Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
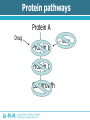
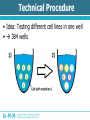
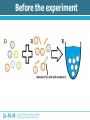
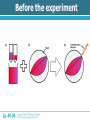
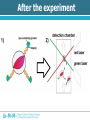
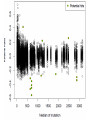
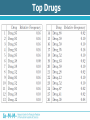
Analysis of Drug-Gene Interaction Data Florian Ganglberger Sebastian Nijman Lab Nijman Lab Nijman Lab • Working on specialised target-oriented cancer therapies • Cancer = cell mutation Drug Mutation Drug Mutation Mutation Drug Mutation Mutation Drug Mutation Motivation • Testing various drugs on various mutated cells • 100 drugs vs 100 mutations = 10.000 interactions • Analyse the generated data to find new treatments Overview • Background – Biological Background – Technical Procedure – Initial State – Special Aspects – Previous Approach • Analysis – Explorative Data Analysis – Drug Noisiness Data generation Overview • Hit detection – Statistical Methods – Filtering Methods – The Algorithm – Evaluation of the result Biological Background • Idea behind cancer treatment – Kill cancer cells while leaving normal cells alive • Common chemotherapies – Kill cells with higher division rate – Problem: moth-, throat-, bowel-mucosa and hair cells – Feel sick, loosing hair etc. Biological Background • Synthetic lethality approach – Some biochemical process which are necessary for cell growth are redundant – e.g. DNA repair – Biochemical processes are chained = “protein pathway” Protein pathways Protein A Drug Protein B Protein C Cell growth Gene Synthetic lethality • Choose a cancer which has a mutation of a gene in one of that pathways • Find a drug which inhibits the other pathway Synthetic lethality • Produce cells with mutations which are normally present in cancer • Find drug • Possible that this will work in real cancer – Tumours have more than one mutation can influence each other Technical Procedure • Standard dataset consists of 38.400 interactions • 96 drugs x 100 mutations x 4 • Testing would be inefficient Technical Procedure • Idea: Testing different cell lines in one well • 384 wells Before the experiment Before the experiment After the experiment • Copy the barcodes of the cells by a polymerase chain reaction (PCR) amplifies the signal • Adding a vitamin to the barcode which can stick on a dye-containing protein • Amount of barcode correlates with the amount of remaining cells After the experiment Allocation • Red and infrared emitted light barcode mutation • Green reflected light cell amount – Arbitrary unit which correlates with the cell amount – Called “Reporter” • Drug because of the used well Initial state • Because drugs are dissolved in a dilution, we can use wells without drugs use as control Back to statistics.... Special Aspects • Biological and technical factors cause noisy and not directly usable data Inter- and intraindividual variability Interindividual Variability • Variability between observation units • Cells with the same mutation = one observation unit = “one virtual cancer patient” • Variation among different mutated cells • Reasons – Mutations can be toxic itself – Characteristics of the technical process Interindividual Variability • Average amount of remaining mutations Variability of Technical Procedure • Limited precision – Precision of drug dosing – Precision of cell amount – Quality of the measurement equipment • Decreased sensitivity to a lower signal – Detection limit – Killed cells don’t get a zero signal background noise with different variability Variability of Technical Procedure • Amplification problems – Copying the barcodes by PCR needs material – If some cell lines are completely killed more material for other cell lines higher amplification of survived cells Amplification Problems Previous Approach • Visual method, based on scatter plots • Identify outliers visually Previous Approach 1. Calculating the effect 1. Median normalization of drugs 2. Calculate a relative ratio Previous Approach • Plotting the ratio against the median of a mutation There are some problems.... • If two lines overlap, hits can be obscured • No comparable value that estimates the significance of outliers • Intraindividual variability referred to replicates is ignored • Human errors outlier-detection is subjective • Slow, not automatable method Overview • Background – Biological Background – Technical Procedure – Initial State – Special Aspects – Previous Approach • Analysis – Explorative Data Analysis – Drug Noisiness Explorative Data Analysis • Necessary for hit detection • Analysis of the behaviour of the data • Closer look at – Distribution of mutations – Variability of mutations and replicates – Skewness of mutations – Noisiness of Drugs Distribution of Mutations • Choosing the right statistical test • Test will be applied on mutations to see which drug works best • Effect is point of interest Matrix of relative ratios Variability of Mutations • Decreased sensitivity to lower signal • Maybe a detection limit • Spread vs Level plot Replicate Variability • Important factor is the multiple testing of cells by the same drugs. • Indicator for accurateness and reproducibility of the technical procedure. Skewness of Mutations • Another indicator for different behaviour below the threshold • Right skewed distributions because of background noise in lower signal Drug Noisiness • Nothing to do with background noise • Caused by technical procedure – Overdosing of cells or drugs – Toxicity (“Dosis facit venenum“) • Different effect – Strong resistance – Strong sensitivity Amplification Problems Strong Noisiness • • • • Easy to identify Dedicated outliers High amount of false positive hits Idea: Noisiness causes weak correlation to the control Weak Noisiness • Also numerous differences in sensitivity or resistance • Contrast to normal drugs is not well defined • Visual methods failed • Also a lot of false positive hits Strong Noisiness vs Weak Noisiness Overview • Hit detection – Statistical Methods – Filtering Methods – The Algorithm – Evaluation of the result Hit detection • Definition of a Hit – Indicate synthetic lethality – Resistance is also interesting from a biological point of view – Not noisy • 2 Stages: 1. Finding potential hits 2. Filtering false-positive hits and incomparable data Statistical Test • Mutations not normally distributed • Compare the 4 replicates to their mutation • Mann-Whithney u-test – Compares two medians – Needs approximately identical distribution form of random variables X and Y – No symmetry or normal distribution needed Statistical Test • Disadvantages – Rank-sum tests are based on the order, not on the magnitudes – Weak outlying interactions get the same p-values as strong outliers – P-values are not interindividual comparable, but the significance is an indicator for it. – Strong noisy drugs are usually extreme outliers reduce the significance Multiple testing • Multiple testing of interactions against their mutations • Increases the error • 100 different interactions • = Multiple testing • Bonferroni correction needed • How to achieve significant results? – Calculate the median of replicates – Testing just the upper and lower 10% of the data Filtering Drugs • Filtering strong noisy drugs by correlation coefficient • Filter before the test to increase the significance • Note: Drugs shouldn’t be filtered automatically, just identified. If drugs are toxic or not is the decision of a biologist Filtering strong noisy drugs Filtering weak noisy drugs • Much harder to identify • Idea: Weak noisy drugs producing many falsepositive hits with high significance – Calculating p-value – Order by significance – Frequency of drugs in the top hits is an indicator for weak noisiness Top Drugs Filter Mutations Filter data below a detection limit Ideas • Filter by threshold: 30% of the data just one dataset no universal validity of the threshold about 250 • Filter by skewness: 17% of the data • Filter by variationcoefficient 12% Threshold Estimation • Idea: Modification of skewness filter method • Outliers of skewness are below the threshold • Last non-outlier above the skewness outliers are normal data • Threshold should be approximately in the middle of these points The Algorithm • R-Demo Results