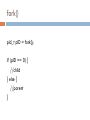Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Computer cluster wikipedia , lookup
Supercomputer wikipedia , lookup
Corecursion wikipedia , lookup
General-purpose computing on graphics processing units wikipedia , lookup
Buffer overflow protection wikipedia , lookup
Very long instruction word wikipedia , lookup
Monitor (synchronization) wikipedia , lookup
Data-intensive computing wikipedia , lookup
Supercomputer architecture wikipedia , lookup
Thread (computing) wikipedia , lookup
Stream processing wikipedia , lookup
MULTICORE, PARALLELISM,
AND MULTITHREADING
By: Eric Boren, Charles Noneman, and Kristen Janick
MULTICORE PROCESSING
Why we care
What is it?
A processor with more than one core on a single
chip
Core: An independent system capable of processing
instructions and modifying registers and memory
Motivation
Advancements in component technology and
optimization are limited in contribution to processor
speed
Many CPU applications attempt to do multiple
things at once:
Video
editing
Multi-agent simulation
So, use multiple cores to get it done faster
Hurdles
Instruction assignment (who does what?)
Mostly
delegated to the operating system
Can be done to a small degree through dependency
analysis on the chip
Cores must still communicate at times – how?
Shared-memory
Message
passing
Advantages
Multiple Programs:
Can be separated between cores
Other programs don’t suffer when one hogs CPU
Multi-threaded Applications:
Independent threads don’t have to wait as long for each
other – results in faster overall execution
VS Multiple Processors
Less distance between chips - faster communication results in
higher maximum clock rate
Less expensive due to smaller overall chip area, shared
components (caches, etc.)
Disadvantages
OS and programs must be optimized for multiple cores,
or no gain will be seen
In a singly-threaded application, little to no
improvement
Overhead in assigning tasks to cores
Real bottleneck is typically memory and disk access
time – independent of number of cores
Amdahl’s Law
Potential performance increase on a parallel
computing platform is given by Amdahl’s law.
Large
problems are made up of several parallelizable
parts and non-parallelizable parts.
S = 1/(1-P)
S = speed-up of program
P = fraction of program that is parallizable
Current State of the Art
Commercial processors:
Most have at least 2 cores
Quad-core are highly popular for desktop applications
6-core processors have recently appeared on the market
(Intel’s i7 980X)
8-core exist but are less common
Academic and research:
MIT: RAW 16-core
Intel Polaris – 80-core
UC Davis: AsAP – 36 and 167-core, individually-clocked
PARALLELISM
What is Parallel Computing?
Form of computation in which many calculations are
carried out simultaneously.
Operating
on the principle that large problems can
often be divided into smaller ones, which are solved
concurrently.
Types of Parallelism
Bit level parallelism
Instruction level parallelism
Instructions combined into groups
Data parallelism
Increase processor word size
Distribute data over different computing environments
Task parallelism
Distribute threads across different computing environments
Flynn’s Taxonomy
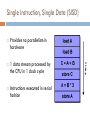
Single Instruction, Single Data (SISD)
Provides no parallelism in
hardware
1 data stream processed by
the CPU in 1 clock cycle
Instructions executed in serial
fashion
Multiple Instruction, Single Data (MISD)
Process single data stream using multiple instruction
streams simultaneously
More theoretical model than practical model
Single Instruction, Multiple Data (SIMD)
Single instruction steam has ability to process multiple
data streams in 1 clock cycle
Takes operation specified in one instruction and
applies it to more than 1 set of data elements at 1
time
Suitable for
graphics
and image
processing
Multiple Instruction, Multiple Data (MIMD)
Different processors can execute different
instructions on different pieces of data
Each processor can run independent task
Automatic parallelization
The goal is to relieve programmers from the tedious
and error-prone manual parallelization process.
Parallelizing compiler tries to split up a loops so
that its iterations can be executed on separate
processors concurrently
Identify dependences between references -independent actions can operate in parallel
Parallel Programming languages
Concurrent programming languages, libraries, API’s,
and parallel programming models have been
created for programming parallel computers.
Parallel languages make it easier to write parallel
algorithms
Resulting
code will run more efficiently because the
compiler will have more information to work with
Easier to identify data dependencies so that the runtime
system can implicitly schedule independent work
MULTITHREADING
TECHNIQUES
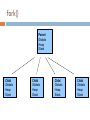
fork()
Make a (nearly) exact duplicate of the process
Good when there is no or almost no need to
communicate between processes
Often used for servers
fork()
Parent
Globals
Heap
Stack
Child
Globals
Heap
Stack
Child
Globals
Heap
Stack
Child
Globals
Heap
Stack
Child
Globals
Heap
Stack
fork()
pid_t pID = fork();
if (pID == 0) {
//child
} else {
//parent
}
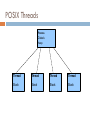
POSIX Threads
C library for threading
Available in Linux, OS X
Shared Memory
Threads are created and destroyed manually
Has mechanisms for locking memory
POSIX Threads
Process
Globals
Heap
Thread
Thread
Thread
Thread
Stack
Stack
Stack
Stack
POSIX Threads
pthread_t thread;
pthread_create( &thread, NULL, function_to_call,
(void*) data);
//Do stuff
pthread_join(thread, NULL);
POSIX Threads
int total = 0;
void do_work() {
//Do stuff to create “result”
total = total + result;
}
Thread 1 reads total (0)
Thread 2 reads total (0)
Thread 1 does add and saves total (1)
Thread 2 does add and saves total (2)
POSIX Threads
int total = 0;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void do_work() {
//Do stuff to create “result”
pthread_mutex_lock( &mutex );
total = total + result;
pthread_mutex_unlock( &mutex );
}
OpenMP
Library and compiler directives for multi-threading
Support in Visual C++, gcc
Code compiles even if compiler doesn't support OpenMP
Popular in high performance communities
Easy to add parallelism to existing code
OpenMP
Initialize an Array
const int array_size = 100000;
int i, a[array_size];
#pragma omp parallel for
for (i = 0; i < array_size; i++) {
a[i] = 2 * i;
}
OpenMP
Reduction
#pragma omp parallel for reduction(+:total)
for(i = 0; i < array_size; i++)
{
total = total + a[i];
}
Grand Central Dispatch
Apple Technology for Multi-Threading
Programmer puts work into queues
A system central process determines the number threads to
give to each queue
Add code to queues using a closure
Right now Mac only, but open source
Easy to add parallelism to existing code
Grand Central Dispatch
Initialize an Array
dispatch_apply(array_size,
dispatch_get_global_queue(0, 0), ^(int i) {
a[i] = 2*i;
});
Grand Central Dispatch
GUI Example
void analyzeDocument(doc) {
do_analysis(doc); //May take a very long time
update_display();
}
Grand Central Dispatch
GUI Example
void analyzeDocument(doc) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
do_analysis(doc);
update_display();
});
}
Other Technologies
Threading in Java, Python, etc.
MPI – for clusters
QUESTIONS?
Supplemental Reading
Introduction to Parallel Computing
https://computing.llnl.gov/tutorials/parallel_comp/#A
bstract
Introduction to Multi-Core Architecture
http://www.intel.com/intelpress/samples/mcp_samplec
h01.pdf
CPU History: A timeline of microprocessors
http://everything2.com/title/CPU+history%253A+A+t
imeline+of+microprocessors