Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
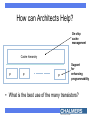
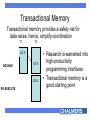
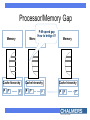
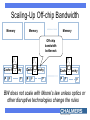
In memory of Stamatis The Paradigm Shift to Multi-Cores: Opportunities and Challenges Per Stenstrom Department of Computer Science & Engineering Chalmers University of Technology Sweden An Unwanted Paradigm Shift 30% annual performance growth 60% annual performance growth • Clock frequency couldn’t be pushed higher • Traditional parallelism exploitation didn’t pay off The Easy Way Out: Replicate Year 2006 2009 2012 2015 # Cores 4 16 64 256 64 256 1024 # Threads 16 • Moore’s Law: 2X cores every 18 months – Implication: About a hundred cores in five years • BUT: Software can only make use of one! Main Challenges – Programmability – Scalability We want to seamlessly scale up application performance within power envelope Vision: Multiple Cores = One Processor Application SW (existing and new) P P P M P P System software infrastructure P Multi-core Requires a concerted action across layers: programming model, compiler, architecture How can Architects Help? On-chip cache management Cache hierarchy P P P Support for enhancing programmability • What is the best use of the many transistors? ”Inherent” Speculative Parallelism [Islam et al. ICPP 2007] Speedup Representative of what is possible today GMean 2 djpeg cjpeg fft00 conven00 GMean 1 rgbyiq01 rgbhpg01 rgbcmy01 viterb00 fbital00 autocor00 24 22 20 18 16 14 12 10 8 6 4 2 0 Scaling beyond eight cores will need manual efforts Three Hard Steps 1. Decomposition 2. Assignment 3. Orchestration Goal: expose concurrency but beware of thread mngmt overhead Goal: balance load & reduce communication Goal: Orchestrate threads to reduce communication and synchronization costs Transactional Memory Transactional memory provides a safety net for data races: hence, simplify coordination T1 T2 LD A SQUASH ST A LD A RE-EXECUTE • Research is warranted into high-productivity programming interfaces • Transactional memory is a good starting point Transistors can Help Programmers Recall the ”hard steps”: • Decomposition • Assignment • Orchestration Opportunities abound Low-overhead spawning mechanisms Load balancing supported in HW Communication balancing supported in HW Processor/Memory Gap P-M speed gap How to bridge it? Memory Memory Memory Cache hierarchy Cache hierarchy Cache hierarchy P P P P P P P P P Adaptive Shared Caches [Dybdahl & Stenstrom HPCA 2007] P1 P2 P1 P2 P1 P2 L1 L1 L1 L1 L1 L1 L2 L2 L2 L2 L2 Shared Private Conflicts --+++ Speed --+++ Utilization +++ --- Adaptive Hybrid +++ +++ +++ Scaling-Up Off-chip Bandwidth Memory Memory Memory Off-chip bandwidth bottleneck ... ... ... Cache hierarchy Cache hierarchy Cache hierarchy P P P P P P P P P BW does not scale with Moore’s law unless optics or other disruptive technologies change the rules Memory/Cache Link Compression [Thuresson & Stenstrom, IEEE TC to appear] 25 20 15 swc-data + oh 10 swc+ PVC 5 0 gzip vpr gcc perl AVER Our combined scheme yields 3X in bandwidth reduction Summary • Multi-cores promise scalable performance under a manageable power envelope, but are hard to program • To provide scalable application performance for the future requires research at all levels – Architecture (processor, cache, interconnect) – Compiler – Programming model These topics are dealt with in the FET SARC IP and in the HiPEAC network of excellence