Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Introduction to Artificial Intelligence –
Unit 7
Probabilistic Reasoning
Course 67842
The Hebrew University of Jerusalem
School of Engineering and Computer Science
Academic Year: 2008/2009
Instructor: Jeff Rosenschein
(Chapter 13, “Artificial Intelligence: A Modern Approach”)
Outline
Uncertainty
Probability
Syntax and Semantics
Independence and Bayes’ Rule
2
Uncertainty
Let action At = leave for airport t minutes
before flight
Will At get me there on time?
Problems:
1. partial observability (road state, other
drivers’ plans, etc.): Observable Vs. Hidden
variables
2. noisy sensors (traffic reports)
3. uncertainty in action outcomes (flat tire, etc.)
4. immense complexity of modeling and
predicting traffic
3
Uncertainty – Logical Approach
Hence a purely logical approach either
1. risks falsehood: “A25 will get me there on time”, or
2. leads to conclusions that are too weak for decision
making:
“A25 will get me there on time if there's no accident
on the bridge and it doesn't rain and my tires
remain intact etc etc.”
(A1440 might reasonably be said to get me there on
time but I'd have to stay overnight in the airport
…)
Methods for handling uncertainty
Default or nonmonotonic logic:
Assume my car does not have a flat tire
Assume A25 works unless contradicted by evidence
Issues: What assumptions are reasonable? How
to handle contradiction?
Rules with fudge factors:
A25 |→0.3 get there on time
Sprinkler |→ 0.99 WetGrass
WetGrass |→ 0.7 Rain
Issues: Problems with combination, e.g.,
Sprinkler causes Rain??
5
Methods for handling uncertainty
Certainty Factors: used in early expert systems,
worked (somewhat) because the domain was limited
and the rule base was carefully engineered
Dempster-Shafer: explicitly handles ignorance about
uncertainty (an expert who testifies with 90% certainty
that a coin you are about to flip is fair --- what do you
believe about the chances of Heads?)
Fuzzy Logic
(Fuzzy Logic actually handles degree of truth, NOT
uncertainty, e.g., WetGrass is true to degree 0.2)
Multi-valued Logics
Probability
Model agent’s degree of belief: given the available
6
evidence, A25 will get me there on time with probability 0.04
Probability
Probabilistic assertions summarize the uncertainty arising from
laziness: failure to enumerate exceptions, qualifications, etc.
ignorance: lack of relevant facts, initial conditions, etc.
Probabilities relate propositions to agent’s own beliefs,
not directly about the world:
P(A25 | no reported accidents) = 0.06
The beliefs depend on the percepts the agent has received.
These are not claims of a “probabilistic tendency” in the current situation
(but might be learned from past experience of similar situations).
Probabilities of propositions change with new evidence:
e.g., P(A25 | no reported accidents, 5 am) = 0.15
(Analogous to logical entailment from a knowledge base,
KB |= α, not “truth” --- could change as KB changes.)
7
Probability
“The probability that the patient has a
cavity is 80%”
This summarizes our uncertainty, given
our percepts
“The patient has a cavity” is actually true,
or false
Probability describes our beliefs about the
world, not the state of the world
8
Making decisions under
uncertainty
Suppose I believe the following:
P(A25 gets me there on time | …)
P(A90 gets me there on time | …)
P(A120 gets me there on time | …)
P(A1440 gets me there on time | …)
= 0.04
= 0.70
= 0.95
= 0.9999
Which action to choose?
Depends on my preferences for missing flight
vs. time spent waiting, etc.
Utility theory is used to represent and infer
preferences
Decision theory = utility theory + probability theory
9
Maximum Expected Utility
A rational agent chooses the action that
yields highest expected utility, averaged
over all possible outcomes of the action
The principle of Maximum Expected Utility
(MEU)
Examples of utility functions: Maximum
Likelihood (ML), Maximum Entropy (ME).
10
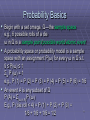
Probability Basics
Begin with a set omega, Ω—the sample space
e.g., 6 possible rolls of a die
ω in Ω is a sample point/possible world/atomic event
A probability space or probability model is a sample
space with an assignment P(ω) for every ω in Ω s.t.
0 ≤ P(ω) ≤ 1
Σω P (ω) = 1
e.g., P (1) = P (2) = P (3) = P (4) = P (5) = P (6) = 1/6
An event A is any subset of Ω
P (A) = Σ{ω in A}P (ω)
E.g., P (die roll < 4) = P (1) + P (2) + P (3) =
1/6 + 1/6 + 1/6 = 1/2
11
Random Variables
A random variable can be thought of as a referring
to a part of the world whose “status” is initially
unknown
E.g., Cavity might refer to my lower left wisdom tooth
having a cavity
A random variable is a function from sample points
to some range, e.g., the reals or Booleans, e.g.,
Odd(1) = true
P induces a probability distribution for any random
variable X:
P (X = xi ) = Σ{ω:X (ω) = x} P (ω)
e.g., P (Odd = true) = P (1) + P (3) + P (5) =
1/6 + 1/6 + 1/6 = 1/2
12
Propositions
Degrees of belief are always applied to
propositions (assertions that something is the
case in the world)
Think of a proposition as the event (set of
sample points) where the proposition is true
Given Boolean random variables A and B:
event a = set of sample points where A(ω) = true
event a = set of sample points where
A(ω) = false
event a b = points where
A(ω) = true and B(ω) = true
13
Atomic events / sample points, again
Atomic event: a complete specification of
the state of the world about which the
agent is uncertain
E.g., if the world consists of only two Boolean
variables Cavity and Toothache, then there
are 4 distinct atomic events:
Cavity = false Toothache = false
Cavity = false Toothache = true
Cavity = true Toothache = false
Cavity = true Toothache = true
Atomic events are mutually exclusive and
exhaustive
14
Propositions
Often in AI applications, the sample points are defined
by the values of a set of random variables, i.e., the
sample space is the Cartesian product of the ranges of
the variables
With Boolean variables, sample point = propositional logic model
e.g., A = true, B = f alse, or a b
Proposition is logically equivalent to the disjunction of
atomic events in which it is true
e.g., (a b) ≡ (¬a b) (a ¬b) (a b)
=> P(a b) ≡ P(¬a b) P(a ¬b) P(a b)
15
Kolmogorov’s Axioms of Probability
All probabilities are between 0 and 1. For
any proposition a, 0 <= P(a) <= 1.
Necessarily true (i.e., valid) propositions
have probability 1, and necessarily false
(i.e., unsatisfiable) propositions have
probability 0: P(true) = 1, P(false) = 0.
The probability of a disjunction is given by
P(a b) = P(a) + P(b) − P(ab)
16
Why Use Probability?
The definitions imply that certain logically
related events must have related probabilities
E.g., P(a b) = P(a) + P(b) − P(a b)
de Finetti (1931): an agent who bets according to probabilities that violate these
axioms can be forced to bet so as to lose money regardless of outcome
17
Syntax for Propositions
Propositional or Boolean random variables:
Cavity (do I have a cavity?)
Cavity = true is a proposition, also written cavity
Discrete random variables (finite or infinite):
Weather is one of <sunny, rain, cloudy, snow>
Weather = rain is a proposition
Continuous random variables (bounded or unbounded):
Temp = 21.6; also allow, e.g., Temp < 22.0
18
Prior probability
Prior or unconditional probabilities of propositions:
P(Cavity = true) = 0.1 and P(Weather = sunny) = 0.72 correspond to
belief prior to arrival of any (new) evidence
Probability distribution gives values for all possible assignments:
P(Weather) = <0.72,0.1,0.08,0.1> (normalized, i.e., sums to 1)
Joint probability distribution for a set of random variables gives the
probability of every atomic event on those random variables (i.e., every
sample point)
P(Weather, Cavity) = a 4 × 2 matrix of values:
Weather =
Cavity = true
Cavity = false
sunny rain
0.144 0.02
0.576 0.08
cloudy snow
0.016 0.02
0.064 0.08
Every question about a domain can be answered by the joint distribution
because every event is a sum of sample points
19
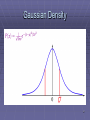
Probability for Continuous Variables
Express distribution as a parameterized function of
value:
P (X = x) = U [18, 26](x) = uniform density between
18 and 26
Here P is a density; integrates to 1.
P (X = 20.5) = 0.125 really means
lim P(20.5 ≤ X ≤ 20.5 + dx)/dx = 0.125
dx→0
20
Gaussian Density
21
Conditional probability
Conditional:
e.g., P(cavity | toothache) = 0.8
i.e., given that toothache is all I know
NOT “if toothache then 80% chance of cavity”,
i.e., “if toothache then P(cavity) = 0.8”
Such an interpretation is wrong on two counts:
P(a) always denotes the prior probability of a, not the posterior
probability given some evidence
The statement P(a | b) = 0.8 is immediately relevant just when b is the
only evidence
(Notation for conditional distributions:
P(Cavity | Toothache) = 2-element vector of 2-element
vectors)
22
Conditional Probability
If we know more, e.g., cavity is also given, then we
have
P(cavity | toothache,cavity) = 1
Note: the less specific belief remains valid after
more evidence arrives, but is not always useful
New evidence may be irrelevant, allowing
simplification:
P(cavity | toothache, sunny) = P(cavity | toothache) = 0.8
This kind of inference, sanctioned by domain
knowledge, is crucial
23
Conditional probability
Definition of conditional probability in terms
of unconditional probability:
P(a | b) = P(a b) / P(b) if P(b) > 0
Product rule gives an alternative
formulation:
P(a b) = P(a | b) P(b) = P(b | a) P(a)
“For a and b to be true, we need b to be true, and
we also need a to be true given b.”
24
Conditional Probability
A general version holds for whole distributions, e.g.,
P(Weather, Cavity) = P(Weather | Cavity) P(Cavity)
View as a 4 × 2 set of equations, not matrix multiplication:
P(Weather = sunny Cavity = true) =
P(Weather = sunny | Cavity = true) P(Cavity = true)
P(Weather = sunny Cavity = false) =
P(Weather = sunny | Cavity = false) P(Cavity = false)
P(Weather = rain Cavity = true) =
P(Weather = rain | Cavity = true) P(Cavity = true)
Etc…
Chain rule is derived by successive application of product rule:
25
Enumerating Probabilities
Any proposition a is equivalent to the disjunction of
all the atomic events in which a holds (call it e(a))
Recall that atomic events are mutually exclusive, so
the probability of a conjunction of events is 0
P(a b) = P(a) + P(b) − P(a b)
So…the probability of a proposition is equal to the
sum of the probabilities of the atomic events in
which it holds:
P(a) = Σei in e(a) P(ei)
26
Inference by enumeration
Start with the joint probability distribution:
For any proposition φ, sum the atomic events where
it is true: P(φ) = Σω:ω╞φ P(ω)
27
Inference by enumeration
Start with the joint probability distribution:
For any proposition φ, sum the atomic events where it
is true: P(φ) = Σω:ω╞φ P(ω)
P(toothache) = 0.108 + 0.012 + 0.016 + 0.064 = 0.2
(unconditional or marginal probability of toothache)
28
Inference by enumeration
Start with the joint probability distribution:
For any proposition φ, sum the atomic events where it
is true: P(φ) = Σω:ω╞φ P(ω)
P(cavity toothache) = 0.108 + 0.012 + 0.072 + 0.008 + 0.016 + 0.064 = 0.28
29
Inference by enumeration
Start with the joint probability distribution:
Can also compute conditional probabilities:
product
rule
30
Normalization
Denominator can be viewed as a normalization
constant α
General idea: compute distribution on query variable
by fixing evidence variables and summing over hidden
variables
31
Hidden Variables
HMM
Inference by enumeration, contd.
Let X be all the variables. Typically, we are interested in
the posterior joint distribution of the query variables Y
given specific values e for the evidence variables E
Let the hidden variables be H = X - Y – E
Then the required summation of joint entries is done by
summing out the hidden variables:
P(Y | E = e) = αP(Y, E = e) = αΣhP(Y, E= e, H = h)
The terms in the summation are joint entries because Y,
E and H together exhaust the set of random variables
Obvious problems:
1. Worst-case time complexity O(dn) where d is the largest arity
2. Space complexity O(dn) to store the joint distribution
3. How to find the numbers for O(dn) entries?
34
Independence
Let’s add Weather to the above joint
distribution (it has 4 values, sunny, rain…)
The full table has 32 entries (4 x 8),
basically 4 versions of the above table,
one for each kind of weather
But toothaches don’t affect the weather…
35
Independence
A and B are independent iff
P(A|B) = P(A) or P(B|A) = P(B) or P(A, B) = P(A) P(B)
P(Toothache, Catch, Cavity, Weather)
= P(Toothache, Catch, Cavity) P(Weather)
32 entries reduced to 12; for n independent biased coins,
2n → n (a factored representation)
Absolute independence powerful but rare
Dentistry is a large field with hundreds of variables, none of
which are independent. What to do?
36
Conditional independence
P(Toothache, Cavity, Catch) has 23 - 1 = 7
independent entries
If I have a cavity, the probability that the probe catches
in it doesn’t depend on whether I have a toothache:
(1) P(catch | toothache, cavity) = P(catch | cavity)
The same independence holds if I haven’t got a cavity:
(2) P(catch | toothache, cavity) = P(catch | cavity)
Catch is conditionally independent of Toothache given
Cavity:
P(Catch | Toothache,Cavity) = P(Catch | Cavity)
Equivalent statements:
P(Toothache | Catch, Cavity) = P(Toothache | Cavity)
P(Toothache, Catch | Cavity) = P(Toothache | Cavity) P(Catch | Cavity)
37
Conditional independence contd.
Write out full joint distribution using chain rule:
P(Toothache, Catch, Cavity)
= P(Toothache | Catch, Cavity) P(Catch, Cavity)
= P(Toothache | Catch, Cavity) P(Catch | Cavity) P(Cavity)
= P(Toothache | Cavity) P(Catch | Cavity) P(Cavity)
The original table had 7 independent numbers (since they
sum to 1, the eighth number is not independent); this way,
we have, 2 + 2 + 1 = 5 independent numbers
(2 x (21 – 1) for each conditional probability distribution,
and 1 for the prior on Cavity)
In most cases, the use of conditional independence
reduces the size of the representation of the joint
distribution from exponential in n to linear in n
Conditional independence is our most basic and robust
form of knowledge about uncertain environments
38
Conditional Independence
Conditional independence assertions can
allow probabilistic systems to scale up
They are also much more commonly
available than absolute independence
assertions
39
Bayes’ Rule
Product rule P(ab) = P(a | b) P(b) = P(b | a) P(a)
Bayes’ rule: P(a | b) = P(b | a) P(a) / P(b)
or in distribution form
P(Y|X) = P(X|Y) P(Y) / P(X) = αP(X|Y) P(Y)
Useful for assessing diagnostic probability from
causal probability:
P(Cause|Effect) = P(Effect|Cause) P(Cause) / P(Effect)
E.g., let M be meningitis, S be stiff neck:
P(m|s) = P(s|m) P(m) / P(s) = 0.8 × 0.0001 / 0.1 = 0.0008
Note: posterior probability of meningitis still very small!
40
Bayesian Statistics
We want to calculate the probability of the data Y given
the model parameters a:
p(Y|a).
Or the parameters distribution given the data: p(a|Y).
Likelihood: P(Y|a) = P(a,Y)/P(a)
Prior: P(a)
Posterior: P(a|Y)
This can be repeated iteratively .
Bayesian Statistics
Problem:
P(a|Y) = P(a,Y)/P(Y)
P(Y )
p(a) p(Y | a)da
It is hard to calculate the integral.
Integration
Markov Chain Monte Carlo
Markov Chain Monte Carlo
Maximum Aposteriori (MAP)
Vs.
Maximum Likelihood (ML)
Bayes’ Rule and conditional
independence
P(Cavity | toothache catch)
= αP(toothache catch | Cavity) P(Cavity)
= αP(toothache | Cavity) P(catch | Cavity) P(Cavity)
This is an example of a naïve Bayes model:
P(Cause,Effect1, … ,Effectn) = P(Cause) πiP(Effecti|Cause)
47
Summary
Probability is a rigorous formalism for
uncertain knowledge
Joint probability distribution specifies
probability of every atomic event
Queries can be answered by summing over
atomic events
For nontrivial domains, we must find a way
to reduce the joint size
Independence and conditional
independence provide the tools
48
Bayesian networks
Chapter 14
Section 1 – 2
Outline
Syntax
Semantics
50
Directed Graphical Models –
Bayesian Networks
Directed Graphical Models –
Bayesian Networks
Undirected Graphical Models –
Markov Random Fields
Bayesian networks
A simple, graphical notation for conditional
independence assertions and hence for compact
specification of full joint distributions
Syntax:
a set of nodes, one per variable
a directed, acyclic graph (link ≈ “directly influences”)
a conditional distribution for each node given its
parents:
P (Xi | Parents (Xi))
In the simplest case, conditional distribution
represented as a conditional probability table
(CPT) giving the distribution over Xi for each
combination of parent values
54
Probability Reminder
P ( A, B )
P ( A)
B
B
P( A | B)
B
P ( A, B )
P( B)
Suppose that A {0,1}
P ( A 1) P ( A 0) 1
P( A 1 | C ) P( A 0 | C )
C
C
C
P(A 1, C)
P(C)
C
P(A 0, C)
C
1
Example
Topology of network encodes conditional
independence assertions:
Weather is independent of the other variables
Toothache and Catch are conditionally
independent given Cavity
56
Example
I’m at work, neighbor John calls to say my alarm
is ringing, but neighbor Mary doesn’t call.
Sometimes it’s set off by minor earthquakes. Is
there a burglar?
Variables: Burglar, Earthquake, Alarm,
JohnCalls, MaryCalls
Network topology reflects “causal” knowledge:
A burglar can set the alarm off
An earthquake can set the alarm off
The alarm can cause Mary to call
The alarm can cause John to call
57
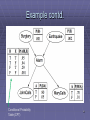
Example contd.
Conditional Probability
Table (CPT)
58
Compactness
A CPT for Boolean Xi with k Boolean
parents has 2k rows for the combinations
of parent values
Each row requires one number p for
Xi = true (the number for Xi = false is just 1-p)
If each variable has no more than k parents, the
complete network requires O(n · 2k) numbers
I.e., grows linearly with n, vs. O(2n) for the full joint
distribution
For burglary net, 1 + 1 + 4 + 2 + 2 = 10 numbers
(vs. 25-1 = 31)
59
Global Semantics
Global semantics defines the full joint distribution
as the product of the local conditional
distributions:
Every entry in the full joint probability distribution can be calculated from
the information in a Bayesian network.
60
Local (Topological) Semantics
Local semantics: each node is conditionally
independent of its nondescendants given its parents
Theorem: Local semantics global semantics
61
Markov Blanket
Each node is conditionally independent of all
others given its Markov blanket: parents + children
+ children’s parents
(Another, equivalent, topological characterization
of local semantics)
62
Constructing Bayesian networks
Need a method such that a series of locally testable
assertions of conditional independence guarantees
the required global semantics
1.Choose an ordering of variables X1, … ,Xn
2.For i = 1 to n
add Xi to the network
select parents from X1, … ,Xi-1 such that
P(Xi | Parents(Xi)) = P(Xi | X1, ... Xi-1)
This choice of parents guarantees the global
semantics:
P(X1, … ,Xn) = πi =1 P(Xi | X1, … , Xi-1) (chain rule)
= πi =1P(Xi | Parents(Xi)) (by construction)
63
Example of Bad Ordering
Suppose we choose the ordering M, J, A, B, E
P(J | M) = P(J)? If Mary calls, that probably means the
alarm has gone off, which makes it more likely that John
calls…
64
Example
Suppose we choose the ordering M, J, A, B, E
P(J | M) = P(J)? No
P(A | J, M) = P(A | J)? P(A | J, M) = P(A)? If both Mary and
John call, it is more likely that the alarm has gone off
than if just one or neither call, so we need both as
parents.
65
Example
Suppose we choose the ordering M, J, A, B, E
P(J | M) = P(J)? No
P(A | J, M) = P(A | J)? P(A | J, M) = P(A)? No
P(B | A, J, M) = P(B | A)?
P(B | A, J, M) = P(B)?
If we know the alarm state, then the call from John or Mary
66
wouldn’t give us information about burglary
Example
Suppose we choose the ordering M, J, A, B, E
P(J | M) = P(J)? No
P(A | J, M) = P(A | J)? P(A | J, M) = P(A)? No
P(B | A, J, M) = P(B | A)? Yes
P(B | A, J, M) = P(B)? No
P(E | B, A ,J, M) = P(E | A)?
P(E | B, A, J, M) = P(E | A, B)? If the alarm is on, it’s more likely there’s
67
been an earthquake, but a burglary would also explain the
alarm…so we need both as parents
Example
Suppose we choose the ordering M, J, A, B, E
P(J | M) = P(J)? No
P(A | J, M) = P(A | J)? P(A | J, M) = P(A)? No
P(B | A, J, M) = P(B | A)? Yes
P(B | A, J, M) = P(B)? No
P(E | B, A ,J, M) = P(E | A)? No
P(E | B, A, J, M) = P(E | A, B)? Yes
68
Example contd.
Deciding conditional independence is hard in noncausal
directions
(Causal models and conditional independence seem
hardwired for humans!)
Assessing conditional probabilities is hard in noncausal
directions
Network is less compact: 1 + 2 + 4 + 2 + 4 = 13 numbers
needed
69
Example: Car Diagnosis
Initial evidence: car won’t start
Testable variables (green); “broken, so fix it” variables
(orange)
Hidden variables (gray) ensure sparse structure, reduce
parameters
70
Example: Car Insurance
71
Summary
Bayesian networks provide a natural
representation for (causally induced)
conditional independence
Topology + CPTs = compact
representation of joint distribution
Generally easy for (non)experts to
construct
72