such that each node
takes one full
x<3
{page, block}
of memory
3x<7
7x<12
12x<21
21x
B-Trees
What makes them disk-friendly?
1. Many keys stored in a node
•
All brought to memory/cache in one access!
2. Internal nodes contain only keys;
Only leaf nodes contain keys and actual
data
•
•
The tree structure can be loaded into memory
irrespective of data object size
Data actually resides in disk
B-Tree: Example
B-Tree with M = 4 (# pointers in internal node)
and L = 4
(# data items in leaf)
10 40
3
1 2
AB xG
15 20 30
10 11 12
3 5 6 9
Data objects, that I’ll
ignore in slides
20 25 26
15 17
50
40 42
30 32 33 36
50 60 70
Note: All leaves at the same depth!
B-Tree Properties ‡
– Data is stored at the leaves
– All leaves are at the same depth and contains between
L/2 and L data items
– Internal nodes store up to M-1 keys
– Internal nodes have between M/2 and M children
– Root (special case) has between 2 and M children (or
root could be a leaf)
‡These
are technically B+-Trees
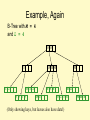
Example, Again
B-Tree with M = 4
and L = 4
10 40
3
1 2
15 20 30
10 11 12
3 5 6 9
50
20 25 26
15 17
40 42
30 32 33 36
(Only showing keys, but leaves also have data!)
50 60 70
Building a B-Tree
3
Insert(3)
3 14
Insert(14)
The empty
B-Tree
M = 3 L = 2
Now, Insert(1)?
M = 3 L = 2
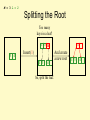
Splitting the Root
Too many
keys in a leaf!
1 3 14
3 14
Insert(1)
1 3
14
So, split the leaf.
14
And create
a new root
1 3
14
M = 3 L = 2
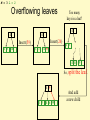
Overflowing leaves
14
14
14
Insert(26)
Insert(59)
1 3
14
Too many
keys in a leaf!
1 3
14 59
1 3
14 26 59
So, split
the leaf.
14 59
1 3 14 26 59
And add
a new child
M = 3 L = 2
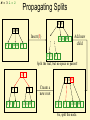
Propagating Splits
14 59
14 59
Insert(5)
1 3
Add new
child
14 26 59
14 26 59
1 3
5
Split the leaf, but no space in parent!
14
5 14 59
5
1 3 5
59
14 26 59
Create a
new root
1 3
5
14 26 59
So, split the node.
Insertion Algorithm
1. Insert the key in its leaf
2. If the leaf ends up with L+1
items, overflow!
–
Split the leaf into two nodes:
•
•
–
–
original with (L+1)/2 items
new one with (L+1)/2 items
Add the new child to the parent
If the parent ends up with M+1
items, overflow!
3. If an internal node ends up
with M+1 items, overflow!
– Split the node into two nodes:
• original with (M+1)/2 items
• new one with (M+1)/2 items
– Add the new child to the parent
– If the parent ends up with M+1
items, overflow!
4. Split an overflowed root in two
and hang the new nodes
under a new root
This makes the tree deeper!
M = 3 L = 2
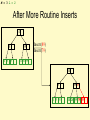
After More Routine Inserts
14
5
1 3 5
59
Insert(89)
Insert(79)
14 26 59
14
5
1 3 5
59 89
14 26 59 79 89
M = 3 L = 2
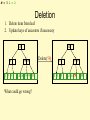
Deletion
1. Delete item from leaf
2. Update keys of ancestors if necessary
14
5
1 3 5
14
59 89
14 26 59 79 89
What could go wrong?
Delete(59)
5
1 3 5
79 89
14 26 79
89
M = 3 L = 2
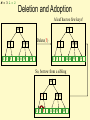
Deletion and Adoption
A leaf has too few keys!
14
5
1 3 5
14
Delete(5)
79 89
14 26 79
?
79 89
1 3
89
14 26 79
So, borrow from a sibling
14
3
1 3 3
79 89
14 26 79
89
89
Does Adoption Always Work?
• What if the sibling doesn’t have enough for
you to borrow from?
e.g. you have L/2-1 and sibling has L/2 ?
M = 3 L = 2
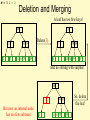
Deletion and Merging
A leaf has too few keys!
14
3
1
14
Delete(3)
79 89
3
14 26 79
?
1
89
79 89
14 26 79
89
And no sibling with surplus!
14
So, delete
the leaf
79 89
But now an internal node
has too few subtrees!
1
14 26 79
89
M = 3 L = 2
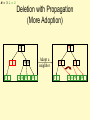
Deletion with Propagation
(More Adoption)
14
79
Adopt a
neighbor
79 89
1
14 26 79
89
14
1
89
14 26 79
89
M = 3 L = 2
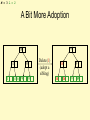
A Bit More Adoption
79
79
14
1
14 26 79
89
89
Delete(1)
(adopt a
sibling)
26
14
26
89
79
89
M = 3 L = 2
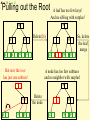
Pulling out the Root
A leaf has too few keys!
And no sibling with surplus!
79
79
26
14
26
89
79
Delete(26)
89
14
89
But now the root
has just one subtree!
79
89
A node has too few subtrees
and no neighbor with surplus!
79
79 89
14
79
89
So, delete
the leaf;
merge
Delete
the node
89
14
79
89
M = 3 L = 2
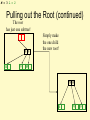
Pulling out the Root (continued)
The root
has just one subtree!
79 89
14
79
Simply make
the one child
the new root!
89
79 89
14
79
89
Deletion Algorithm
1. Remove the key from its leaf
2. If the leaf ends up with fewer
than L/2 items, underflow!
– Adopt data from a sibling;
update the parent
– If adopting won’t work, delete
node and merge with neighbor
– If the parent ends up with
fewer than M/2 items,
underflow!
Deletion Slide Two
3. If an internal node ends up with
fewer than M/2 items, underflow!
– Adopt from a neighbor;
update the parent
– If adoption won’t work,
merge with neighbor
– If the parent ends up with fewer than
M/2 items, underflow!
4. If the root ends up with only one
child, make the child the new root
of the tree
This reduces the
height of the tree!
Thinking about B-Trees
• B-Tree insertion can cause (expensive)
splitting and propagation
• B-Tree deletion can cause (cheap)
adoption or (expensive) deletion, merging
and propagation
• Propagation is rare if M and L are large
(Why?)
• If M = L = 128, then a B-Tree of height 4
will store at least 30,000,000 items
Tree Names You Might Encounter
FYI:
– B-Trees with M = 3, L = x are called 2-3
trees
• Nodes can have 2 or 3 keys
– B-Trees with M = 4, L = x are called 2-3-4
trees
• Nodes can have 2, 3, or 4 keys
K-D Trees and Quad Trees
Range Queries
• Think of a range query.
– “Give me all customers aged 45-55.”
– “Give me all accounts worth $5m to $15m”
• Can be done in time ________.
• What if we want both:
– “Give me all customers aged 45-55 with
accounts worth between $5m and $15m.”
Geometric Data Structures
• Organization of points, lines, planes, etc in
support of faster processing
• Applications
– Map information
– Graphics - computing object intersections
– Data compression - nearest neighbor search
– Decision Trees - machine learning
k-d Trees
• Jon Bentley, 1975, while an undergraduate
• Tree used to store spatial data.
– Nearest neighbor search.
– Range queries.
– Fast look-up
• k-d tree are guaranteed log2 n depth where n
is the number of points in the set.
– Traditionally, k-d trees store points in
d-dimensional space which are equivalent to
vectors in d-dimensional space.
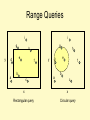
Range Queries
i
i
g
y
e
d
a
g
h
f
b
c
y
e
d
a
h
f
b
c
x
x
Rectangular query
Circular query
Nearest Neighbor Search
i
g
y
h
e
d
query
a
b
c
x
Nearest neighbor is e.
f
k-d Tree Construction
• If there is just one point, form a leaf with that point.
• Otherwise, divide the points in half by a line
perpendicular to one of the axes.
• Recursively construct k-d trees for the two sets of
points.
• Division strategies
– divide points perpendicular to the axis with widest spread.
– divide in a round-robin fashion (book does it this way)
k-d Tree Construction
i
g
y
e
d
a
h
f
b
c
x
divide perpendicular to the widest spread.
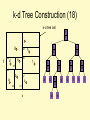
k-d Tree Construction (18)
k-d tree cell
x
s1
i
g
y
s4
s8
h
f
x
s3
s5
s2
b
a
y
s4
s7
c
s3
y
s6
s6
e
d
y
s2
a
x
s5
b
s1
x
d
y
s7
g
e
c
y
s8
f
h
i
2-d Tree Decomposition
2
1
3
k-d Tree Splitting
sorted points in each dimension
1 2 3 4 5 6 7 8 9
x a d g be i c h f
y a c b d f e h g i
i
g
y
e
d
a
h
f
b
c
x
• max spread is the max of
fx -ax and iy - ay.
• In the selected dimension the
middle point in the list splits the
data.
• To build the sorted lists for the
other dimensions scan the sorted
list adding each point to one of two
sorted lists.
k-d Tree Splitting
sorted points in each dimension
1 2 3 4 5 6 7 8 9
x a d g be i c h f
y a c b d f e h g i
i
g
y
indicator for each set
e
d
a
h
f
a b c de f g h i
0 0 1 00 1 0 1 1
b
c
scan sorted points in y dimension
and add to correct set
x
y a b d eg c f h i
k-d Tree Construction
Complexity
• First sort the points in each dimension.
– O(dn log n) time and dn storage.
– These are stored in A[1..d,1..n]
• Finding the widest spread and equally
divide into two subsets can be done in
O(dn) time.
• We have the recurrence
– T(n,d) < 2T(n/2,d) + O(dn)
• Constructing the k-d tree can be done in
O(dn log n) and dn storage
Node Structure for k-d Trees
• A node has 5 fields
– axis (splitting axis)
– value (splitting value)
– left (left subtree)
– right (right subtree)
– point (holds a point if left and right children
are null)
Rectangular Range Query
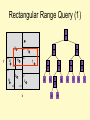
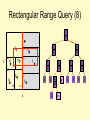
• Recursively search every cell that
intersects the rectangle.
Rectangular Range Query (1)
x
s1
i
g
y
s4
s8
h
f
x
s3
s5
s2
b
a
y
s4
s7
c
s3
y
s6
s6
e
d
y
s2
a
x
s5
b
s1
x
d
y
s7
g
e
c
y
s8
f
h
i
Rectangular Range Query (8)
x
s1
i
g
y
s4
s8
h
f
x
s3
s5
s2
b
a
y
s4
s7
c
s3
y
s6
s6
e
d
y
s2
a
x
s5
b
s1
x
d
y
s7
g
e
c
y
s8
f
h
i
Rectangular Range Query
print_range(xlow, xhigh, ylow, yhigh :integer, root: node pointer) {
Case {
root = null: return;
root.left = null:
if xlow < root.point.x and root.point.x < xhigh
and ylow < root.point.y and root.point.y < yhigh
then print(root);
else
if(root.axis = “x” and xlow < root.value ) or
(root.axis = “y” and ylow < root.value ) then
print_range(xlow, xhigh, ylow, yhigh, root.left);
if (root.axis = “x” and xlow > root.value ) or
(root.axis = “y” and ylow > root.value ) then
print_range(xlow, xhigh, ylow, yhigh, root.right);
}}
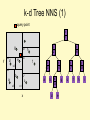
k-d Tree Nearest Neighbor
Search
• Search recursively to find the point in the
same cell as the query.
• On the return search each subtree where
a closer point than the one you already
know about might be found.
k-d Tree NNS (1)
query point
x
s1
i
g
y
s4
s8
h
f
x
s3
s5
s2
b
a
y
s4
s7
c
s3
y
s6
s6
e
d
y
s2
a
x
s5
b
s1
x
d
y
s7
g
e
c
y
s8
f
h
i
k-d Tree NNS
query point
x
s1
i
g
y
s4
s8
e
d
y
s2
h
w s6
f
x
s3
s5
s2
b
a
y
s4
s7
c
s3
y
s6
a
x
s5
b
s1
x
d
y
s7
g
e
c
y
s8
f
h
i
Notes on k-d NNS
• Has been shown to run in O(log n)
average time per search in a reasonable
model.
• Storage for the k-d tree is O(n).
• Preprocessing time is O(n log n) assuming
d is a constant.
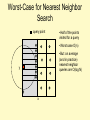
Worst-Case for Nearest Neighbor
Search
query point
•Half of the points
visited for a query
•Worst case O(n)
•But: on average
(and in practice)
nearest neighbor
queries are O(log N)
y
x
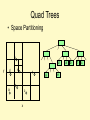
Quad Trees
• Space Partitioning
g
d
y
e
d
a
f
b
c
x
g
e
a
b
f
c
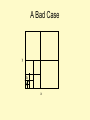
A Bad Case
y
ab
x
Notes on Quad Trees
• Number of nodes is O(n(1+ log(/n)))
where n is the number of points and is
the ratio of the width (or height) of the key
space and the smallest distance between
two points
• Height of the tree is O(log n + log )
K-D vs Quad
• k-D Trees
–
–
–
–
Density balanced trees
Height of the tree is O(log n) with batch insertion
Good choice for high dimension
Supports insert, find, nearest neighbor, range queries
• Quad Trees
–
–
–
–
Space partitioning tree
May not be balanced
Not a good choice for high dimension
Supports insert, delete, find, nearest neighbor, range queries
Geometric Data Structures
• Geometric data structures are common.
• The k-d tree is one of the simplest.
– Nearest neighbor search
– Range queries
• Other data structures used for
– 3-d graphics models
– Physical simulations